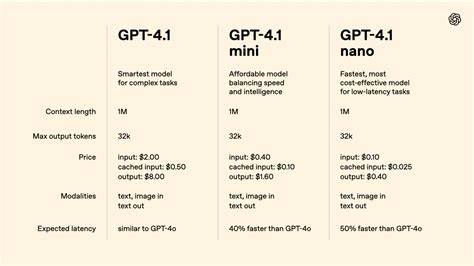
В последние годы искусственный интеллект стремительно развивается, всё глубже проникая в самые разные сферы нашей жизни — от обработки естественного языка до игровых стратегий. Одним из ярких представителей современного ИИ являются большие языковые модели, такие как GPT-4. В то же время, растёт интерес к тому, насколько облегчённые версии таких моделей могут успешно конкурировать с полноценными версиями в задачах, требующих стратегического мышления и адаптивности. Недавний проект, где GPT-4.1-mini благодаря инновационной технологии динамического контекста смог добиться превосходства над «старшим братом» GPT-4.
1 в игре Крестики-Нолики, привлёк внимание специалистов и энтузиастов. Именно этой теме посвящено наше подробное исследование. Игра Крестики-Нолики сама по себе является классической задачей, которую часто используют в качестве тестирования алгоритмов искусственного интеллекта. Это относительно простая игра с небольшим числом состояний, которая при этом демонстрирует важные элементы тактики и стратегии. Прекрасной особенностью её является возможность быстро получать обратную связь — какой ход выиграл, где была допущена ошибка, и как можно исправить стратегию.
Однако, несмотря на видимую простоту, эта игра идеально подходит для глубинного анализа модели и её способности к обучению на примерах. В рамках проекта была реализована система турниров между различными версиями ИИ, которые состязались друг с другом, демонстрируя разные подходы к обучению и принятию решений. Использовалась платформа Opper, предоставляющая мощный набор инструментов для создания, управления и анализа моделей. Среди многих стратегий выделялись несколько ключевых: нулевой шот (zero-shot), при котором модели дают играть без примеров; обучение с несколькими примерами (few-shot), подразумевающее подачу нескольких образцов; а также стратегическая цепочка рассуждений, где модели объясняют свои ходы. Ключевым элементом эксперимента стала технология динамического контекста — способность модели на лету дополнять своё понимание игры, запоминая и переиспользуя победные ходы, полученные в процессе турнира.
Таким образом, каждая выигрышная позиция добавлялась в базу примеров, что постепенно улучшало качество модели в режиме реального времени. Интересно, что после нескольких раундов, облегчённая версия GPT-4.1-mini начала заметно превосходить более крупную GPT-4.1. Это противоречило традиционному представлению о том, что большая модель обязательно сильнее в тактических задачах.
Результаты учитывали не только выигрыш, но и количество ничьих и незаконных ходов, что позволило объективно оценить истинный уровень мастерства каждой версии. Важным преимуществом платформы Opper стала её интеграция с асинхронными вызовами, что существенно ускоряло проведение большого числа матчей одновременно. Проект доказывает, что качественно организованное few-shot обучение и динамическое использование контекста способны обеспечить эффективное компактное решение, обходя по некоторым показателям модели с большим количеством параметров. Помимо сугубо исследовательской ценности, данный опыт открывает возможности для разработки легковесных интеллектуальных агентов, которые могут функционировать на устройствах с ограниченными ресурсами. Это актуально для мобильных приложений, интерактивных развлечений и образовательных платформ, где важно сочетать быстрое реагирование и высокий интеллект.
Еще одним интересным аспектом стало экспериментальное исследование эффекта первого хода и справедливости соперничества. Анализируя сотни игр, удалось выявить статистическую склонность к преимуществу игрока, делающего первый ход, что характерно для многих подобных игр. Это позволяет создавать более сбалансированные сценарии и улучшать алгоритмы оценки стратегий. Судя по отзывам экспертов, данный проект демонстрирует потенциал сочетания глубокой интеграции и автоматизации обучения с пользовательской настройкой моделей. Опенсорсный характер репозитория с подробной документацией и модульной структурой позволяет широкой аудитории исследователей и разработчиков адаптировать систему под собственные нужды.
В будущем подобные механизмы могут стать основой для создания обучающихся агентов в более сложных играх и задачах — от шахмат до стратегий реального времени. Применение динамического контекста накопит опыт взаимодействия с окружающей средой, повышая адаптивность и качество решений без необходимости массивных переобучений. Таким образом, кейс с GPT-4.1-mini и использованием динамического контекста в Крестиках-Ноликах стал ярким примером того, как инновационный подход к обучению и игре может изменить представление о возможностях ИИ, делая компактные модели более эффективными, чем более громоздкие аналоги. Постоянное автоматическое добавление новых примеров, простота управления через платформу Opper и поддержка асинхронных вызовов создают уникальные возможности для проведения масштабных экспериментов, анализа и совершенствования моделей.
Безусловно, это один из важных шагов на пути к более умным, адаптивным и экономичным решениям в мире искусственного интеллекта.







