В современном мире распределённых систем и микросервисов технология gRPC стала одним из ключевых инструментов для организации высокопроизводительного взаимодействия между сервисами. Её популярность обусловлена использованием протокола HTTP/2, поддержкой двунаправленных потоков, а также встроенными механизмами сериализации и десериализации данных. Несмотря на универсальность и мощь gRPC, в процессах нагрузки и тестирования баз данных с использованием gRPC часто возникают неожиданные проблемы с производительностью, особенно в условиях сетей с минимальной задержкой. Одним из таких явлений является узкое место со стороны клиента, которое серьезно ограничивает пропускную способность и увеличивает клиентскую задержку, что звучит парадоксально для сетей с отличными показателями RTT и отсутствием проблем на уровне TCP. На примере базы данных YDB, открытого проекта, реализующего распределённый SQL с поддержкой ACID-транзакций, была выявлена именно такая проблема: с уменьшением количества нод кластера возникало увеличение простоя серверных ресурсов и одновременно выросла задержка на стороне клиента.
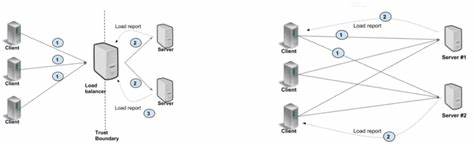
Проводимый анализ позволил локализовать источник проблемы на клиентской стороне gRPC, что стало неожиданным открытием, так как большинство разработчиков и инженеров привыкли считать, что узкие места обычно связаны с сервером, сетью или оборудованием. Для лучшего понимания причины необходимо учитывать архитектуру и тонкости реализации gRPC клиента. gRPC работает поверх HTTP/2, где каждый канал gRPC соответствует TCP-соединению, по которому может передаваться множество потоков RPC. При этом, если не задавать специальные аргументы при создании каналов, то несколько каналов могут по умолчанию использовать один и тот же TCP-сокет, что приводит к мультиплексированию запросов на одном соединении. При нагрузках с высокой параллельностью возникает лимит на число одновременных потоков HTTP/2 в одном TCP-соединении, стандартно равный 100, что ведёт к очередям и ожиданиям на стороне клиента.
Популярные рекомендации в документации gRPC предлагают создавать отдельный канал для каждого узла нагрузки или использовать пул каналов с разными конфигурациями, чтобы равномерно распределять трафик. Однако в реальных условиях и особенно при использовании небольшого числа нод, этого оказывается недостаточно. В YDB были проведены глубокие эксперименты с использованием собственного микробенчмарка grpc_ping на C++, который имитирует минимальный RPC-пинг без нагрузки по полезной нагрузке для изоляции узких мест системы. Это позволило точно измерять скорость отклика и пропускную способность с применением различных режимов работы клиента и сервера. Тестирование на реальном железе с мощными процессорами Intel Xeon Gold и 50 гигабитным сетевым соединением с низкой задержкой (<0.
05 мс) показало интересную картину. При увеличении числа параллельных запросов задержка на клиенте росла пропорционально, а пропускная способность не масштабировалась линейно, что противоречило ожиданиям для высокопроизводительной системы. Анализ сетевых пакетов выявил отсутствие проблем с TCP (отключённые алгоритмы Nagle, отсутствие задержек с ACK, адекватный размер окна) и быстродействие сервера — причина оказалась в задержках внутри gRPC-клиента, связанных с обработкой и планированием потоков и очередей в одном TCP-соединении. Решением стало использование множества TCP-соединений, где каждому рабочему потоку клиента (worker) соответствует собственный gRPC-канал с уникальными параметрами, что исключает совместное использование одного TCP-соединения и описанный эффект очередей HTTP/2. Введение аргумента GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL способствует распределению каналов по TCP-соединениям, уменьшая внутреннюю конкуренцию.
В итоге удаётся добиться значительного прироста пропускной способности — до шестикратного для обычных вызовов и почти в пять раз для стриминговых запросов. Задержки растут гораздо медленнее, что упрощает масштабирование и эксплуатацию систем с высокой нагрузкой и требованиями к минимальной задержке. Отдельно интересна ситуация, когда сеть не демонстрирует сверхнизкой задержки, а RTT составляет порядка 5 мс. Там влияние клиентской узкой точки существенно снижается, и различия между одним или несколькими соединениями становятся менее заметными. Это говорит о том, что описанный клиентский узел является критическим именно в современных датацентрах и частных системах с очень быстрым сетевым взаимодействием, где минимальные технические накладные внутреннего ПО дают сильный эффект.
Данный кейс из реального мира подчёркивает важность комплексного подхода к измерению производительности, в котором не только железо и сетевые параметры, но и особенности реализации протоколов и библиотек на клиентской стороне имеют решающее значение. Он демонстрирует, что известные рекомендации по gRPC каналам — не два альтернативных пути, а последовательные фазы одного решения. Использование множества каналов с индивидуальными настройками является оптимальным способом устранить внутренние узкие места и раскрыть потенциальные возможности высокоскоростной сети. Для разработчиков распределённых баз данных, микросервисных архитектур и высокоскоростных коммуникаций это очень важное заметное улучшение. Оно позволяет добиться одновременно высокой пропускной способности и минимальных задержек, что критично для многих приложений — от финансовых транзакций и реального времени до больших массивов данных и аналитики.