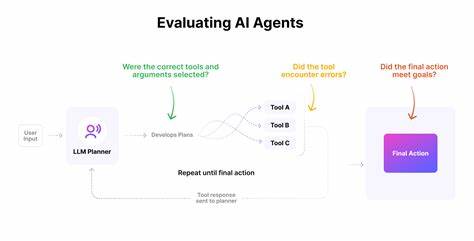
Оценка AI-продуктов всегда была непростой задачей. Сложность обусловлена особенностями работы искусственного интеллекта – нестабильностью, статистической природой выводов и непредсказуемостью поведения модели при разных условиях. Часто команды пытаются создать одну большую и всеобъемлющую оценку работы системы и надеются получить общий показатель, отражающий качество всей модели. Однако, практика показывает, что более эффективным методом становится использование множества маленьких, узконаправленных оценок, каждая из которых контролирует отдельный аспект продукта или конкретную задачу. Этот подход открывает новые горизонты в управлении качеством AI и значительно облегчает процесс развития и поддержки продукта.
Понимание того, что такое маленькие evals и почему они превосходят традиционные большие оценки, помогает построить более стабильную, быструю и надежную систему оценки. Маленькие оценки нацелены на конкретную проблему или цель продукта. В отличие от одной крупной проверки, которая создает суммарный балл на основе глобального набора данных, маленькие evals концентрируются на отдельных функциях, например, правильности обработки неоднозначных запросов, отказе от обсуждения конкурентов или следовании стилю бренда. Такой раздельный подход позволяет выявлять мелкие сбои и регрессии, которые в больших оценках просто теряются на фоне общего показателя. Стабильность и поддерживаемость также выигрывают от использования маленьких оценок.
При изменении целевых метрик продукта или обновлении модели крупная оценка требует переработки огромного объема данных, что становится слишком затратным и трудоемким процессом, дополнительно усложненным уходом из команды разработчиков, знающих нюансы. С маленькими evals достаточно изменить или удалить несколько конкретных проверок, сохраняя остальные без изменений, что облегчает поддержание исторической совместимости и фиксированность показателей. Кроме того, создание маленьких оценок легче и быстрее, что повышает вовлеченность всей команды. Если каждый специалист – менеджер продукта, дизайнер, инженер, QA или представитель службы поддержки – может самостоятельно создать небольшой тест на выявленную проблему за 10 минут или меньше, это меняет культуру работы с качеством. Появляется возможность оперативно фиксировать ошибки и предотвращать их повторное появление, что значительно улучшает пользовательский опыт и ускоряет темп развития.
Не менее важным преимуществом является то, что маленькие evals позволяют выявлять критичные регрессии, которые общий балл скрывает. Простой пример – при обновлении модели общий балл может улучшиться, а по отдельным аспектам наблюдаться резкое ухудшение. Без фокусированных проверок эти нюансы остаются незамеченными и в итоге доходят до конечного пользователя, вызывая недовольство. Анализ распределения результатов по узким категориям помогает не только обнаружить проблемы, но и понять, где и как оптимизировать модель или корректировать подходы к разработке. Стоит отметить, что маленькие оценки нельзя считать аналогом классических юнит-тестов в программировании, хотя есть сходства в идее проверки отдельных частей системы.
AI-системы не детерминированы, и результаты на одном примере могут меняться при повторных запусках. Поэтому маленькие evals должны осуществляться на больших выборках, учитывая статистическую значимость и вероятность, а не давать простой да/нет ответ. Это повышает надежность проверок и минимизирует ложные срабатывания. Внедрение культуры небольших и частых проверок требует правильного инструментария. Существуют специализированные платформы, такие как Kiln, предоставляющие простой в использовании интерфейс, позволяющий создавать, запускать и анализировать маленькие evals без глубинных знаний в машинном обучении.
Автоматическая генерация синтетических данных, поддержка человеческой аннотации и возможность быстрых сравнений версий моделей делают их мощным решением для практического внедрения. Обучение команды работе с такими инструментами и создание привычки фиксировать и предотвращать ошибки через маленькие проверки становится ключевым элементом устойчивого роста AI-продукта. В итоге подход с множеством маленьких evals формирует фундамент качественной, прозрачной, поддерживаемой и легко развиваемой AI-системы. Он обеспечит сокращение времени на исправление ошибок, улучшит коммуникацию в команде и позволит своевременно выявлять важные проблемы до их попадания к пользователям. В условиях быстро меняющейся сферы искусственного интеллекта такая практика становится неотъемлемой частью успешного выпуска и сопровождения конкурентоспособных решений на рынке.
Именно поэтому большинство профессионалов и лидеров индустрии рекомендуют отказаться от зависимости от одной большой оценки в пользу гибкой системы из множества мелких, поддерживающих эффективную и понятную прозрачную систему контроля качества AI-продукта.



![Trump vs. CASA [pdf]](/images/826160FE-5124-41F3-90E3-EE8684A250D3)