В последние годы развитие крупных языковых моделей (LLM) стремительно трансформирует пространство искусственного интеллекта, открывая новые возможности для обработки естественного языка, генерации текста и поддержки диалоговых систем. Одним из наиболее значимых этапов в этой области стала презентация Microsoft BitNet B1.58 2B4T — первой в мире открытой крупномасштабной языковой модели, разработанной с использованием нативной 1-битной точности квантования весов. Этот прорыв позволил добиться отличных результатов при минимальных вычислительных ресурсах, что представляет собой будущее эффективных ИИ-систем. BitNet B1.
58 2B4T — это не просто очередная модель формата 2 миллиарда параметров, а оригинальный подход к обучению и инференсу, который сочетает в себе инновации в архитектуре, оптимизации и квантовании. Она построена на базе трансформеров, но модифицирована с использованием новаторских BitLinear слоёв, позволяющих эффективно кодировать и хранить веса с минимальной предельной битностью — всего 1,58 бита, что существенно снижает плотность хранения и энергозатраты. Ключевая особенность BitNet — это то, что модель не была просто конвертирована из полноточностной версии в квантованную постобработкой. Вместо этого нативное 1-битное квантование было интегрировано с самого начала процесса обучения. Такой подход обеспечивает гармоничное согласование весов и квантующих схем, что подтверждается стабильностью и качеством получаемых ответов.
База для обучения модели — огромный корпус из 4 триллионов токенов, включающий широкий спектр текстов и кода, а также синтетические математические данные. Модель обучалась с помощью продуманной двухэтапной стратегии управления скоростью обучения и коэффициента регуляризации, что позволило ей сохранить баланс между качеством обобщения и стабильностью при обучении. Для повышения удобства диалогового взаимодействия и расширения функциональности BitNet прошла стадию инструкционной дообученности (Supervised Fine-tuning), включающую оптимизацию на наборах данных с человеческими диалогами и инструкциями. Дополнительно была применена методика Direct Preference Optimization — технология, при помощи которой отражаются предпочтения пользователей на основе пар выбора, что улучшает релевантность и качество выдачи. В архитектуре модели использованы современные элементы – Rotary Position Embeddings (RoPE) для эффективного кодирования позиции токенов и активационная функция ReLU во второй степени (ReLU²) в слоях FFN, что способствует улучшению нелинейной обработки информации.
Исчезновение синаптических весов смещений в линейных и нормализационных слоях позволило упростить вычисления и поддержать целостность квантования. Интересна система квантования активаций – они представлены 8-битными числами, при этом веса модели «зашиты» в значения из набора {-1, 0, +1} через особую схему absmean квантования, что помогает снизить ошибки округления и сохранить важные сигналы. Контекстная длина модели достигает 4096 токенов, а для задач с более длинными последовательностями рекомендуется дополнительная адаптация с помощью долгосрочного обучения. BitNet B1.58 2B4T демонстрирует впечатляющие параметры эффективности.
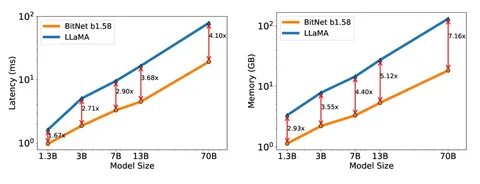
По сравнению с конкурентами того же масштаба, она занимает минимум памяти при инференсе — всего 0.4 ГБ, что несопоставимо меньше, чем у аналогичных моделей в полноточном режиме. Задержка отклика при декодировании на CPU составляет рекордно низкие 29 миллисекунд, а энергопотребление — около 0.028 Джоуля, что значительно превосходит даже другие передовые разработки. Также по ряду бенчмарков BitNet показывает высокие оценки качества, включая ARC Challenge и ARC Easy, BOOLQ, PIQA и GMT8K, часто превосходя более громоздкие модели с обычной точностью.
Это делает её подходящей для широкого спектра задач, связанных с пониманием языка, решением логических и математических вопросов, и многом другом. Несмотря на успехи, BitNet открыто предупреждает о наличии определённых ограничений. Модель может наследовать неравномерные культурные или социальные предубеждения из обучающих данных, а также иметь повышенную ошибочную реакцию на критически важные темы, такие как выборы. Поэтому рекомендовано тщательно проверять ключевые утверждения и использовать модель преимущественно для исследовательских целей, а не для коммерческого внедрения без дополнительной калибровки. Активное сообщество на площадке Hugging Face уже работает над расширением возможностей BitNet, предлагая версии весов в различных форматах, включая BF16 для тренировок и GGUF для интеграций с библиотекой bitnet.
cpp, которая обеспечивает нативное высокоэффективное исполнение на CPU и раскрывает потенциал экономии ресурсов. Особое внимание уделяется тому, что запуск BitNet через стандартные библиотеки transformers не позволяет получить никаких заметных преимуществ по скорости или энергозатратам из-за отсутствия специализированных вычислительных ядер. Чтобы раскрыть все достоинства 1-битной квантованной модели, необходимо использовать оригинальный C++ движок bitnet.cpp. BitNet B1.
58 2B4T — это важный шаг вперёд на пути создания масштабируемых, энергоэффективных и в то же время мощных языковых моделей. Она прокладывает путь к новым парадигмам снижения вычислительных затрат без потери качества, что особенно актуально в эпоху роста объёма данных и внедрения ИИ в повседневную жизнь. Исследователи и разработчики, заинтересованные в интеграции современных методов ускоренного ИИ, найдут в BitNet перспективную технологию для дальнейшего развития своих проектов. Сильные стороны этой модели — баланс между производительностью, компактностью и энергоэффективностью — делают её уникальным инструментом и подтверждают правильность выбранной стратегии нативного квантования. В будущем можно ожидать, что на базе данной платформы появятся более крупные модели, новые области применения, а также усовершенствованные версии с расширенной поддержкой языков и доменов знаний.
Microsoft BitNet B1.58 2B4T — пример того, как инновации в архитектуре и обучении могут изменить правила игры в области машинного интеллекта, приближая технологии к реальным сценариям использования с минимальными затратами.