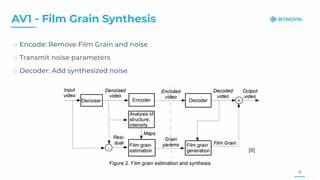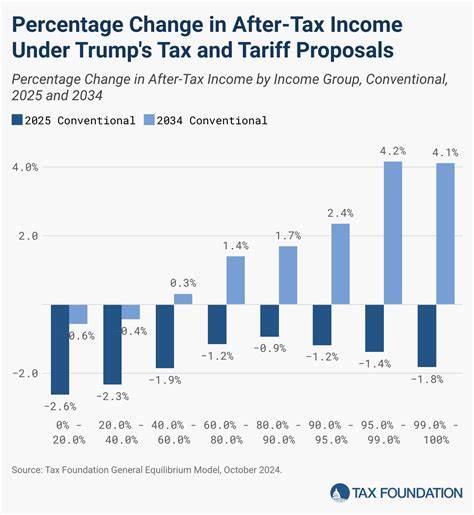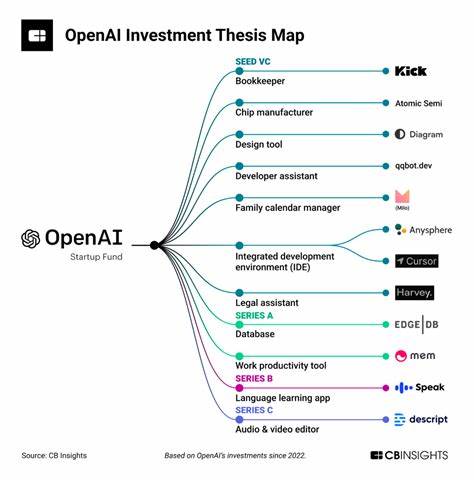
Современный мир стремительно развивается благодаря достижениям в области искусственного интеллекта. Одной из наиболее впечатляющих технологий стали крупномасштабные языковые модели, способные генерировать текст, приближенный к человеческому уровню. Компании, такие как OpenAI и Perplexity, активно работают над методами улучшения своих моделей, чтобы обеспечить высокий уровень качества, информативности и естественности создаваемого контента. Разберемся, как именно происходит процесс тонкой настройки моделей и почему он важен для получения богатого, насыщенного и точного текста. Основу большинства современных языковых моделей составляет обучение на огромных объемах текстовых данных.
Это обучение позволяет моделям усваивать структуру языка, логику построения предложений, а также базовые знания о мире. Однако первоначально такие модели создают довольно обобщенный и иногда недостаточно точный контент. Для повышения качества и адаптации под конкретные задачи применяется процесс тонкой настройки — fine-tuning. Этот этап позволяет подстроить модель под специфику области, задачи или даже стиль коммуникации. Тонкая настройка начинается с выбора подходящего тренировочного набора данных.
Чтобы модели генерировали более глубокий и детализированный текст, компании используют тщательно отобранные корпуса, часто с добавлением экспертных данных или специализированных текстов. Это может быть литература узкой тематики, специализированные статьи, технические документы или любые другие источники, которые соответствуют целям конечного продукта. OpenAI, например, использует наборы данных с различными жанрами текстов, что способствует формированию многогранного и богатого по содержанию вывода. Обработка и подготовка данных играют ключевую роль. Удаление шума, корректировка ошибок и обеспечение консистентности данных позволяют модели учиться на высококачественном материале, что непременно влияет на уровень выходного текста.
В процессе обучения применяются современные методы регуляризации и оптимизации, обеспечивающие стабильность модели и предотвращающие переобучение, что особенно важно для сохранения способности генерировать разнообразные и релевантные ответы. Еще одной важной практикой является обучение с подкреплением на основе человеческой обратной связи. OpenAI известна своим подходом RLHF (Reinforcement Learning from Human Feedback), когда модель сначала обучается на большом количестве данных, а затем корректируется с учетом оценок, поставленных живыми специалистами. Такой метод позволяет значительно улучшить качество генерации: ответы становятся более точными, уместными и понятными для пользователей. В компаниях, подобных Perplexity, тонкая настройка также включает использование продвинутых алгоритмов для интеграции внешних источников знаний.
Это обеспечивает возможность предоставлять не только грамотный текст, но и актуальную, основанную на фактах информацию. В результате конечный продукт не просто формирует читаемый контент, а предлагает обоснованные и развернутые ответы на сложные запросы пользователей. Оптимизация параметров модели и динамический выбор наиболее релевантных данных во время генерации помогают создавать тексты, которые отличаются богатством стиля и глубиной понимания тематики. Таким образом, автоматически формируемая информация становится все более ценной и персонализированной. Важным аспектом является адаптация моделей под нужды конечных пользователей.
Компании стремятся обеспечить сохранение этических норм, предотвращение предвзятости и создание контента, который будет одинаково полезен различным категориям аудитории. Для этого внедряются фильтры и дополнительные этапы проверки генерируемых данных, что снижает вероятность появления вредоносной или некорректной информации. Непрерывное обучение и обновление моделей позволяют поддерживать актуальность знаний. В быстро меняющемся мире информации способность быстро адаптироваться к новым реалиям становится стратегическим преимуществом. Именно поэтому OpenAI и Perplexity регулярно выпускают обновления своих систем, вводят новые техники обучения и интегрируют свежие данные.
Таким образом, тонкая настройка современных языковых моделей — это сложный и многоступенчатый процесс, включающий подбор и обработку качества тренировочных данных, обучение с использованием обратной связи от экспертов, интеграцию внешних источников и контроль качества вывода. Это позволяет создавать насыщенные, информативные и хорошо структурированные тексты, которые находят широкое применение в самых разных сферах — от помощи в исследованиях до поддержки пользователей в реальном времени. Развитие технологий искусственного интеллекта и совершенствование методик их тонкой настройки продолжают открывать новые перспективы. Компании вроде OpenAI и Perplexity не только демонстрируют мощь современных моделей, но и формируют стандарты качества и этические нормы для генерации контента, что делает взаимодействие с ИИ максимально эффективным и удобным для людей по всему миру.