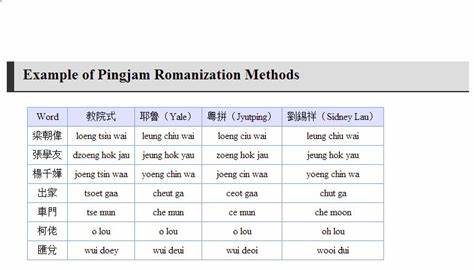
Кантонский язык, один из самых распространённых диалектов китайского с более чем 80 миллионами носителей, на протяжении долгих лет оставался вызовом для автоматизированных систем трансформации иероглифов в латинскую транслитерацию, особенно в системе, известной как Жютпин (Jyutping). Это связано с высокой полифоничностью и сложной структурой этого языка, которая делает процесс конвертации очень трудоёмким и неоднозначным. Несмотря на яркую естественность восприятия и произношения для носителей языка, компьютерные алгоритмы долгое время не могли достичь приемлемой точности, необходимой для широкой практической реализации. Однако, начиная с 2024 года, ситуация начала кардинально меняться благодаря прорывным методам и глубокому анализу проблематики. Особенность кантонского языка заключается в том, что один китайский иероглиф может иметь до десяти различных произношений в зависимости от контекста.
Это порождает экспоненциальный рост количества возможных комбинаций при попытке автоматически подобрать верное чтение для текста из нескольких символов. Например, короткая фраза из десяти иероглифов может давать более 18 тысяч возможных вариантов прочтения, а при расширении текста количество ошибок и несовпадений становится практически неуправляемым. В этом и заключается трудноразрешимая на первый взгляд задача преобразования графем в фонемы – так называемая проблема G2P (grapheme to phoneme). Главная сложность автоматизации связана не только с количеством вариаций, но и с тем, что кантонский язык тесно переплетён с историей, культурой, региональными особенностями и влиянием других диалектов и языков. Благодаря тысячелетнему историческому опыту, на одни и те же иероглифы существует несколько прочтений – литературных, разговорных, исторических и даже региональных.
Вкупе с отсутствием официальных стандартов и традиционным упорством населения в использовании устоявшихся устных норм, подчас с большими различиями, сделать универсальный алгоритм, способный точно воспроизводить звучание, было крайне сложно. Одна из важных особенностей языковой системы — вариативность между стандартизированным письменным китайским языком и местным кантонским произношением, которые порой переплетаются в рамках одного текста. Часто сложно определить, какого именно прочтения ожидает автор, поскольку речь идет о смешении больших пластов культурного наследия и повседневной коммуникации. Это делает автоматическую транслитерацию в Jyutping ещё более сложной, ведь требуется понимание не только лексики, но и стилистических и социокультурных нюансов, чтобы верно определить значение и звучание каждого знака. Ранее существовали попытки создания автоматизированных систем на основе правил, где каждое слово или символ сопоставлялся с набором заранее прописанных вариантов чтения.
Такие системы, например PyCantonese и ToJyutping, работали довольно быстро, однако их точность оставляла желать лучшего. Более того, в них была проблема отсутствия универсального ориентира по оцениваемой точности, что сильно затрудняло их развитие и широкое применение. Анализ результатов показывал высокий уровень ошибок, который делал невозможным использование этих систем в профессиональных и научных областях. С появлением новых технологий, в частности больших языковых моделей (LLM), ситуация стала меняться, но и они не решили проблему полностью. Несмотря на то, что современные ИИ способны обрабатывать огромные объемы данных, они по-прежнему страдают от недочётов, таких как нестабильность результатов, зависимость от объёма и качества обучающей базы и сложности с точным разграничением кантонского произношения от влияние других диалектов.
