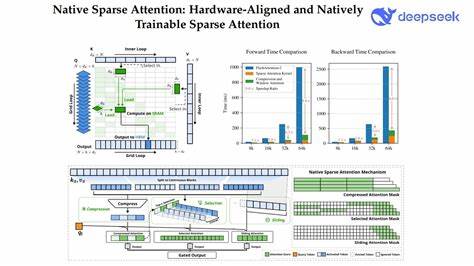
В последние годы языковые модели с механизмом внимания значительно продвинулись в задачах обработки текста, особенно когда речь заходит о понимании контекстов большой длины. Традиционные модели с полным вниманием (Full Attention) сталкиваются с серьёзными вычислительными ограничениями, так как объём их работы растет квадратично с увеличением длины последовательности. Это создаёт преграды для использования таких моделей в реальных условиях, особенно при обработке длинных документов, больших диалогов и сложных задач генерации текста. Нативное разреженное внимание (Native Sparse Attention, NSA) представляет собой инновационный подход, который кардинально меняет парадигму обработки длинных контекстов. NSA сочетает в себе интеллектуальную алгоритмическую структуру и непосредственную оптимизацию под современные аппаратные средства, что позволяет выполнять вычисления максимально эффективно и быстро без ущерба для качества результатов.
Главная идея NSA заключается в использовании иерархической стратегии разреженного внимания. Эта стратегия объединяет грубую компрессию токенов с тонким отбором ключевых элементов, сохраняя глобальное понимание текста и локальную точность в обработке информации. Такой подход помогает фокусироваться на наиболее значимых частях входных данных, исключая излишнюю переработку менее важного контента. Одним из ключевых преимуществ NSA является балансировка арифметической интенсивности — этот технический термин отражает оптимальное соотношение вычислительной нагрузки и доступа к памяти. Благодаря этому NSA добивается впечатляющего прироста скорости вычислений на современных вычислительных платформах, включая графические процессоры и специализированные ускорители машинного обучения.
Кроме аппаратных оптимизаций, NSA поддерживает полноценное сквозное обучение, что значительно упрощает использование разреженного внимания на практике. При этом сокращается время и ресурсы, затрачиваемые на предварительное обучение модели, без потерь в точности и способности к решению сложных задач. Это особенно важно для специалистов и разработчиков, стремящихся к быстрому экспериментированию и внедрению новых моделей без необходимости длительных этапов подстройки. В ходе испытаний NSA продемонстрировал не только сохранение уровня производительности, характерного для моделей с полным вниманием, но и превосходство в ряде тестов, включая общие бенчмарки, задачи с долгими контекстами и сценарии, требующие сложного понимания инструкций и рассуждений. Особенно впечатляет эффективность NSA при работе с последовательностями длиной до 64 тысяч токенов, где традиционные модели часто оказываются бессильны или крайне медленны.
Поддержка ускорения при декодировании, прямом и обратном распространении ошибок обеспечивает NSA удобство использования на всех этапах жизненного цикла модели — от обучения до реального применения. В совокупности это снижает затраты на вычисления и энергопотребление, что становится важным фактором для крупных организаций и исследовательских проектов, ориентированных на устойчивое развитие и экологичность технологий. Успех NSA подтверждён не только экспериментальными результатами, но и признанием в академическом сообществе. В 2025 году работа, посвящённая этому механизму, была опубликована в материалах 63-й ежегодной конференции Ассоциации вычислительной лингвистики (ACL), где получила высокую оценку и признание как одна из лучших в своей области. Перспективы использования Native Sparse Attention открывают большой потенциал в различных сферах, требующих обработки больших объемов последовательных данных.
Это может быть генерация сложных текстов, анализ больших документов, научные исследования, автоматический перевод, а также задачи в области искусственного интеллекта, связанные с пониманием и генерацией естественного языка. Разработчики и исследователи, заинтересованные в эффективности и масштабируемости моделей, найдут в NSA мощный инструмент для оптимизации своих систем. Комбинация теоретических инноваций с практическими аппаратными улучшениями позволяет добиться значительных улучшений в скорости и качестве, что в конечном итоге расширяет границы возможного в области обработки естественного языка. В будущем использование нативного разреженного внимания способно изменить подход к проектированию языковых моделей, сделав их более доступными, быстрыми и функциональными. Такой сдвиг позволит решениям на базе искусственного интеллекта проще справляться с реальными задачами, требующими анализа длинных, сложных потоков данных, что найдет широкое применение во многих высокотехнологичных индустриях.
Native Sparse Attention — это не просто техническое усовершенствование, это фундаментальный шаг вперёд в эпоху больших языковых моделей, меняющий наше представление о том, как эффективно использовать вычислительные ресурсы, сохраняя при этом высокие стандарты качества и точности в понимании человеческого языка.

![Tesla owes small businesses millions in unpaid bills [video]](/images/DA965477-E19B-4288-AF81-1045299B2FEC)




