В современном программировании линтеры - незаменимый инструмент, помогающий разработчикам писать более качественный и читаемый код. Они анализируют исходные файлы и подсказывают, где можно улучшить стиль, устранить потенциальные баги и повысить соответствие принятым стандартам. Однако иногда именно линтеры могут привести к неожиданным проблемам, особенно если автоматические исправления не учитывают специфики языка или контекста. Рассмотрим на примере Go ситуацию, когда строгие рекомендации линтера привели к поломке логики обработки ошибок и как этого избежать. В языке Go с версии 1.
13 была значительно усовершенствована система работы с ошибками. Появились новые возможности для сравнения и оборачивания ошибок, а также рекомендации по правильному их использованию. Суть изменений в том, что теперь ошибки можно не просто сравнивать напрямую, но и проходить по цепочке вложенных ошибок с помощью функции errors.Is. Это позволяет писать более информативный и модульный код, когда одна ошибка может оборачивать другую, сохраняя её подробности и позволяя при этом идентифицировать корневую проблему.
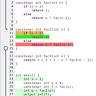
Ключевым моментом является то, что при реализации собственного типа ошибки можно создавать метод Is, который скажет, как именно пользователь хочет соотносить свою ошибку с другими. Если этот метод реализован правильно, функция errors.Is сможет корректно определить, эквивалентна ли ошибка целевой. Но именно здесь и кроется подвох. В реальной задаче был написан тип ошибки DataEOFError, который содержал имя файла, причину которого стала неожиданная концовка данных.
Его метод Is предполагал напрямую сравнивать ошибку с io.ErrUnexpectedEOF. Также был создан второй тип ошибки ProcessingFailedError, который оборачивает другую ошибку и хранит идентификатор обработки. Тесты показывали, что логика работает корректно, и ошибки сравнивались по назначению. Однако при запуске в CI системе был активирован golangci-lint с включённым правилом err113, который настоятельно рекомендует избегать прямого сравнения ошибок через оператор == и использовать для этого errors.
Is. В попытке следовать рекомендациям линтера, разработчики заменили прямое сравнение в методе Is на вызов errors.Is, надеясь упростить и обезопасить код. Внешне исправление выглядело логичным и даже правильным - ведь для проверки равенства ошибок теперь в Go рекомендуют именно errors.Is.
Результат был неожиданным и негативным: тесты начали падать. Ошибки стали сравниваться некорректно, появляются ситуации, когда две разные ошибки рассматривались как равные. Такой эффект объясним, если понять внутренний механизм работы errors.Is. Эта функция не просто проверяет равенство, она рекурсивно идёт по цепочке ошибок, вызывая Is у каждого элемента и пытаясь найти совпадение.
Таким образом, когда в методе Is вызвали errors.Is, произошло нарушение фундаментального принципа - метод должен проводить только поверхностное, непосредственное сравнение с целевой ошибкой, не обходя вложенности. Использование же рекурсивного поиска привело к эффекту бесконечной взаимной индукции, где исходная ошибка считалась эквивалентной целевой, а целевая - исходной, что привело к логическому сбою. Интересно, что даже официальный линтер errortype учитывает подобные паттерны и может обнаруживать ошибочную реализацию Is. Но в популярном meta-linter golangci-lint эта тонкость не всегда воспринимается, а правило err113 трактуется более универсально.
Автоматическое исправление кода сработало без учёта специфики поведения Is и нарушило контракт, наложенный на функцию. Подобные ошибки не просто незначительны - они могут повлиять на всю архитектуру обработки ошибок в больших приложениях, где важно точно понимать происхождение и детали возникновения проблем. Если две разные ошибки ошибочно считаются равными, то фильтрация, логгирование, маршрутизация и обработка исключительных ситуаций становятся неправильными. Примером из реального мира служит библиотека fluxcd Controller Runtime, где встречается похожая проблема с ошибкой KeyNotFoundError. Метод Is в ней реализован с использованием errors.
Is в неправильном направлении, в результате чего две разные ошибки с разными ключами могут рассматриваться как одна и та же. Это подтверждает, что ошибка не является теоретическим исключением, а возникает в промышленном коде. Что же из этого следует? Во-первых, очень важно понимать, что метод Is в пользовательском типе ошибки должен проводить именно поверхностное сравнение, а не рекурсивное. Внутри него нужна операция равенства на уровне объектов, чаще всего с помощью оператора ==. Во-вторых, рекомендации линтеров всегда стоит воспринимать критически и анализировать применимость к конкретному контексту.
Зачастую универсальные правила не учитывают тонкости языка и специфики реализации интерфейсов. Тестирование ошибок - еще один ключевой момент. Нужно не просто покрывать тестами основное поведение, но и негативные случаи на равенство и неравенство различных инстансов ошибок. Это помогает вовремя обнаружить нарушения в логике и предотвратить сбои в продакшене. Подводя итог, можно сказать, что инструменты с автоматическими советами и исправлениями - это мощный помощник, но и потенциальный источник проблем при неправильном использовании.
Разработчикам нужно хорошо разбираться в принципах работы тех механизмов, которые они применяют, и не слепо доверять рекомендациям, не учитывающим контекст. Особое внимание нужно уделять реализации интерфейсов, в частности для ошибок в Go, чтобы обеспечить корректную и надёжную работу приложений. Понимание "почему" важно не меньше, чем знание "как" - ключ к грамотному и качественному программированию. Соблюдая это правило, можно избежать многих подводных камней и использовать линтеры и другие инструменты максимально эффективно, не жертвуя стабильностью кода. История с поломкой кода из-за err113 напоминает, что всегда стоит проверять изменения и исправления вручную, внимательно читать документацию и примеры, а при необходимости обращаться за консультацией к сообществу или авторитетным источникам на тему внутренней работы языка и его стандартных библиотек.
.