В современном мире искусственный интеллект становится неотъемлемой частью самых разных процессов — от автоматизации рутинных задач до поддержки принятия сложных технических решений. Особенно в сфере управления инфраструктурой и программным обеспечением наблюдается активное внедрение интеллектуальных агентов, которые берут на себя часть ответственности за обновления, диагностику и обслуживание систем. Однако успешность таких агентов напрямую зависит от того, какой контекст им предоставляется для выполнения заданий. Несмотря на желание разработчиков использовать максимально большой объем данных для обеспечения полноты информации, практика показывает: большее количество информации не всегда приводит к лучшим результатам. Важно предоставлять минимальный, но максимально релевантный контекст — и именно в тот момент, когда он необходим.
Такой подход способен существенно повысить производительность ИИ агентов, снизить затраты на обработку данных и снизить риски ошибок. Контекстная инженерия — основа эффективного взаимодействия с ИИ Контекстная инженерия представляет собой искусство и науку правильного выбора и структурирования тех фактов, инструкций и инструментов, которые нужны языковой модели для успешного завершения поставленной задачи. Это не просто вопрос количества данных, а вопрос их качества и своевременности подачи. Большие контекстные окна, которые позволили бы «накидать» большие объемы логов, документации, конфигураций, кажутся заманчивыми, но в реальности они часто становятся источником проблем. Модели лишь тратят ресурсы на «шум» — устаревшие или не относящиеся к делу данные, которые замедляют процесс анализа и увеличивают стоимость запросов.
В чём же секрет успеха? Опыт компании Chkk и аналогичных технологических игроков показывает, что точечная и четко выверенная подача минимального релевантного контекста (Minimal Relevant Context, MRC) оказывается гораздо более эффективной. При таком подходе ИИ агент получает только те сведения, которые непосредственно касаются выполняемой операции, при этом вся информация свежая, проверенная и структурированная. Роль контекста в работе агентов и людей: параллели и особенности Человеческий мозг и агентные системы во многом похожи в отношении обработки информации. Представьте, что вы доверяете своему высококвалифицированному коллеге проект с четкими и понятными инструкциями. Такой сотрудник начинает действовать быстро и уверенно.
Если же указания звучат размыто, то результат оказывается гораздо хуже. Аналогичным образом и агенты работают лучше, когда получают чистый, сфокусированный контекст. Если же подвергнуть их потоку бесконечных и несовпадающих по смыслу данных, разве это не будет подобно тому, как если бы вы отправили новичку все электронные письма организации за несколько лет? Это не помощь, а перегрузка. Качество контекста всегда коррелирует с качеством результата — будь то сотрудник или ИИ агент. Именно поэтому формирование контекста должно быть продуманным, системным и динамически адаптируемым под текущие задачи.
Практические вызовы при масштабировании контекстной инженерии в инфраструктуре Для инженеров и специалистов по управлению инфраструктурой обработка контекста — одна из самых сложных проблем. Представьте, что речь идет о сотнях сервисов, десятках открытых проектов, множестве систем развертывания и большого массива конфигураций и параметров. Обычный инженер в таких условиях рискует просто потонуть в информации, разбираясь в сотнях файлов и журнальных записей, чтобы понять, какие изменения окажут воздействие на текущую систему. Компания Chkk в этой сфере стала одним из пионеров, создав систему, которая автоматизирует сбор, классификацию и анализ состояния инфраструктуры. Она извлекает только те сведения, которые необходимы именно для конкретного проекта и версии.
Благодаря такому методическому подходу инженеры освобождаются от необходимости вручную исследовать десятки источников и сложные отчеты, а получают готовые, адаптированные под их окружение рекомендации и планы обновлений. Это позволило существенно сократить трудозатраты и минимизировать риски человеческих ошибок при управлении жизненным циклом ПО. Суть процесса сводится к эффективной цепочке действий — сбор, анализ, обоснование и реализация. На каждом этапе важна последовательная фильтрация и упорядочение данных, чтобы к окончательному шагу агент уже имел максимально релевантный и упрощённый набор знаний для принятия решения. Как агентам нужна другая подача контекста Когда подобные системы начали использовать для взаимодействия с интеллектуальными агентами, появилась необходимость адаптировать концепты к их особенностям.
