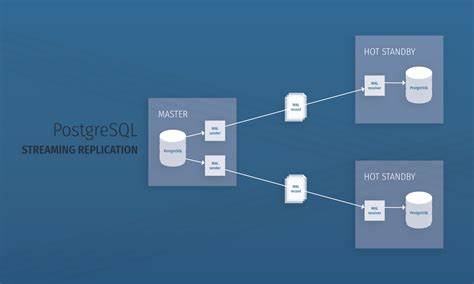
PostgreSQL является одной из самых популярных систем управления базами данных благодаря своей надежности, масштабируемости и мощным инструментам репликации. Одной из уникальных возможностей PostgreSQL, привлекающих внимание разработчиков и администраторов баз данных, являются UNLOGGED таблицы. Эти таблицы оптимизированы для высокой скорости записи благодаря отсутствию журналирования транзакций в Write-Ahead Log (WAL), что значительно снижает нагрузку на систему. Однако при использовании в репликационных сценариях возникают вопросы, связанные с их поведением и особенностями. В рамках систем с потоковой физической репликацией необходимо понимать, каким образом UNLOGGED таблицы ведут себя, как влияет изменение их типа на репликацию и что это значит для консистентности данных на вторичных узлах.
UNLOGGED таблицы по своей сути создаются с целью повышения производительности за счет отказа от записи операций в WAL. Это удобно для кэширования данных, временного хранения промежуточных результатов и других сценариев, где потеря данных не критична. Такой подход помогает избежать излишней нагрузки на диск и ускоряет запись, однако у него есть значимые недостатки. Основной из них — данные в UNLOGGED таблицах не реплицируются на слейвы через потоковую физическую репликацию. При сбое основного узла данные таких таблиц могут быть потеряны, а на репликах они будут недоступны.
При создании UNLOGGED таблицы в репликационной среде важно понимать, что её структура видна на вторичных серверах, поскольку метаданные таблиц сохраняются в WAL и поэтому стабильно реплицируются. Тем не менее, сами данные таких таблиц не проходят через WAL, и попытка получить к ним доступ на standby приводит к ошибке. PostgreSQL строго запрещает обращения к временным и UNLOGGED таблицам во время режима восстановления на репликах, что отражает фундаментальное ограничение репликации для таких объектов. Интересный сценарий возникает, когда UNLOGGED таблицу переводят в LOGGED (обычную) без остановки и выключения репликации. Этот процесс не только меняет статус таблицы, но и запускает немалую нагрузку на систему за счет создания полного WAL для уже существующих данных в таблице.
Во время такого изменения статус switch к LOGGED генерируются WAL записи, которые отправляются на реплики, что позволяет синхронизировать состояние таблицы и сделать данные доступными и видимыми на standby. С точки зрения администратора, это значит, что данные, которые до изменения были недоступны на репликах, после переключения полностью попадают в репликационные потоки. Сама операция изменения таблицы с UNLOGGED на LOGGED может занимать значительное время, особенно если таблица содержит большой объем данных. Продолжительность зависит от аппликативного оборудования, конфигурации дисковой подсистемы и размера данных. На практике известно, что обработка таблицы с десятками миллионов записей способна занимать несколько минут, вызывая временную задержку на репликах, которая выражается в репликационном лаге.
Во время этого процесса попытки доступа к таблице на стороне standby будут блокироваться до момента завершения репликации полной информации, что отражает внутренний механизм защиты от неконсистентного чтения. После того как операция переключения таблицы в LOGGED завершена и репликация догнала изменения, таблица становится полноценно доступной на уровне всех узлов. Теперь можно спокойно выполнять запросы SELECT и другие операции, опираясь на согласованную реплицированную копию данных. Если же позже таблицу снова переключить в состояние UNLOGGED, происходит обратный процесс: новые изменения больше не будут записываться в WAL, таблица перестанет реплицироваться, а на репликах вернется запрет на доступ. В отличие от включения логирования, выключение занимает меньше времени, так как не требует передачи большого объема данных, но и вызывает недоступность таблицы на репликах.
Такие особенности делают UNLOGGED таблицы привлекательными для задач, где критичен быстрый ввод данных и не нужна гарантированная репликация, например, при импорте временных данных, выполнении вычислений, кэшировании или сборе промежуточных результатов. При этом возможность переключения в LOGGED режим предоставляет мощный инструмент для последующей синхронизации и распространения актуального состояния таблиц на реплики, когда это необходимо. Помимо рабочих моментов с изменением статуса таблицы, стоит упомянуть и влияние UNLOGGED таблиц на производительность. Так как эти таблицы не образуют WAL, операции вставки и обновления по ним происходят значительно быстрее. В тестах с миллионом записей разница во времени вставки между UNLOGGED и LOGGED таблицами может быть существенной — UNLOGGED таблицы выигрывают, зачастую выполняя операции почти в полтора раза быстрее.
Такой прирост особенно важен при загрузке больших объемов данных, когда активное ведение журнала транзакций может стать узким местом. Однако это преимущество сопровождается определенными компромиссами. Невозможность репликации данных UNLOGGED таблиц в рамках стандартной потоковой физической репликации требует тщательного продумывания архитектуры приложений. Для сценариев, где нужна высокая доступность и консистентность данных между основным и второстепенными узлами, UNLOGGED таблицы не подходят. Использование их оправдано там, где можно легко восстановить или проигнорировать потерю данных, либо где важна максимальная скорость записи без требований к полноте данных на репликах.
Важной технической деталью является то, что при переключении статуса таблицы влияние распространяется и на связанные с ней объекты, в частности на последовательности для столбцов с автоинкрементом. PostgreSQL автоматически изменяет механизм сохранения последовательностей, но их статус можно менять и отдельно. Это создаёт дополнительные возможности для тонкой настройки поведения связанной нумерации и логирования. С точки зрения администрирования и обслуживания репликационной среды, понимание поведения UNLOGGED таблиц и влияния переключения режимов важно для планирования процессов загрузки данных и обеспечения доступности. Например, можно поэтапно загружать данные в UNLOGGED таблицу на главном узле во время интенсивных операций с максимальной скоростью, а после завершения - переключить таблицу в LOGGED режим, что синхронизирует содержимое на репликах.
Этот подход помогает избежать сильной репликационной нагрузки в пиковое время и минимизировать общую задержку данных. В целом, потоковая репликация PostgreSQL демонстрирует прозрачную и ожидаемую реакцию на изменение типа таблиц с UNLOGGED на LOGGED и обратно, хотя официальная документация не в полной мере освещает все аспекты данного поведения. Практические эксперименты показывают, что несмотря на то, что UNLOGGED таблицы видны в списке таблиц на репликах, данные по ним изначально недоступны. Только при создании WAL-логов после перевода в LOGGED статус данные становятся доступными и реплицируются консистентно. Для организаций и специалистов, управляющих крупными кластерами баз данных PostgreSQL, эти знания позволяют оптимизировать стратегии репликации и загрузки данных, балансируя между производительностью и консистентностью.
Умелое использование UNLOGGED таблиц и понимание особенностей их репликации расширяют возможности построения отказоустойчивых, масштабируемых систем с контролем нагрузок и минимальными простоями. Таким образом, потоковая репликация PostgreSQL в сочетании с гибкими режимами таблиц открывает широкие горизонты для решения бизнес-задач разной сложности. UNLOGGED таблицы служат надежным инструментом ускорения записи и оптимизации ресурсов, а переключение в LOGGED режим служит гарантией согласованности данных на репликах. Внедрение этих практик требует грамотного анализа сценариев использования, чтобы извлечь максимальную пользу и обеспечить стабильность работы систем баз данных.