В современном мире обработки данных системы сталкиваются с постоянной необходимостью поддерживать высокий уровень производительности при одновременном обеспечении корректности координации и управления процессами. В основе эффективных архитектур лежит идея разделения потоков управления и передачи данных, что позволяет устранить узкие места и оптимизировать работу всей системы в целом. Рассмотрим, как эта концепция реализована на примере системы Materialize и каким образом она решает одну из болевых точек — работу с большими выборками результатов. До недавнего времени в Materialize все результаты запросов передавались по единому протоколу, который отвечал за координацию и контроль работы кластеров. Это создавало одну из главных проблем: большие объемы данных, возвращаемые запросами SELECT, «загромождали» канал связи между кластером и координатором, приводя к блокировкам, снижению производительности и ограничению на объём данных, которые можно было вернуть пользователю.
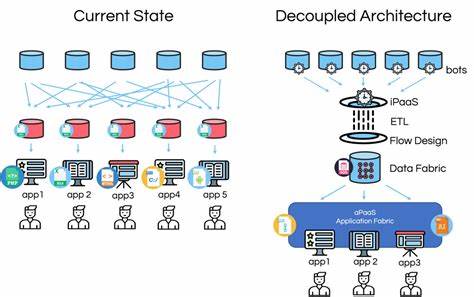
При этом все данные должны были полностью находиться в памяти координатора перед тем, как начнётся потоковая передача клиенту, что дополнительно ограничивало масштабируемость. Главная причина этих ограничений — смешение потоков контроля и передачи данных, когда координатор, отвечающий за координацию, вынужден обрабатывать и большие объёмы данных, предназначенных для передачи клиентам. Это обуза для системы, так как разные типы трафика требуют разных свойств и обработки: контрольные сообщения требуют строгой упорядоченности и секундных задержек, тогда как для данных важна пропускная способность и масштабируемость. Решением стала архитектура с «внеполосной» передачей данных — то есть вынесением грузной передачи больших наборов данных в отдельный поток, не связанный с управляющими каналами. В Materialize это реализовано через систему «peek stash», названную так по внутреннему обращению к SELECT-запросам как «peeks».
При превышении определённого порогового размера результата, данные больше не идут через управляющий протокол, а записываются во временные батчи в слой хранения persist, оптимизированный для больших объёмов данных. При этом координатор отправляет клиенту лишь метаданные, содержащие информацию о том, где именно в хранилище находятся результаты. Клиент уже напрямую получает доступ к этим результатам из persist, минуя узкие места управляющего канала и не перегружая координатор. Такая схема разделения ролей значительно повышает эффективность работы и масштабируемость системы за счёт разделения путей для контроля и передачи данных. Реализация данной архитектуры в Materialize продумана так, чтобы быть максимально прозрачной для пользователей и не требовать дополнительной настройки.
При старте получения результата запросы идут по традиционному пути через управляющий протокол, а при превышении порогового значения происходит плавный переход к внеполосной передаче. Все эти процессы выполняются автоматически и бессистемно, пользователи не замечают смену механизма. Технически процесс записи данных во временные батчи происходит в фоне, что освобождает главный поток вычислений для продолжения обработки других частей запроса. Это обеспечивает высокую отзывчивость системы даже при работе с очень большими объёмами данных и сложными запросами. Подобное асинхронное взаимодействие между вычислительным и хранением слоями — ещё одно важное преимущество архитектуры.
Совокупность перечисленных изменений воплощает фундаментальный принцип архитектурного проектирования распределённых систем — отделение путей управления от путей передачи данных. Управляющие протоколы предназначены для сообщений о состоянии, координации и управления, и им необходимы гарантии строгого порядка и низкой задержки. В то же время сам поток данных — в особенности большие объёмы — требует максимальной пропускной способности и масштабируемости, что превращает слой хранения persist в идеальное средство для таких задач. Преимущества такой архитекторы очевидны. Во-первых, она обеспечивает лучшую изоляцию: большие запросы не мешают координации функционирования кластера и не приводят к блокировкам в управляющих каналах.
Во-вторых, увеличивается масштабируемость, поскольку пропускная способность данных теперь не привязана к возможностям управляющего протокола. В-третьих, ресурсы используются эффективнее, так как persist оптимизирован для хранения и передачи больших объёмов, а многопоточная реализация во избежание блокировок позволяет эффективно распределять нагрузку. Данный подход непосредственно перекликается с общими тенденциями индустрии. Многие распределённые системы, включая современные объектные хранилища и сети доставки контента (CDN), отделяют операции с метаданными от передачи данных. Это помогает бороться с типичной проблемой возрастающих систем — узкими местами при обработке разных типов трафика одним и тем же каналом.
Пример Materialize демонстрирует, что правильная архитектура — это не просто ускорение единого канала, а осознание и разграничение разных требований к различным компонентам системы. Вместо увеличения пропускной способности одного конвейера задачу решают разделением потоков, назначением специализированных компонентов, каждый из которых справляется со своей задачей более эффективно. В будущем подобный принцип внеполосной передачи результатов может быть расширен и на другие сценарии работы системы. Это касается и подписок на данные в режиме реального времени (SUBSCRIBE), а также процессов записи и других потенциально высоконагруженных потоков данных. Создание абстракций на основе отрыва контролирующего и данных слоёв формирует прочную платформу для внедрения новых функций и повышения общей гибкости и масштабируемости.
Таким образом, опыт Materialize подчеркивает значимость архитектурного подхода, основанного на разделении контролирующего и передающего потоков. Это не просто техническое усовершенствование, а стратегическое совершенствование, открывающее путь к более устойчивым, масштабируемым и эффективным системам обработки данных, которые смогут справляться с возросшими требованиями к объёмам результатов и скорости их выдачи. Урок для разработчиков и архитекторов систем в том, что внимание к особенностям каждого вида трафика и его необходимым гарантиям, а также выделение для них отдельных инфраструктурных слоёв значительно улучшает качество решения и открывает возможности для развития. В итоге, лучший результат получается не от того, что стараешься ускорить один общий канал, а от того, что находишь правильное разделение ответственности между компонентами системы.