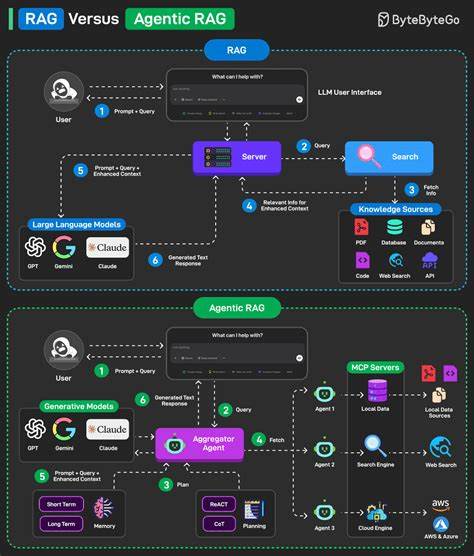
В последние годы концепция Retrieval-Augmented Generation (RAG) стала одной из наиболее обсуждаемых в сфере искусственного интеллекта и обработки естественного языка. RAG объединяет машинное обучение с механизмами поиска информации, позволяя моделям не только генерировать тексты, но и опираться на внешние базы данных и документы, чтобы создавать более обоснованные и конкретные ответы. Однако несмотря на энтузиазм вокруг технологии, не утихают споры о том, насколько RAG действительно готов к промышленному применению и решению реальных задач. Многие специалисты, работающие с RAG, отмечают, что текущие решения скорее напоминают экспериментальные прототипы или наборы инструментов, собранных вручную из разных компонентов и скриптов, чем стабильные и масштабируемые системы. Основная проблема заключается в том, что хотя технология работает в идеальных условиях, при попадании в реальный мир с его неоднозначными запросами и сложной пользовательской логикой, система начинает показывать слабые места.
Одной из главных трудностей является качество и релевантность извлекаемых данных. Многие реализации RAG используют векторные индексы для поиска наиболее подходящих фрагментов текста или документов. При этом могут возникать ситуации, когда возвращаются нерелевантные или слишком поверхностные данные, что приводит к ошибкам и галлюцинациям в сгенерированном тексте. В таких случаях модель либо ошибочно интерпретирует найденный материал, либо же дополняет его несуществующими фактами, пытаясь заполнить информационные пробелы. Проблема усложняется ещё больше, когда пользователь задаёт последовательные запросы с уточнениями и изменениями условий.
Многие RAG-системы не оснащены эффективными механизмами памяти или контекстного понимания, из-за чего цепочка вопросов превращается в хаотичный поток данных без логического развития. В результате ответ перестаёт соответствовать истинному смыслу запроса, и клиент получает либо бессвязный текст, либо ошибочные сведения, которые ставят под сомнение доверие к технологии. Также стоит обратить внимание на архетипичные подходы к построению таких систем. Некоторым разработчикам удаётся добиться стабильности, внедряя сложные каскады обработки запросов, где на каждом этапе применяется отдельный специально подготовленный промпт. Такой метод позволяет «разбить» задачу на шаги и повысить качество промежуточных результатов.
При этом применение ручных правил и логических ветвлений всё ещё занимает значительную часть процесса, что говорит о недостаточной автоматизации и универсальности. Некоторые успешно реализованные системы используют графовые базы данных и собственные индексирующие механизмы, что позволяет улучшить трассируемость и точность поиска. Такой подход особенно полезен в узкоспециализированных сферах, где важна надёжная система аудита и сопоставления данных. Однако это требует немалых затрат времени на написание тестов и тонкую настройку промптов, что не всегда оправдано в коммерческих целях. Интересно, что некоторые эксперты склоняются к мысли, что логика роутинга запросов должна предшествовать собственно извлечению данных.
То есть для начала системе нужно определить, действительно ли вопрос корректен, имеет смысл и какую цель преследует пользователь. Только после подтверждения этого шага происходит запуск процесса поиска и генерации ответа. Такой подход помогает снизить риск появления галлюцинаций и повысить релевантность выдачи. Среди обсуждаемых альтернативных решений зачастую упоминают использование инструментов на базе OpenSearch или Elasticsearch, комбинируемых с ИИ для формирования точных поисковых запросов. Это позволяет лучше контролировать качество выборки информации, однако не снимает проблему понимания семантики и сложных пользовательских интентов.
Разница в успехах внедрения RAG часто связана с областью применения. В случаях, где система служит для построения отчетов, аудита или поиска в строго структурированных данных, технологию удаётся настроить на высокий уровень надёжности и точности. В более свободных сценариях с нестандартными вопросами и богатыми на диалоги взаимодействиями RAG пока испытывает серьёзные трудности. Таким образом, несмотря на обширный потенциал и внушительные достижения, технология Retrieval-Augmented Generation на сегодняшний день трудно назвать полностью готовой к массовому промышленному применению без дополнительной доработки, масштабного тестирования и внедрения эффективных механизмов контроля качества и управления логикой. Современные RAG-системы часто требуют постоянного контроля и вмешательства инженеров, чтобы поддерживать работоспособность в сложных пользовательских сценариях.
Тем не менее, прогресс в области NLP и быстрота развития инструментов на базе искусственного интеллекта указывают на то, что в ближайшем будущем многие из перечисленных проблем будут успешно решены. Комбинация продуманных архитектур, усиленного обучения с учителем, улучшенных методов индексации и более точного понимания пользовательских намерений приведёт к появлению действительно надёжных и интеллектуальных решений на базе RAG. Эксперименты с разными архитектурами, углублённое исследование причин возникновения галлюцинаций и ошибки в генерации, а также интеграция контроля качества на обоих этапах — извлечения и генерации — являются ключевыми направлениями развития. Финальный этап будет заключаться не только в технической стабильности, но и в обеспечении пользователя понятным и предсказуемым взаимодействием с системой. Подводя итог, можно сказать, что RAG находится на пересечении стадии прототипов и зрелых продуктов.
От энтузиастов и ведущих специалистов зависит продвинуть эту технологию из лабораторий в массовую практику, сделав её действительно полезной и надёжной для широкого круга применений. Сейчас важна не только разработка новшеств, но и честная оценка текущего положения вещей, обмен опытом и совместная работа над устранением выявленных слабостей, чтобы в будущем RAG стала стандартом во многих отраслях, требующих интеллектуальной поддержки и автоматизации знаний.