В современном мире искусственного интеллекта и обработки естественного языка эмбеддинги выступают в роли ключевого компонента систем, обеспечивающих качественный семантический поиск, память моделей и технологии retrieval-augmented generation (RAG). От правильного выбора модели эмбеддингов во многом зависит релевантность поиска, быстродействие и итоговая эффективность интеллектуальных приложений. На сегодняшний день открытые модели становятся все более востребованными благодаря свободному доступу, гибкости в настройках и отсутствию ограничений, связанных с закрытыми API. Однако в условиях широкого ассортимента моделей понять, какая именно подойдет для конкретной задачи, не так просто. Для оптимального выбора требуется глубокое понимание преимуществ, потенциала и ограничений каждой архитектуры, а также оценка их эффективности в реальном окружении.
В этом контексте проведено комплексное тестирование четырех популярных открытых моделей эмбеддингов — BAAI/bge-base-en-v1.5, intfloat/e5-base-v2, nomic-ai/nomic-embed-text-v1 и sentence-transformers/all-MiniLM-L6-v2. Каждая из них демонстрирует уникальные качества и ориентирована на разные сценарии использования. Первая оценка моделей была проведена с использованием набора данных BEIR TREC-COVID, который служит стандартом для оценки систем информационного поиска в медицинской области. Этот корпус содержит тематические запросы и соответствующие релевантные документы, что позволяет воссоздать условия, близкие к реальным задачам поисковых систем, основанных на RAG-подходе и долговременной памяти.
Модель BAAI/bge-base-en-v1.5 построена на базе архитектуры BERT и представляет современное решение, прошедшее тонкую настройку с использованием контрастивного обучения и методов hard negative mining. Она способна эффективно делать запросы и документы сопоставимыми в одном векторном пространстве, что крайне важно для высокого качества поиска с использованием FAISS-индексации. Основным преимуществом является высокая точность и гибкость в тонкой настройке, включая использование специальных префиксов для управления встроенными инструкциями. Однако модель требует дополнительной подготовки данных и может испытывать сложности с многоязычными или шумными входными данными.
Несмотря на это, она широко используется как в научных, так и в производственных системах. Вторая модель, intfloat/e5-base-v2, представляет собой RoBERTa-основанную архитектуру с ди_ENCODERом и была обучена по методологии E5 со ставкой на текстовые пары. За счет обширного тренировочного набора данных, включающего пары с разнообразных источников, таких как Reddit, Wikipedia и научные публикации, она демонстрирует хорошую сбалансированность по точности и скорости. Среди достоинств — отсутствие необходимости в особых префиксах и универсальность применения, что облегчает интеграцию в разнообразные системы поиска. Тем не менее, модель требует тщательной работы с ограничением максимальной длины токенов, а в некоторых случаях её производительность может уступать более крупным решениям.
Третья модель, nomic-ai/nomic-embed-text-v1, отличается использованием GPT-подобной архитектуры, ориентированной на масштабируемость и поддержку длинных мультиязычных входов — до 8192 токенов. Её тренировка прошла в несколько этапов с применением обширных данных, что позволяет модели эффективно работать с разнородными источниками информации и создать прочные семантические представления. Благодаря этому nomic-embed-text-v1 идеально подходит для крупных проектов с высокими требованиями к обобщению и точности, например, для юридических или медицинских баз. Вместе с тем, ресурсоемкость и увеличенное время эмбеддинга делают её менее подходящей для задач, где важна оперативность и малое потребление ресурсов. Четвертая, sentence-transformers/all-MiniLM-L6-v2, представляет собой компактную и быструю MiniLM-модель с небольшим количеством параметров, что обеспечивает превосходное сочетание быстродействия и экономии ресурсов.
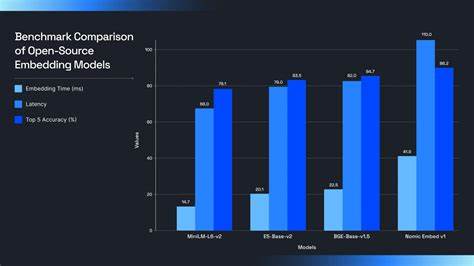
Она является фаворитом в задачах, где важна скорость и масштабируемость, например, для поддержки миллионов запросов в чат-ботах или API с высокой нагрузкой. Однако в сравнении с более крупными моделями она уступает по точности, особенно при работе с длинными или шумными текстами. Оптимальным вариантом использования станет ситуациях с короткими входными строками и потребностью в мгновенной реакции. Результаты сравнительных тестов подтверждают, что не существует универсального решения. MiniLM-L6-v2 превосходит по скорости эмбеддинга — 14,7 мс на 1000 токенов, и имеет низкие задержки при обработке запросов, что критично для интерактивных и пользовательских сервисов.
Зато точность её поиска на порядок ниже лидеров рейтинга. Модели E5-base-v2 и BGE-base-v1.5 занимают золотую середину с хорошей точностью, превышающей 83%, и умеренной задержкой, что делает эти модели отличным выбором для сбалансированных систем. В свою очередь nomic-embed-text-v1 лидирует по точности — 86,2% топ-5, что очень важно в областях с высокими требованиями к релевантности; но этот результат достигается за счет заметного увеличения времени обработки и ресурсов. При выборе модели эмбеддингов очень важно учитывать не только точность и скорость, но и соотношение этих параметров с доступными вычислительными ресурсами.
MiniLM выделяется минимальным потреблением памяти (около 1,2 ГБ) и подходит для запуска на периферийных устройствах. Модели E5 и BGE требуют около 2 ГБ памяти и предлагают приемлемые показатели как для серверных, так и для более мощных локальных сред. В то же время nomic-embed-text-v1 нуждается в значительных вычислительных ресурсах с потреблением до 4,8 ГБ памяти, что накладывает ограничения на использование в условиях ограниченного оборудования. Внедрение выбранной модели будет зависеть от специфики проекта. Если важна скорость отклика и возможности масштабирования, предпочтение стоит отдать MiniLM.
Для проектов, нацеленных на более глубокий анализ и поиск с высокой точностью, лучше рассмотреть BGE или E5, уделяя внимание тонкой настройке и обработке текстовых данных. А если критична точность и обработка больших объемов сложных текстов, номинально лучшая модель nomic-embed-text-v1 станет оптимальным решением, несмотря на более высокие вычислительные затраты. На фоне быстрого развития открытых моделей эмбеддингов появляются инструменты, упрощающие их интеграцию и масштабирование. Платформы, такие как Supermemory, позволяют максимально эффективно использовать потенциал разных моделей в едином окружении, обеспечивая гибкое управление памятью LLM и автоматизацию операций с различными источниками данных. Это дает уникальные возможности для разработки интеллектуальных систем поиска, личных помощников и экспертных решений, минимизируя затраты на исследование и настройку моделей.
Таким образом, глубинный анализ и реальные тесты подтверждают, что выбор открытой модели эмбеддингов — это взвешенный компромисс между точностью, скоростью и требуемыми ресурсами. Учитывая эти факторы, разработчики могут подобрать технологию, максимально подходящую под задачи своего продукта, тем самым повышая качество взаимодействия пользователей с AI, его оперативность и экономическую эффективность. В эпоху, когда большие данные и AI-технологии становятся краеугольным камнем множества отраслей, понимание нюансов работы и возможностей современных моделей эмбеддингов открывает путь к созданию действительно умных и адаптивных приложений будущего.