Современные информационные системы с каждым днем сталкиваются с растущими объемами данных и связанными с этим проблемами избыточности и дублирования информации. Дублирование данных приводит к увеличению затрат на хранение, замедлению процессов синхронизации, росту сетевого трафика, а также к чрезмерному потреблению вычислительных ресурсов. Особенно ярко эти проблемы проявляются в масштабных системах, обрабатывающих терабайты и даже петабайты данных, где эффективность решения вопроса с дублирующимися фрагментами напрямую отражается на скорости работы и экономии ресурсов.Одним из лучших подходов для минимизации избыточности является дедупликация — процесс выявления и устранения повторяющихся частей данных. Однако традиционные методы сжатия, хотя и уменьшают размер отдельных файлов, оказываются неэффективными для широкомасштабного поиска повторов в различных файлах или потоках данных.
Здесь на помощь приходит концепция контентно-зависимого разбиения (Content-Defined Chunking, CDC), а именно высокопроизводительный пакет Go-CDC-chunkers, созданный для работы с CDC в среде Go.Проблема дублирования возникает потому, что множество систем обрабатывают одни и те же данные многократно. Например, при резервном копировании, синхронизации облачных хранилищ, ведении журналов и кэшировании CI/CD. Это приводит к перерасходу времени и ресурсов, которые можно было бы использовать с большей пользой, а также к значительным финансовым затратам, особенно при оплате за использование облачных сервисов по объему переданных или сохраненных данных. Дедупликация позволяет избавляться от повторов, освобождая пространство и ускоряя процессы обработки, сокращая время ожидания пользователей и повышая общую производительность.
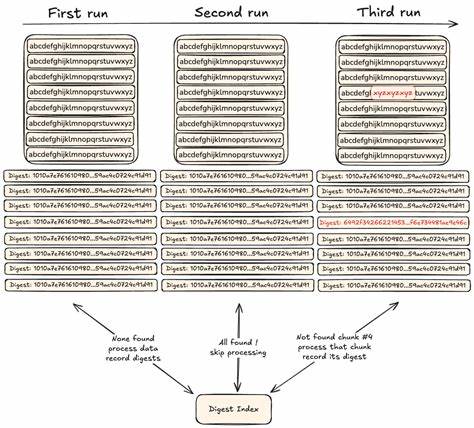
Go-CDC-chunkers — это библиотека с открытым исходным кодом, распространяемая по лицензии ISC, ориентированная на высокую скорость и эффективность применения CDC. Она предлагает удобный интерфейс и поддержку нескольких алгоритмов, включая оптимизированные версии FastCDC, его ключевую вариацию Keyed FastCDC, а также более новые разработки вроде UltraCDC и JumpCondition. Благодаря интерактивному API этот пакет удобно интегрируется как в потоковые, так и в пакетные рабочие процессы, обеспечивая качественное разбиение данных на фрагменты переменной длины, основанное на содержимом, и устойчивое к сдвигам информации.Отличительной особенностью CDC, используемой в этом пакете, является умение восстанавливать корректное разбиение даже при незначительных изменениях или сдвигах данных. В отличие от фиксированного деления на блоки определенного размера, которое ломается при добавлении или удалении даже одного байта в начале файла, CDC анализирует локальные свойства данных и определяет точки разбиения на основе уникальных контекстных признаков.
Это позволяет сохранить совпадение большинства фрагментов при изменениях, что принципиально улучшает показатели дедупликации.Алгоритм FastCDC, лежащий в основе большинства реализаций данного пакета, использует функцию быстрого вычисления подписи (rolling hash) на базе предварительно сгенерированной таблицы значений Gear. Благодаря этому достигается высокая производительность за счет отсутствия необходимости в полном сканировании большого окна данных и минимизации затрат на вычисление хешей. Кроме того, алгоритм заранее определяет минимальные, целевые и максимальные размеры блоков, что обеспечивает сбалансированное распределение по длине и препятствует появлению слишком мелких или чрезмерно крупных фрагментов.Важной инновацией является внедрение Keyed FastCDC — модифицированной версии алгоритма, в которой для генерации таблицы Gear используется ключ, передаваемый при инициализации.
Это усложняет предсказание точек разбиения без известного ключа, обеспечивая дополнительный уровень защиты и конфиденциальности данных. Для систем с повышенными требованиями к безопасности, особенно для распределенных сред и шифрованных наборов данных, такой подход становится незаменимым.Отличительной чертой Go-CDC-chunkers является не только высокая производительность, измеряемая в гигабайтах данных в секунду, но и ресурсосберегающая архитектура, минимизирующая нагрузку на память и процессор. Это особенно важно для встроенных и облачных решений, где оптимизация вычислительных ресурсов напрямую связана с экономической эффективностью и масштабируемостью системы.В дополнение к пакетам для FastCDC и его вариациям, проект приглашает к участию в развитии и интеграции новых алгоритмов и улучшений через открытую платформу, что способствует непрерывному развитию технологий разбиения и дедупликации.
Благодаря простоте использования и гибкости, Go-CDC-chunkers уже применяется в разнообразных сферах: от систем резервного копирования и хранения данных до построения механизмов синхронизации файлов, систем непрерывной интеграции и больших дата-пайплайнов.Методы дедупликации и разбиения на основе CDC выводят оптимизацию работы с данными на новый уровень. Они позволяют избежать повторных операций записи, передачи и анализа одних и тех же данных, снижая избыточность и повышая скорость отклика систем. При этом Go-CDC-chunkers обеспечивает разработчиков всем необходимым набором инструментов для реализации эффективных, адаптируемых и защищенных решений по работе с большими объемами данных, обеспечивая долгосрочную экономию ресурсов и времени.В итоге, для разработчиков, проектировщиков систем хранения и инженеров по обработке данных рекомендуется обратить внимание на библиотеку Go-CDC-chunkers как на мощное, современное и готовое к промышленному применению решение, способное кардинально улучшить подход к дедупликации и разбиению данных.
В условиях постоянного роста требований к объему и скорости обработки информации качество таких инструментов становится ключевым фактором успеха.







