В мире современных технологий стабильность и качество работы искусственного интеллекта играют ключевую роль в формировании доверия пользователей и эффективности приложений. В августе и начале сентября 2025 года пользователи Claude, одного из ведущих языковых моделей, начали замечать снижение качества генерируемых ответов. Анализ причин выявил сразу три инфраструктурных ошибки, каждая из которых по-своему влияла на работу системы, создавая трудности в диагностике и устранении проблем. Этот разбор подробно посвящен тому, что именно произошло, почему исправление заняло время, и какие выводы были сделаны для предотвращения подобных инцидентов в будущем. Claude - это модель, доступная миллионам пользователей по всему миру через собственный API Anthropic, а также через платформы Amazon Bedrock и Google Cloud Vertex AI.
Чтобы выдерживать высокие нагрузки и обеспечивать глобальный охват, Claude запускается на разном аппаратном обеспечении, включая AWS Trainium, NVIDIA GPU и Google TPU. Каждая из этих платформ обладает уникальными характеристиками, требующими отдельных оптимизаций. Несмотря на это, качество ответов должно оставаться единым - пользователь не должен заметить разницы в зависимости от выбранного сервера или оборудования. Именно это условие создает повышенную сложность для разработчиков и операционных команд, особенно при внедрении обновлений. Основные события развертывались в августе 2025 года.
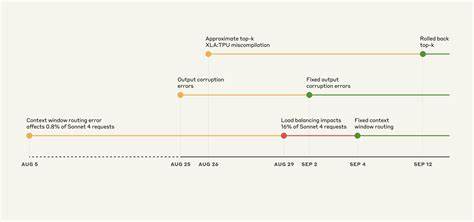
Первая из трех проблем появилась 5 августа и касалась маршрутизации запросов - часть обращений, предназначенных для сервера с одной конфигурацией контекста, отправлялись на сервер с другой, предназначенной для значительно более длинных текстов. Вначале это затронуло около 0,8% запросов. Однако 29 августа внесенные изменения в балансировку нагрузки привели к росту этой доли до 16% причем эффект был нерегулярным, что вызывало противоречивые отзывы пользователей. Такая "липкая" маршрутизация означала, что пользователь, получивший неправильный ответ, мог столкнуться с повторением проблемы при последующих обращениях. Исправление было внесено к началу сентября и успешно развернуто на всех платформах к середине месяца.
Вторая проблема возникла 25 августа, связанная с ошибкой конфигурации на TPU-серверах Claude API. Эта ошибка напрямую влияла на генерацию токенов, что приводило к появлению неподходящих символов и даже фрагментов текста на других языках, например на тайском или китайском, в ответах на английские запросы. В ряде случаев появлялись явные ошибки в синтаксисе кода, что сильно мешало пользователям, работающим с Claude Code. Упомянутая ошибка затрагивала различные версии модели, включая Opus 4 и Sonnet 4, и была решена путем отката обновления к началу сентября. Кроме того, с тех пор процесс развертывания был дополнен тестами, которые отслеживают подобные неожиданные символы.
Третья и, пожалуй, одна из самых сложных для диагностики проблем касалась компилятора XLA для TPU. В тот же период была внедрена оптимизация алгоритма выбора токенов во время генерации текста. Однако это привело к активации скрытой ошибки в самом компиляторе, проявляющейся в некорректной работе операции approximate top-k, отвечающей за быстрое выявление наиболее вероятных токенов для следующего шага. Ошибка носила нерегулярный характер, зависела от многих факторов - от конфигурации батча до наличия отладочных инструментов, что значительно усложняло локализацию проблемы. Неоднократно было замечено, что в некоторых случаях наиболее вероятный токен вовсе выпадал из рассмотрения, приводя к искажению ответа модели.
Для устранения была возвращена более точная операция exact top-k, несмотря на то, что она менее эффективна по производительности. Передача информации и сотрудничество с инженерами компилятора XLA позволили заложить основы для исправления на стороне TPU. Все эти проблемы были особенно трудны для обнаружения из-за ряда факторов. Во-первых, внутренние процессы валидации и тестирования на основе бенчмарков и масштабируемых метрик не давали однозначных предупреждений, поскольку модель часто "спасала" отдельные ошибки, благодаря своей устойчивости. Во-вторых, политика конфиденциальности пользователя ограничивала возможность анализа конкретных случаев низкокачественных ответов, что затрудняло восстановление сценариев, приводящих к ошибкам.
В-третьих, распараллеленный характер работы AI на различных платформах приводил к смешанным и противоречивым сигналам о проблемах, причем их проявление и интенсивность менялись без очевидной закономерности. Не менее важной причиной задержки с исправлением стала недостаточная связь между внешними откликами пользователей и внутренними изменениями инфраструктуры. В частности, всплеск жалоб после изменения балансировки нагрузки 29 августа долго не ассоциировался с технической причиной. Это недооценивание сигналов негативного опыта пользователей выявило необходимость улучшения системы мониторинга. В ответ на произошедшее команда Anthropic объявила о серьезных изменениях в процедуре контроля качества.
Во-первых, были разработаны более чувствительные методы оценки, способные четче выявлять различия между корректной и искаженной работой модели. Во-вторых, практика проведения качественных проверок была расширена и теперь включает постоянный мониторинг в живом производстве, что даст возможность обнаруживать потенциальные проблемы в режиме реального времени. Кроме того, уделяется повышенное внимание развитию инструментов для оперативного анализа обратной связи от сообщества пользователей без ущерба для конфиденциальности. Это позволит быстрее локализовать причины ухудшения качества. Вдохновляясь вкладом сообщества, команда призывает пользователей концентрироваться на конкретных деталях и примерах проблемных ответов, что значительно помогает в идентификации узких мест и нестандартных ошибок.
Для этого доступны удобные точки сбора ошибок, такие как команды /bug и кнопки обратной связи в приложениях Claude. В свете вышеперечисленных инцидентов становится очевидно, что работа крупномасштабных систем искусственного интеллекта - это сложный синтез аппаратных архитектур, программных оптимизаций и жестких требований к качеству. Малейший сбой на одном из этапов может привести к ухудшению пользовательского опыта, что требует скорости реакции и системного подхода к решению проблем. Опыт Claude в 2025 году подчеркивает необходимость постоянного совершенствования диагностических методик, расширения зоны мониторинга и взаимодействия с сообществом. Итоги этих событий напоминают индустрии, насколько важна прозрачность и открытость в коммуникации с пользователями.
Подробные технические отчеты и публичные разборы ошибок не только повышают доверие клиентов, но и стимулируют развитие лучших практик. Для любых технологий, особенно в сфере искусственного интеллекта, такие подходы становятся залогом успешного будущего и устойчивого роста. В целом, недавно произошедшие проблемы с Claude можно рассматривать как полезное испытание стабильности системы и подтверждение того, что непрерывное улучшение процессов и партнерское отношение к сообществу - ключевые составляющие качества на современном цифровом рынке. .