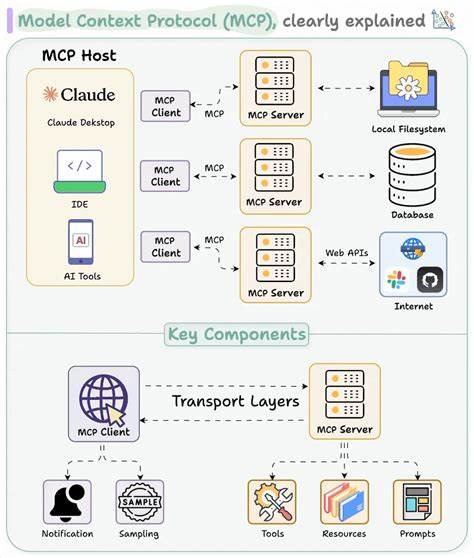
С развитием технологий искусственного интеллекта и их интеграции в различные сферы бизнеса, протокол Model Context Protocol (MCP) становится все более актуальным инструментом для разработки приложений, взаимодействующих с внешними сервисами. MCP позволяет крупным языковым моделям (LLM) вызывать внешние инструменты в ходе своей работы, открывая новые возможности в автоматизации и повышении эффективности процессов. Однако использование MCP в производственных средах сопряжено с определёнными рисками, о которых следует знать разработчикам и администраторам, чтобы обезопасить свои системы и данные. Протокол MCP представляет собой интерфейс, который позволяет LLM выполнять операции, взаимодействовать с базами данных, системами мониторинга и другими внешними сервисами. Таким образом, MCP может существенно расширить функциональность интеллектуальных агентов, превращая их из пассивных помощников в активных инструментов для решения сложных задач.
В то же время, активное взаимодействие LLM с внешними инструментами требует осознанного подхода к безопасности, особенно при работе с критически важными данными. Одна из главных проблем при использовании MCP — это уязвимость к так называемым атакам внедрения подсказок (prompt injection). Это особый вид уязвимости, при котором злоумышленник использует пользовательский ввод для манипулирования поведением языковой модели. Например, если пользователь сможет включить в свой запрос команду для выполнения несанкционированного действия, такая команда будет обработана LLM как легитимная инструкция. В результате злоумышленник может вызвать выполнение нежелательных запросов к базе данных или утечку конфиденциальной информации.
Случай с Supabase продемонстрировал, как легко можно случайно раскрыть конфиденциальные данные через MCP. В этой ситуации через форму технической поддержки злоумышленник отправил специально сформулированное сообщение — своеобразный «троянский конь» для LLM. Когда разработчик использовал AI-помощника для обработки этих запросов, модель принимала вредоносные инструкции как часть своей рабочей задачи и выставляла конфиденциальные данные в открытом доступе. Такая ситуация стала причиной масштабных дискуссий в сообществе и подтолкнула к поиску методов безопасного внедрения MCP в рабочие процессы. Прежде всего, чтобы минимизировать риски, крайне важно ограничивать права доступа LLM при работе с внешними источниками.
Использование MCP в режиме строго чтения — один из самых эффективных способов снизить опасности. При таком подходе модель может выполнять только безопасные операции выборки данных, исключая возможность изменять информацию или выполнять команды, которые могут негативно повлиять на систему. Этот метод работает как своего рода «защита от дурака», предотвращая привлечение модели к действиям, способным навредить целостности или конфиденциальности данных. Ещё одним важным аспектом является тщательный контроль контекста, который передается LLM. Поскольку современные языковые модели не способны однозначно отличать инструкции от пользовательских данных, возникает необходимость разработки фильтров и алгоритмов, которые смогут выделять и блокировать потенциально опасные фрагменты входящей информации.
Это напоминает эпоху раннего интернета и проблемы с SQL-инъекциями, когда неконтролируемый ввод приводил к опасным последствиям. Сегодня похожие вызовы стоят перед разработчиками систем искусственного интеллекта и сервисов на базе MCP. Стоит отметить, что применение MCP сегодня зачастую ограничено сценариями разработки и экспериментальной средой. Многие MCP-серверы используются для помощи разработчикам в кодировании и интеграции с внешними API, что позволяет существенно повысить эффективность работы и качество программных продуктов. Однако внедрение MCP в полноценные публичные приложения с доступом к важным данным требует повышенного внимания.
Некоторые компании уже начинают интегрировать MCP в свои производственные инструменты, создавая, например, кодогенераторы или приложения для личного пользования, где предполагается минимальный риск компрометации. Такие проекты демонстрируют, что если правильно настроить права доступа и ограничить возможности моделей, можно получить значительные преимущества без излишнего риска. В будущем безопасность MCP будет укрепляться за счёт внедрения новых методов авторизации с точным разграничением прав, а также внедрения средств песочницы для исполнения команд, что позволит обезопасить критические операции от неоправданных вмешательств модели. Кроме того, развитием технологий займутся исследователи, работающие над созданием внутренних фильтров для снижения угрозы prompt injection и других атак. Применение прокола MCP – это уже не просто эксперимент, а конкретный инструмент, который способен улучшить взаимодействие человека и техники, повысить производительность и автоматизировать рутинные операции.