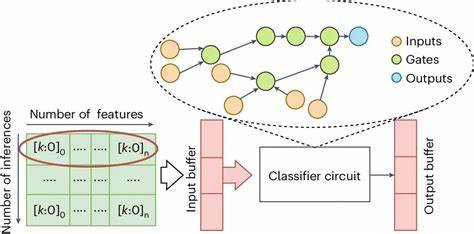
Искусственный интеллект и машинное обучение представляют собой одни из самых динамичных и быстроразвивающихся областей современного программирования. Несмотря на множество доступных фреймворков и библиотек, глубокое понимание фундаментальных принципов нейросетей имеет важное значение. Однако зачастую изучение основы уходит на второй план из-за огромного объема материала и сложных концепций, что приводит к тому, что многие разработчики ограничиваются использованием готовых инструментов. В этой статье мы познакомимся с реализацией простейшего классификатора - Tiny Classifier на языке C++, который можно считать настоящим учебным проектом для освоения важнейших нюансов нейронных сетей и их обучения с помощью градиентного спуска. Tiny Classifier представляет собой модель, которая способна определять принадлежность географических координат к определённому городу, используя простую сеть из нескольких нейронов.
Проект наглядно демонстрирует, как соединить теорию и практику, воспроизводя ключевые моменты из серии обучающих видео от Welch Labs, посвящённых обучению нейронных сетей с обратным распространением ошибки и функции активации softmax. В центре внимания - две задачи классификации. Первая - одновыходная, работает с одним входным параметром (долгота) для трех городов, вторая - двумерная, учитывает как долготу, так и широту для четырех городов. За счёт грамотной организации кода на С++ достигается универсальность: одна и та же реализация модели подходит для обеих задач без существенных изменений, что позволяет более глубоко понять структуру и механику работы нейросетей. Первым шагом является подготовка обучающих данных.
В качестве входных параметров используются географические координаты различных точек четырёх европейских городов - Мадрида, Парижа, Берлина и Барселоны. Эти данные представлены в виде массивов с плавающей точкой, что обеспечивает удобство обработки и масштабирования. Кроме того, случайный выбор координат из списка каждой локации имитирует разнообразие реальных входных сценариев, что способствует лучшему обобщению модели. Структура нейрона, реализованного в коде, включает в себя веса и смещение (bias). Веса инициализируются случайными значениями из равномерного распределения в диапазоне от -1 до 1, что способствует случайному старту обучения и предотвращает переобучение на начальном этапе.
Смещение также задаётся случайно, что является отклонением от классической практики и служит для расширения пространства поиска оптимальных параметров. Основной этап вычислений - применение функции умножения (dot product) между входным вектором и весами нейронов с добавлением смещения. Эта операция даёт определённое числовое значение, отражающее активацию нейрона. Для всей сети выполняется массовая процедура этого типа, результатом которой становится массив значений, по сути, "поток активаций" для каждого из городов-классов. Обязательно стоит отметить применение функции softmax к выходным данным.
Softmax преобразует произвольные числовые значения в вероятностное распределение, где сумма всех вероятностей равна единице. Это позволяет просто интерпретировать выход сети как вероятность того, что введённая координата принадлежит к конкретному городу. Обработка отрицательных и больших чисел в функции softmax реализована с использованием предельного ограничения (cap) в 80 для предотвращения переполнения экспоненты - важный технический нюанс, обеспечивающий стабильность вычислений. Для оценки текущей производительности модели применяется метрика потерь - кросс-энтропия, которая измеряет расхождение между предсказанным распределением вероятностей и реальным классом. Эта метрика не используется напрямую при корректировке весов, но служит важным индикатором эффективности обучения.
Обратное распространение ошибки реализовано через вычисление производных (градиентов) по параметрам модели. Для нейронов расчёт производной представлен как в отдельности для смещения, так и для весов. Производная для bias принята равной единице, что является отклонением от классического подхода, но здесь обосновано необходимостью корректного обновления параметра. Рассчитывается также производная функции softmax, которая упрощена до вычитания единицы из вероятности правильного класса, а остальные элементы оставлены без изменений, что эффективно моделирует направление коррекции. Эти значения комбинируются, образуя вектор градиента, который сигнализирует, в какую сторону нужно изменить параметры модели, чтобы минимизировать ошибку.
Для численного обновления весов используется простой механизм умножения градиента на параметр обучения (alpha) с последующим вычитанием из текущих весов. Этот процесс имитирует спуск по наклону (градиентный спуск) по функции ошибки, позволяя модели постепенно приближаться к оптимальному состоянию. Помимо базовых вычислений, в реализации заложена система отслеживания производительности, основанная на экспоненциальном скользящем среднем с несколькими параметрами сглаживания. Это позволяет видеть тенденции в точности и ошибках модели на различных временных масштабах: от краткосрочных изменений до долгосрочных результатов. Обучение модели отображается подробными логами, показывающими почти в реальном времени эволюцию коэффициентов точности, значений потерь и параметров нейронов.
При начале с реальных исходных параметров обучение происходит быстро - за несколько сотен итераций. При рандомной инициализации параметров обучение требует гораздо большее количество шагов, но всё равно завершается успешно, что свидетельствует о надежности и универсальности подхода. Для пользователей доступна отдельная часть кода, отвечающая за выбор случайных примеров из доступного набора данных, что также демонстрирует принципы обобщения и случайного дрейфа в обучении современных моделей. Tiny Classifier - это не просто учебный проект, а полноценная демонстрация архитектуры и принципов работы простейшей однослойной нейросети с обучением на реальных данных. Благодаря своевременному применению новых возможностей языка C++ 17 и выше, включая constexpr и сложные шаблоны, код остаётся лаконичным и в то же время максимально гибким.
Для разработчиков и исследователей, которые хотят углубиться в тему искусственного интеллекта, такой проект является важной отправной точкой. Tiny Classifier служит отличным примером, позволяющим наглядно изучить составляющие нейросетевого обучения: подготовку данных, прохождение сигнала вперёд, вычисление функции активации, оценку потерь, вычисление градиента и обновление параметров. Это помогает не только научиться программировать подобные модели на C++, но и лучше понять математику и логику, лежащие в основе глубокого обучения. Кроме того, простота и прозрачность реализации стимулирует экспериментирование: изменение параметра обучения, количества итераций или начальной инициализации веса позволяет наблюдать, как меняется качество модели. Эта обратная связь крайне полезна для развития интуиции работы с ИИ-системами.
Tiny Classifier доказывает, что нейронные сети - это не только комплексные и громоздкие системы, но и простые конструкции, которые можно реализовать с нуля на привычных языках программирования. Такой подход становится не только эффективным инструментом для обучения, но и отличной базой для последующего развития и масштабирования более сложных моделей. В целом, обучение нейросети с использованием Tiny Classifier на C++ становится прекрасной возможностью не только познакомиться с основами искусственного интеллекта, но и закрепить полученные знания практическим опытом, что немаловажно в условиях современной эволюции технологий и постоянного роста спроса на экспертов в сфере машинного обучения. .