Современные технологии генерации видео переживают стремительный рост благодаря развитию диффузионных моделей, позволяющих создавать реалистичный и детализированный видеоконтент. Однако масштабирование этих систем на длинные видеопоследовательности сталкивается с серьезными вызовами, главным из которых является высокая вычислительная сложность механизмов внимания. Классический механизм self-attention обладает квадратичной сложностью по длине последовательности, что приводит к неэффективности и чрезмерным затратам ресурсов при работе с длительными видео. В ответ на эти ограничения команда исследователей из MIT HAN Lab предложила концепцию Radial Attention — уникальный подход к реализации механизма внимания с вычислительной сложностью O(nlogn), который позволяет существенно сократить расходы на вычисления без ущерба для качества видео. Эта технология особенно актуальна в условиях растущего спроса на более длинные и сложные видеоформаты, которые используют как крупные исследовательские учреждения, так и коммерческие компании, работающие в сфере искусственного интеллекта.
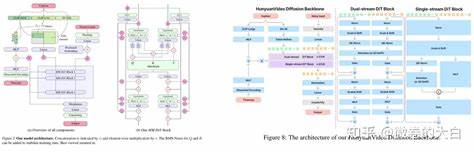
Идея Radial Attention основана на природном явлении, известном как спатиотемпоральное затухание энергии. В физическом мире энергия сигналов и волн плавно убывает со временем и расстоянием. Аналогично в процессах диффузного моделирования видео наблюдается схожая закономерность — по мере увеличения временного и пространственного расстояния между токенами внимание становится менее значимым. Эта особенность позволила авторам разработать метод, который придает вычислительной мощности четкую структурированную форму, сосредотачиваясь на наиболее важных взаимодействиях. Реализация Radial Attention базируется на статической, заранее определенной маске внимания, где каждый токен взаимодействует преимущественно с соседними элементами по пространству, а размер области внимания сжимается с увеличением временной дистанции.
Такой динамический адаптивный подход обеспечивает сбалансированное распределение ресурсов — интенсивное внимание уделяется близким в пространстве токенам и постепенно уменьшается для объектов, удаленных во времени. По временной оси применяется экспоненциальное правило убывания плотности вычислений. Вычислительная нагрузка распределяется по несколько расширяющимся диагональным полосам, каждая из которых имеет в два раза большую ширину, чем предыдущая. Это гарантирует ограничение общего объема операций в каждой полосе и, следовательно, поддержку масштабируемости при увеличении длины видео. Кроме того, принцип светится и на пространственном измерении, где для пары кадров ширина звена внимания уменьшается по мере удаления во времени, концентрируя вычисления на локальных, но важных для восприятия сходства.
Такая локализация внимания помогает сохранить высокую точность в построении сложных и связных видеообразов. Для оптимальной работы на современном аппаратном обеспечении Radial Attention реализован с использованием блочной разреженности. Вычисления проводятся не на уровне отдельных токенов, а на блоках размером 128×128, что обеспечивает лучшее распределение вычислительных процессов и использование параллелизма, характерного для графических процессоров и специализированных ускорителей. Помимо повышения эффективности, Radial Attention демонстрирует впечатляющие возможности в адаптации к удлинению генерируемых видео. Благодаря сохранению исходной структуры softmax внимания, предобученные веса остаются применимыми, что значительно снижает потребность в ресурсозатратной дообучении.
В числах это выражается в снижении времени и памяти, необходимых для перенастройки модели на длинный контент. Для максимальной экономии ресурсов команда внедрила Low-Rank Adaptation (LoRA) в ключевые проекции внимания. LoRA позволяет сохранять и обновлять лишь наиболее существенные параметры модели, существенно сокращая объем вычислений и улучшая качество итогового видео за счет более фокусированной настройки. Так, сочетание Radial Attention и LoRA стало эффективным инструментом для расширения возможностей генерации видео без значительных компромиссов. Экспериментальные результаты подтверждают расслабленный характер Radial Attention.
При генерации 500-кадрового видео формата 720p в рамках платформы HunyuanVideo наблюдается сокращение вычислительных затрат на внимание примерно в 9 раз, что обеспечивает прирост скорости работы модели примерно в 3.7 раза и уменьшение затрат на настройку почти в 4.6 раза. Такое достижение открывает новые горизонты для создания масштабных видеопродуктов с высокой детализацией и продолжительностью. Особенно интересно отметить, что Radial Attention позволяет ускорять предобученные модели, сохраняя качество создаваемого контента.
При генерации стандартных по длине видеороликов уровень качества остается сопоставимым с эталонными методами, а время генерации сокращается почти вдвое. При производстве видео в четыре раза длиннее экономия ресурсов становится еще более ощутимой — настройка происходит в 4.4 раза быстрее, а вывод достигает ускорения в 3.7 раза. Одним из ключевых преимуществ технологии является ее интеграция с существующими LoRA-моделями.
Например, применение Radial Attention к 8-шаговой FusionX LoRA приводит к дополнительному ускорению в 1.6 раза, благодаря чему рендеринг видеоролика длительностью 4 секунды в 720p происходит всего за 84 секунды на современном графическом процессоре H100. Эта совместимость повышает гибкость использования инструмента, позволяя комбинировать LoRA-настройки для удлинения видео с существующими стилистическими адаптациями, сохраняя при этом визуальное качество и расширяя творческие возможности пользователей. Radial Attention представляет собой важный шаг вперед в области разработки эффективных и масштабируемых моделей генерации видео. За счет глубокой интеграции принципов физического затухания энергии и продуманного структурирования внимания он снижает вычислительную нагрузку с квадратичной до почти логарифмической, что становится критически важным для работы с длинными временными рядами в видеофрагментах.








![Twinkling lights and nested loops: distributed problem solving and spreadsheets [pdf]](/images/D70520BE-8298-4F88-BB62-E013AC3B87BA)