Модели вроде GPT или Claude нередко делали ошибки, которые для носителей языка были очевидны и неприемлемы. Основополагающим достижением последних лет стало создание Cantonese Font — специализированного шрифта и системы, которая решает проблему Jyutping-присвоения с феноменальной точностью, достигающей более 99%. Этот подход базируется на глубоком погружении в лингвистический контекст, а также на создании обширных и тщательно выверенных баз данных с референсными ответами, что позволило формально выстроить процесс автоматического выбора верного произношения. Такой уровень точности существенно опережает предыдущие системы, снижая количество ошибок в десятки и сотни раз и делая процесс романизации практически безошибочным для большинства практических случаев. Инженерная реализация Cantonese Font основана на многоуровневом наборе правил с системой приоритетов.
Каждому иероглифу из большой базы присваивается дефолтное чтение, которое может корректироваться в зависимости от контекста и особенностей соседних символов. Этот механизм учитывает не только локальную среду рядом стоящих слов, но и макроуровень сегментации текста, позволяя.handle сложные случаи литературных и разговорных форм, заимствованные термины и исторические нарративы. Использование OpenType технологий в шрифте позволило гарантировать высокую производительность и взаимодействие с современными типографическими движками. Подобные результаты стали возможными благодаря систематическому подходу к решению проблемы: вместо попыток создать универсальную модель, пытающуюся сразу учесть все тонкости, процесс был разбит на управляемые стадии — классификация фрагментов текста по стилю, выявление локальных языковых особенностей, точная сегментация слов и фраз, поэтапная коррекция чтения и регулярное обновление базы знаний с учётом новых данных.
Такое многослойное построение позволило последовательно повышать точность, минимизировать сбои и обеспечить предсказуемое поведение системы. Автоматизация романизации кантонского языка открывает новые перспективы в области образования, исследований и цифровых технологий. Возможность быстро и качественно получать точную транслитерацию облегчает подготовку обучающих материалов, разработки систем для слабовидящих, автоматическую генерацию субтитров и улучшает качество распознавания речи. Расширение баз данных и сбор статистики позволяют понять частотность использования различных вариантов произношения и выстроить эффективные планы обучения для изучающих язык, выделить основные наборы символов и предпочтительные чтения. Кроме того, высокая точность Jyutping-транслитерации способствует интеграции кантонского языка в более широкий технологический контекст.
Это касается создания систем машинного перевода, улучшения голосовых ассистентов и развития возможностей мультимодального взаимодействия. Также появляется уникальная возможность исследовать исторические и культурные пласты, соотнося древние формы с современными, и таким образом сохранить традиции и сделать язык более доступным для будущих поколений. Особым достижением является способность системы не только оперировать стандартными формами, но и гибко адаптироваться к вариациям, типичным для устного языка, просторечий, диалектных особенностей и заимствований. Это делает инструмент максимально приближенным к живой речи и культуре, что крайне важно в ситуации, когда письменный кантонский язык не имеет жёсткой нормативной базы. В будущем перспективы автоматической романизации выглядят ещё более обнадеживающими.
Планируется дальнейшее расширение лингвистической базы, внедрение методов машинного обучения там, где правило работает недостаточно, и создание полноценных интерактивных инструментов корректировки и обучения. Эти технологии не только помогут профилю профессионалов в области языка и IT, но и откроют новые возможности для обычных пользователей, желающих изучить и применять кантонский язык. Автоматизация романизации кантонского языка стала возможной благодаря синергии глубокой лингвистической экспертизы, системного подхода к обработке сложных языковых структур и современных технологических решений. Результаты показывают, что даже самые запутанные и многогранные лингвистические задачи могут быть успешно решены при условии терпения, творческого подхода и объединения усилий специалистов разных областей. Система, подобная Cantonese Font, не просто ломает барьеры в изучении языка, а прокладывает путь к более широкой дигитализации и сохранению уникального культурного наследия.
Таким образом, современная автоматизация трансформирования кантонского текста в романизированную форму открывает новую эру для изучающих, исследователей и всех, кому важен этот язык. Она демонстрирует, что сложные задачи, кажущиеся неразрешимыми, при правильном подходе становятся достижимы — меняя наше восприятие возможностей языковых технологий и формируя прочную основу для будущих инноваций.