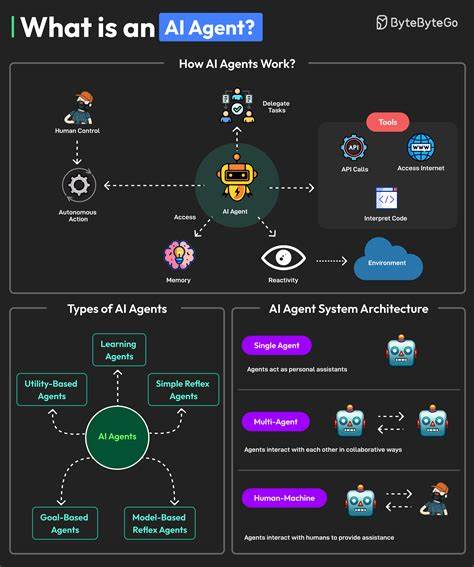
Агенты работают в цикле: они наблюдают ввод пользователя, выбирают нужный инструмент, выполняют действие, анализируют результат и добавляют вывод в контекст. При каждом шаге контекст расширяется, иногда очень быстро, и несмотря на потенциально огромные контекстные окна современных моделей, они всё равно могут быть исчерпаны за несколько итераций. Это приводит к ряду типичных проблем. Если контекст состоит из множества нерелевантных и устаревших данных, модель начинает обращать внимание на все подряд, включая irrelevant сведения, и в результате выдает ложную информацию. Это явление называется галлюцинацией модели — ошибочными суждениями, основанными на шуме в контексте.
Еще одна проблема — «зацикливание». Модель одновременно хранит в памяти историю предыдущих инструментальных вызовов и «якорится» на них, даже если условия изменились. В итоге агент может повторять действия без необходимости, так как зациклен на устаревших данных. При этом дело не в ограничениях токенов, а именно в том, что релевантность информации со временем убывает, и модель теряет способность сосредоточиться на актуальных данных. Также наблюдаются случаи, когда агент начинает сомневаться в своих решениях, переписывая и «перемешивая» мысли, пытаясь компенсировать появившуюся часть нового контекста с устаревшей информацией.
В итоге получаются противоречивые планы и рекомендации, снижающие доверие к ИИ. Преимущества минимального релевантного контекста Всё вышеперечисленное выявляет главную задачу для разработчиков и инженеров — нужно создать систему, которая непрерывно очищает и ранжирует контекст по степени важности для текущей задачи. Такой подход делает контекст «живым контрактом», который изменяется, подстраивается и максимально сужается под конкретные цели и условия использования. Вместо того чтобы просто подсовывать в промпт все данные подряд, формируются срезы, учитывающие специфику окружения, последние изменения и объем, который оптимален для решения задачи. В итоге агент работает быстрее, его ответы становятся более точными и уверенными, снижаются затраты на ресурсы и уменьшается вероятность ошибок и галлюцинаций.
Перспективы развития контекстной инженерии и агентных систем Контекстная инженерия находится в стадии становления, но уже является ключевым элементом современных интеллектуальных систем. С развитием моделей, их производительность и стоимость запросов улучшается, но без правильной организации памяти, тщательного отбора и обновления контекста преимущества будут нивелированы. Компании вроде Chkk продолжают развивать платформы, где минимальный релевантный контекст является краеугольным камнем. Такие решения интегрируют управление инвентарём, нормализацию знаний, детальное отслеживание изменений и грамотное ограничение объема подаваемых данных. Это гарантирует, что интеллектуальный агент всегда получает именно ту информацию, которая нужна для принятия эффективного решения в данный момент.
В конечном итоге эффективность и надежность вашего ИИ агента напрямую зависят от качества контекста, который он получает. Оптимизация подачи минимального релевантного контекста — инвестиция в уверенное и стремительное развитие автоматизации и искусственного интеллекта в вашем бизнесе и инфраструктуре.