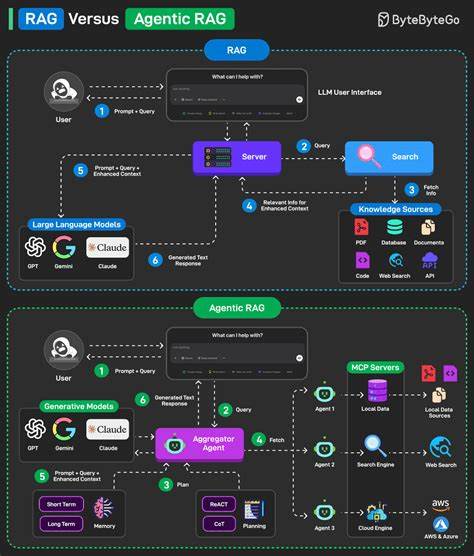
Развитие больших языковых моделей (LLM) открывает новые горизонты в области обработки естественного языка. Среди таких моделей выделяется Mistralai-7B — мощный предобученный трансформер, который благодаря своей архитектуре и количеству параметров способен решать широкий спектр задач от генерации текста до комплексных рассуждений и инструкций. Однако, полноценное обучение или дообучение таких моделей требует значительных вычислительных ресурсов и специализированного софта для эффективного использования возможностей современных GPU. В этой связи технология распределённого обучения становится ключевым инструментом, позволяя параллельно использовать десятки, а то и сотни видеокарт в единой среде. Внедрение DeepSpeed Pipeline — одной из наиболее передовых сред для распределённого обучения — стало важным этапом для оптимизации работы с Mistralai-7B.
DeepSpeed обеспечивает экономию памяти, увеличение пропускной способности и снижение времени тренировки за счёт оптимизации распределения задач и коммуникаций между устройствами. Реализация обучения Mistralai-7B с помощью DeepSpeed Pipeline предполагает разделение модели на этапы, которые последовательно обрабатываются разными группами GPU, что значительно ускоряет процедуры обратного распространения и обновления весов. Одной из ключевых особенностей этого процесса является поддержка больших батчей и смешанной точности, что снижает нагрузку на видеопамять без потери качества обучения. Кроме того, интеграция PySpark для подготовки и загрузки данных позволяет эффективно обрабатывать большие датасеты, например, такие как nvidia/Nemotron-Post-Training-Dataset-v1. Использование PySpark помогает параллельно загружать и предварительно обрабатывать данные, что сокращает время простоя GPU в ожидании входных данных.
В процессе подготовки датасетов реализуется вычисление косинусного сходства между контекстом и вопросом, а также между контекстом и ответом, что позволяет добавлять наиболее релевантные предложения для улучшения качества обучения модели и повышения точности ответов. Такой подход дополнительно усиливает энергоэффективность всего пайплайна, так как обрабатываемая информация становится более осмысленной и сфокусированной. При работе с DeepSpeed Pipeline важно учитывать правильную настройку конфигурационных файлов, таких как ds_config.json, где задаются параметры разделения модели, количество этапов, режимы оптимизации памяти и другие ключевые характеристики. Грамотно подобранные настройки позволяют предотвращать узкие места в коммуникациях между GPU и обеспечивают стабильность обучения без сбоев.
Кроме того, использование контейнеров Docker облегчает развёртывание и повторяемость экспериментов, создавая единое окружение с предустановленными зависимостями, включая PySpark, нужные версии CUDA, а также Java для корректной работы Spark. Одной из сложностей при использовании распределённых вычислений является разница в поведении файловых систем и путей записи данных, особенно при работе с Hadoop и локальной файловой системой. Важно правильно настраивать пути для сохранения результатов и checkpoints, чтобы избежать конфликтов или потери данных в многопользовательской среде. Современные кейсы обучения Mistralai-7B на базе DeepSpeed Pipeline показывают, что даже модели с миллиардами параметров становятся более доступными для исследователей и разработчиков благодаря эффективному распределению и масштабированию. Это открывает возможности для более быстрой адаптации модели под конкретные задачи, включая инструктивное обучение и обучение с подкреплением (RLHF) на специализированных датасетах.
В перспективе планируется расширение архитектуры за счёт добавления адаптеров для обработки визуальной информации, что позволит создать мульти-модальные модели с улучшенными способностями к рассуждению и генерации. Такой подход позволит интегрировать текстовые данные и изображения, обеспечивая более комплексное понимание контекста и выполнение заданий. В конечном итоге, объединение мощи DeepSpeed Pipeline, оптимизированных методов обработки данных через PySpark и уникальных архитектурных решений Mistralai-7B способствует созданию новых стандартов в обучении больших моделей. Это позволяет не только повышать качество и точность результатов, но и существенно снижать затраты на инфраструктуру. Разработка и открытое распространение исходного кода способствуют ускоренному развитию индустрии, обмену знаниями и появлению инноваций в сфере искусственного интеллекта.
Таким образом, использование DeepSpeed Pipeline для распределённого обучения Mistralai-7B становится важным шагом к демократизации доступа к большим языковым моделям и построению более эффективных приложений на базе AI, способных решать сложные задачи в различных сферах жизни и бизнеса.