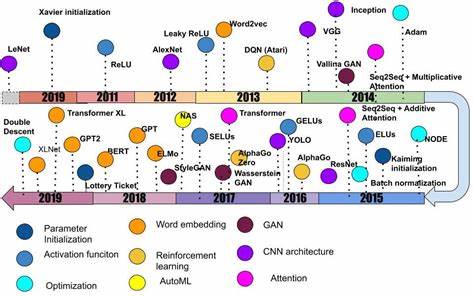
Последнее десятилетие стало свидетелем невероятного прогресса в области искусственного интеллекта, главным двигателем которого стало глубокое обучение. Технологии, ранее казавшиеся научной фантастикой, получили практическое воплощение, а нейронные сети стали основой многих инновационных решений в различных сферах жизни. Начавшись с базовых концепций и идей, глубокое обучение за десять лет прошло путь от академической новинки до повсеместного инструмента, который влияет на наше ежедневное взаимодействие с технологиями. Ключевым фактором успеха глубокого обучения стало наличие мощного вычислительного железа и огромных объемов данных. Появление графических процессоров, оптимизированных под параллельные вычисления, позволило тренировать нейросети гораздо быстрее и на больших объемах данных.
Большие датасеты, такие как ImageNet, дали толчок к развитию более глубоких и сложных моделей, способных справиться с задачами распознавания изображений и понимания текстов с ранее недостижимой точностью. В начале 2010-х годов одним из важнейших открытий стало правильное инициализирование весов нейросетей, что позволило решить проблему затухающих и взрывающихся градиентов. Метод инициализации, известный как инициалиация Ксавье, помог стабилизировать обучение и существенно повысил эффективность. Вскоре появилась и улучшенная версия — инициализация Кайминга, которая адаптировалась под использование новых функций активации, таких как ReLU (выпрямленная линейная единица). Функция ReLU стала революционным шагом вперед по сравнению с классическими сигмоидными функциями, так как позволяла преодолевать ограничение затухающих градиентов и поддерживала обучение очень глубоких сетей.
Появление архитектуры AlexNet в 2012 году считается одним из ключевых событий всего десятилетия. Эта глубокая сверточная нейросеть шла дальше традиционных моделей, используя восемь слоев и около 60 миллионов параметров, что привело к драматическому снижению ошибки в соревновании ImageNet. AlexNet показала, что глубокие нейросети, обученные на больших объемах данных и с использованием GPU, способны существенно превзойти существующие методы компьютерного зрения. Крупные наборы данных и соревнования вокруг них стимулировали дальнейшее развитие компьютерного зрения и машинного обучения. Вклад ImageNet нельзя переоценить: благодаря ему появилась возможность стандартизировать задачи и проводить объективную оценку эффективности моделей.
Этот подход спровоцировал взрыв интереса к глубоким нейросетям и привел к разработке новых, все более сложных архитектур. Следующим важным направлением стало представление слов в виде векторов — векторизация текста, позволившая моделям лучше понимать контекст и смысл слов. Технологии, основанные на word2vec, предложили способ преобразования слов в числовые представления, основываясь на их окружении в тексте. Это дало возможность значительно повысить качество обработки естественного языка, что особенно важно для таких задач, как перевод, классификация и генерация текста. Реализация методов глубокого обучения в области обучения с подкреплением также стала прорывной.
Используя глубокие нейронные сети для оценки ценности состояний и действий, была достигнута значительная успешность в управлении сложными средами, таких как игры Atari. Эти подходы дали начало развитию глубокого обучения с подкреплением, объединившего двух самых мощных парадигм ИИ. Появившиеся генеративные состязательные сети (GAN) произвели революцию в области генерации изображений и других данных. Используя концепцию состязания между двумя нейросетями, генератором и дискриминатором, GAN смогли создавать реалистичные образы, приближенные к настоящим. Несмотря на сложности с обучением и нестабильность моделей, дальнейшие улучшения, такие как Wasserstein GAN, позволили значительно повысить качество и стабильность генерации.
Метод внимания (attention), впервые широко представлен в задачах машинного перевода, вскоре стал основой трансформерной архитектуры. Трансформеры изменили подход к обработке последовательностей, отказавшись от рекуррентных нейросетей и предложив масштабируемую параллельную обработку. Это привело к созданию моделей, таких как BERT и GPT, которые радикально улучшили понимание текста и генерацию связного естественного языка, открыв новую эру в развитии НЛП. В 2015 году появление остаточных сетей (ResNet), решивших проблему затухающих градиентов при еще большей глубине, стало очередным шагом в эволюции нейросетей. Простая идея пропуска слоя через «скачок» улучшила обучение и позволила создавать модели со сотнями и даже тысячами слоев без потери качества.
Параллельно с архитектурными нововведениями развивались методы оптимизации. Адаптивные алгоритмы, такие как Adam и RMSProp, значительно упростили и ускорили процесс обучения, сделав нейросети более доступными для широкого круга исследователей и разработчиков. Еще одна важная тема последних лет — автоматизация проектирования архитектур нейросетей с помощью нейросетевого поиска (Neural Architecture Search). Этот подход, использующий методы обучения с подкреплением или эволюционные алгоритмы, позволяет создавать высокоэффективные модели без трудоемкого ручного подбора параметров и конфигураций. Важным наблюдением стал феномен двойного нисходящего риска (Double Descent), который выявил, что увеличение размеров модели и объемов данных не всегда приводит к переобучению, а в ряде случаев способствует улучшению обобщающей способности моделей.
Это противоречит классическим представлениям о компромиссе между смещением и дисперсией и дает новое понимание природы обучения глубоких сетей. Гипотеза лотерейного билета (Lottery Ticket Hypothesis) выявила, что в больших нейросетях существуют небольшие подмножества параметров, которые при правильной инициализации способны обучаться самостоятельно и достигать качества исходных моделей. Это открытие важно для разработки более эффективных и легковесных моделей, способных работать на ограниченных ресурсах. Перспективы следующего десятилетия связаны с глубоким осмыслением фундаментальных принципов работы нейросетей, а также с развитием их общих способностей и устойчивости. Несмотря на многочисленные успехи, современные модели все еще требуют огромных объемов данных и вычислительных ресурсов, а также испытывают проблемы с обобщением и объяснимостью результатов.
Глубокое обучение стало ключевым инструментом для искусственного интеллекта в 2010-х, открыв двери к новым приложениям и поставив фундамент для будущих достижений. Прогресс, достигнутый за это время, нельзя недооценивать, ведь сегодня нейросети используются в медицине, автономных транспортных средствах, голосовых помощниках и многих других областях. В целом, прошедшее десятилетие можно назвать настоящей эпохой глубокого обучения — периодом стремительного развития, переломных идей и воплощения самых смелых научных гипотез в реальные технологии, изменяющие мир вокруг нас. Новые открытия и инновационные подходы непременно продолжат этот тренд, двигая границы возможного в сфере искусственного интеллекта и позволяя создавать системы, способные решать все более сложные задачи.