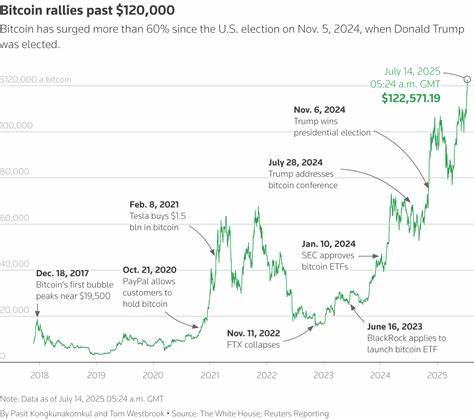
В эпоху стремительного развития технологий и взрывного роста объёмов данных компании сталкиваются с необходимостью объединять возможности транзакционных баз данных и аналитических платформ для комплексной работы с информацией. TigerData — команда, стоящая за популярными решениями TimescaleDB и Tiger Postgres, — сделала значительный шаг вперёд, выпустив Tiger Lake, архитектурный слой, призванный устранить существующие границы между оперативной обработкой данных и анализом на основе открытых Lakehouse. Этот прорыв открывает новые горизонты для разработчиков, предоставляя возможности построения приложений нового поколения, которые одновременно работают с потоками данных в реальном времени и глубокой исторической аналитикой. Прежде чем погрузиться в особенности Tiger Lake, стоит понять проблему, которую он призван решить. Традиционно системы управления базами данных разделялись на две большие категории: операционные базы данных (OLTP), обеспечивающие высокую скорость транзакций и актуальность данных, и аналитические платформы (OLAP), оптимизированные для глубокого анализа и работы с историческими данными.
Postgres — один из лидеров среди операционных баз данных, известный своей надёжностью и гибкостью. Противопоставляется же ему модель «lakehouse», которая сочетает возможности озёр данных (data lakes) и хранилищ данных (data warehouses), используя открытые форматы, такие как Apache Iceberg, для организации больших объёмов информации с высокой степенью масштабируемости. Однако до недавнего времени работать с этими двумя мирами одновременно было сложно из-за необходимости создавать сложные и ненадёжные конвейеры ETL, синхронизирующие данные. Tiger Lake меняет эту парадигму, превращая Tiger Postgres в операционное ядро открытого Lakehouse. Благодаря прямой и двунаправленной интеграции Postgres с Iceberg-озёрными хранилищами, Tiger Lake устраняет необходимость в промежуточных слоях и ручных скриптах для переноса и преобразования данных.
Это позволяет обеспечить постоянный обмен информацией между системами в режиме реального времени, что крайне важно для приложений с высокими требованиями к актуальности данных и аналитическим выводам. Новая архитектура открывает перед разработчиками возможности не идти на компромиссы между скоростью и масштабом. Это значит, что высокопроизводительные транзакции с данными, характерные для Postgres, могут сосуществовать с глубинным анализом, выполняемым в Lakehouse, без ущерба для стабильности или производительности. Например, можно легко перенести любую таблицу из Postgres прямо в lakehouse, минуя традиционные сложные конвейеры обработки. Tiger Postgres остаётся хранилищем первичных данных и поддерживает потоковое внесение изменений (streaming ingestion),实时-преобразования и агрегации данных.
Результаты аналитики — такие как инструменты машинного обучения, агрегированные метрики или исторические выборки — могут быть эффективно возвращены обратно в Postgres, что позволяет приложениям получать доступ к ценным аналитическим данным непосредственно в режиме реального времени. Одним из ключевых преимуществ Tiger Lake является упрощение инфраструктуры, устраняющей необходимость работы со множеством отдельных инструментов, таких как Kafka, Flink и кастомные скрипты, которые традиционно использовались для интеграции Postgres и Iceberg. Отказ от таких сложных и хрупких систем снижает нагрузку на инженерные команды, улучшает надёжность и облегчает поддержку приложений. Компания Speedcast уже внедрила Tiger Lake в продакшен, отметив значительное упрощение разработки и сопровождения систем обработки данных. Их технический директор подчеркнул, что новая система стала архитектурным решением, которого не хватало с самого начала, позволив избавиться от дорогостоящих интеграционных узлов и обеспечить масштабируемость без потери в производительности.
Tiger Lake строится на принципах открытости и модульности. В отличие от многих проприетарных решений, которые пытаются навязать пользователю замкнутый стек, Tiger Lake сохраняет свободу выбора в использовании различных компонентов инфраструктуры. Благодаря поддержке открытых форматов данных и совместимости с такими платформами, как AWS S3 или Snowflake, разработчики получают гибкость строить системы на базе проверенных и надёжных технологий без опасений «запертости» в одном вендоре. На данный момент Tiger Lake доступен в публичной бета-версии через платформу Tiger Cloud. Первоначальная версия сосредоточилась на потоковой синхронизации данных из Postgres и TimescaleDB в AWS S3 с форматом Iceberg, а также на возможности обратно синхронизировать данные из S3 в Postgres.
В планах развития значится добавление возможности интегрированного запроса Iceberg-каталогов прямо из Postgres и поддержка круглых рабочих процессов, когда аналитические результаты легко возвращаются для использования в операционном режиме. Одним из важных аспектов является фокус на задачах с реальным временем. TigerData оптимизировала Tiger Postgres для аналитики временных рядов, а также для задач с агентным поведением, что открывает перспективы для создания интеллектуальных систем, способных мгновенно реагировать на изменения контекста и собирать инсайты из больших исторических данных. Это особенно ценно для отраслей с требованием к оперативному принятию решений, как финансы, телекоммуникации, IOT и многое другое. В итоге Tiger Lake становится фундаментом для архитектуры будущего, где границы между транзакционной обработкой и аналитическим хранением размыты, позволяя создавать более эффективные, масштабируемые и устойчивые системы.