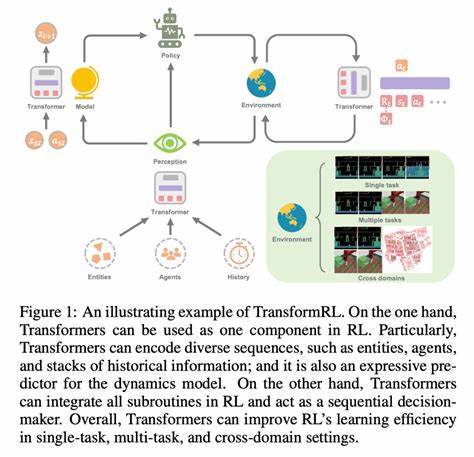
В современном мире машинного обучения и обработки естественного языка обучение с подкреплением (RL) становится все более востребованным методом, позволяющим создавать интеллектуальные модели, которые могут улучшать свои показатели через взаимодействие с окружающей средой. Особое место в этой области занимают трансформеры - архитектуры, которые благодаря своим масштабируемым возможностям перевернули подходы к генерации и пониманию текста. Однако при их интеграции в RL-системы часто возникает проблема различий между логарифмическими вероятностями, вычисляемыми собственными движками и эталонной библиотекой Transformers. Разбор и устранение таких расхождений становится крайне важным для корректного обучения моделей и их последующего применения. Логарифмические вероятности (logprobs) играют ключевую роль в обучении с подкреплением с использованием языковых моделей.
Они позволяют точнее измерять вероятность предсказания конкретного токена, что напрямую влияет на качество обратной связи и эффективность обучения. Тем не менее, при работе с разными механизмами генерации и оценивания - например, кастомными движками вроде vLLM или sglang и библиотекой Transformers от Hugging Face - могут возникать несоответствия в вычислениях logprobs, что ведет к серьезным проблемам при обучении. Одной из основных причин таких расхождений является реализация вычислений логарифмических вероятностей на уровне низкоуровневых операций с тензорами. Изменения в порядке вычислений, различия в числовой стабильности, особенности применения softmax и log-softmax функций могут приводить к небольшим, но накопительным отличиям. Например, в представленной методологии реализован довольно продвинутый подход с разбиением вычислений на чанки для оптимизации памяти и стабильности работы на GPU, включая динамическое уменьшение размера чанков при возникновении ошибок Out-Of-Memory.
Такой подход само по себе может вносить вариаций, особенно при смешивании разных устройств (CPU и CUDA). Важным аспектом является корректное совмещение вычислений в режимах с и без кэширования, а также правильное совмещение устройств, на которых размещаются модели, токены и веса головки lm_head. Неверная синхронизация или трансфер данных между CPU и GPU может привести к манипуляциям с порядком вычислений и даже потере точности - например, при конвертации типов данных между bf16 и float32. В интеграции с библиотекой Transformers предусмотрено отключение использования кеша (use_cache=False), что также отражается на итоговых значениях logprobs. Кроме того, участие в процессе различных оптимизаций и фич, таких как Flash Attention версии 2, влияет на результат, предоставляя более быстрое, но потенциально немного отличающееся от эталона поведение.
Это требует тщательного матчинга устройств и аккуратной работы с весами модели для предотвращения негативного влияния на вычисления вероятностей. При сравнении двух движков - например, vLLM с использованием опционального параметра inductor и sglang - были измерены ключевые метрики расхождения логарифмических вероятностей. Средняя абсолютная погрешность (MAE) и корень среднеквадратичной ошибки (RMSE) находятся на уровне тысячных, а коэффициент корреляции Пирсона близок к 0.9997-0.9998, что свидетельствует о впечатляюще высокой согласованности.
Однако даже такие незначительные отклонения, если не отслеживать их специально, могут привести к деградации качества обучения на больших объемах данных и итераций. Для диагностики расхождений применяют комплексный подход. Традиционно это включает выгрузку сырого лога с токенами, превалентными и генерируемыми идентификаторами, а также вычисленными движком и HF значениями logprobs. Анализ этих данных с помощью визуализаций - например, корреляционных графиков в линейном и логарифмическом масштабе, а также графиков разницы вероятностей по позициям токена - помогает наглядно выявить проблемные участки. Аналогично строятся таблицы для наиболее длинных и типичных генераций с детальной информацией по отдельным токенам, где можно обнаружить конкретные токены, вызвавшие расхождения.
Архитектурно важна корректная обработка входных последовательностей: использование единого токенизатора для всех движков, применение идентичных шаблонов чат-промптов, соблюдение одинакового порогового количества токенов и максимальных длины новых токенов. В представленной реализации применена сложная система токенизации с добавлением утилит для шаблонизации и построения чат-промптов, что обеспечивает консистентность подготовки данных и минимизирует человеческий фактор как источник ошибок. Еще один важный аспект - работа с батчами. В эре объемных моделей и больших наборов данных применение батчирования с оптимальным размером, а иногда с применением динамических tamaño по длине последовательностей, помогает сбалансировать нагрузку и улучшить производительность без ущерба точности. В коде реализована сортировка по длине с последующим разбиением на бакчи для подсчета HF логарифмов вероятностей, что сокращает накладные расходы на паддинг и уменьшает вероятность ошибок связанной с переполнением памяти.
Для разработчиков и инженеров машинного обучения крайне полезным является готовый к использованию скрипт, который автоматически объединяет полученные данные от движков и сравнивает их с эталонными вычислениями. Он не только собирает метрики качества, но и выводит подробные отчеты в формате JSON, Excel и графики, что существенно облегчает процесс анализа и ускоряет принятие решений по улучшению моделей и инфраструктуры. Важно понимать, что доля несовпадений может быть обусловлена и некоторыми эвристическими или экспериментальными настройками движков, которые отличаются от оригинальной реализации Transformers. Например, при использовании temperature, top_p, top_k с генерирующими методами или при работе в режиме без кэширования и с динамическим запросом на logprobs. Любая разница во входных параметрах или способах семплинга также приводит к неизбежным отклонениям.
В целом, создание устойчивых, высокопроизводительных и точных систем RL с трансформерами требует внимательного контроля за согласованностью логарифмических вероятностей на всех этапах генерации, оценки и обучения. Наличие подробных инструментов для дебага и сравнительного анализа не только экономит время, но и повышает качество итоговых моделей. Перспективы развития этой области включают улучшение интеграции между движками и библиотеками трансформеров, поддержка новых оптимизаций без потери точности, а также разработку комплексных тестов для автоматического мониторинга стабильности logprob вычислений. Эти меры позволят создавать более надежные RL-системы, способные успешно решать сложные задачи обработки естественного языка и адаптироваться к новым условиям без потери производительности. .