В мире кинематографа рейтинги фильмов играют важную роль не только для зрителей, но и для профессионалов отрасли, маркетологов, критиков и исследователей. Одним из наиболее авторитетных и популярных источников является сайт IMDb, на котором пользователи по всему миру выставляют оценки фильмам по шкале от 1 до 10. Средняя оценка фильма, рассчитанная на основе миллионов голосов, служит своеобразным индикатором восприятия фильма аудиторией и нередко влияет на его дальнейшую судьбу. Однако именно прогнозирование этой средней оценки становится сложной задачей, учитывая огромный объем и разнообразие информации о фильмах, а также субъективность оценок пользователей. Современные технологии искусственного интеллекта и машинного обучения открывают новые возможности для решения таких задач.
Одним из перспективных направлений является использование текстовых эмбеддингов — численных векторов, которые представляют текстовую информацию в формате, удобном для обработки алгоритмами. На их основе можно создавать модели, способные выявлять сложные взаимосвязи в метаданных фильмов и строить прогнозы качества кинопроизведений. В своей работе многие исследователи обращаются к открытым наборам данных IMDb, которые включают различные таблицы с информацией о фильмах, жанрах, актёрах, режиссерах, бюджетах и других характеристиках. Несмотря на достаточно ограниченный набор доступных признаков в открытых данных, современные методы обработки текста позволяют извлечь более глубокое смысловое содержание из имеющихся сведений, что значительно улучшает предсказательную способность моделей. Традиционные подходы к построению моделей прогнозирования рейтингов фильмов часто основываются на ручном отборе и преобразовании признаков: возраст фильма, жанры, наличие известных актёров, временная продолжительность и другие параметры.
Такие модели могут быть реализованы с помощью линейной регрессии, градиентного бустинга и нейронных сетей. Однако учитывая огромную размерность данных и сложность взаимосвязей, эти методы порой оказываются недостаточно эффективными или слишком трудоемкими. Здесь на сцену выходят большие языковые модели (Big Language Models, LLMs), способные работать с большим объемом текстовой информации и создавать осмысленные представления в виде эмбеддингов. В отличие от классического кодирования категориальных признаков с помощью методов бинарного разложения или частотного кодирования, LLM учитывают контекст, синтаксис и даже семантические связи между элементами данных. Это позволяет не просто численно представить факты, но и уловить тонкие нюансы, например, важность позиции актёрского состава или особенности названия и описания фильма.
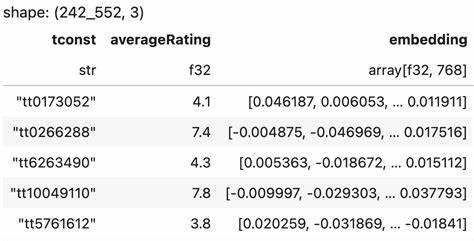
При обработке метаданных фильмов с помощью LLM сначала происходит агрегация и денормализация информации — режиссёры, актёры, продюсеры и прочие участники проекта собираются в структурированный текстовый или JSON-формат, отражающий основные характеристики фильма. Далее этот текст подается на вход модели, которая вырабатывает 768-мерный эмбеддинг, фиксированный вектор, представляющий фильм с учётом всей предшествующей информации. Преимущество таких эмбеддингов заключается в их универсальности. Они могут использоваться для поиска похожих фильмов, рекомендаций и, главное, построения регрессионных моделей для предсказания рейтингов. Исследования показывают, что традиционные методы, применяемые к эмбеддингам, такие как линейная регрессия, машины опорных векторов и даже простые многослойные нейронные сети, демонстрируют высокую точность прогноза.
Особое внимание уделяется выбору и тренировке моделей. Линейная регрессия служит отличным базовым уровнем, показывая приемлемые результаты. Однако более гибкие алгоритмы, в частности Support Vector Machines (SVM), позволяют снизить ошибку предсказания и повысить качество оценки. В то же время многослойные перцептроны с несколькими слоями и регуляризацией способны уловить более сложные взаимосвязи, хотя иногда сталкиваются с проблемами переобучения, что требует тщательной настройки гиперпараметров и применения техник, таких как дропаут. Интересно, что попытки обучения языковой модели с нуля на данных, специфичных для кинематографа, тоже показали приемлемый уровень точности.
Такие модели адаптированы к особенностям внешних данных и достигают результатов даже лучше, чем использование предобученных эмбеддингов. Однако создание собственной языковой модели требует значительно больше вычислительных ресурсов и глубоких знаний в области машинного обучения. Визуализация эмбеддингов с помощью методов снижения размерности, таких как UMAP или PCA, демонстрирует, что модели действительно фиксируют смысловые кластеры фильмов. По расположению точек можно увидеть группировку по жанрам, годам выпуска и даже качеству фильма, что дополнительно подтверждает полезность эмбеддингов как инструмента анализа. Стоит отметить, что несмотря на широкий потенциал, работа с данными IMDb имеет ряд ограничений.
Прежде всего, доступные наборы данных часто имеют неполную и ограниченную информацию, что влияет на качество моделей. Кроме того, использование числа голосов как признака может привнести искажение, так как популярность не всегда коррелирует с качеством. Поэтому, в большинстве исследований отсекаются фильмы с малым числом голосов для обеспечения надежности. С точки зрения практики, применение методов на основе текстовых эмбеддингов открывает новые горизонты в области создания рекомендаций и анализа фильмов. Компании могут использовать такие модели для прогноза успешности кинопроектов, а исследователи — для более глубокого понимания связи между творческими элементами и восприятием публики.