Визуализация данных продолжает играть решающую роль в современном анализе и интерпретации больших объемов информации. Сложные данные необходимо представлять в форме, которая облегчает понимание и выявление важных закономерностей для специалистов и широкой аудитории. В последние годы большие языковые модели, такие как GPT и их аналоги, зарекомендовали себя как мощные инструменты во многих сферах, включая генерацию текста, кодирование, перевод и обработку естественного языка. Одной из новых и перспективных областей применения больших языковых моделей стало создание визуализаций данных и анализ их с помощью естественного языка. Это направление становится все более актуальным, учитывая потенциал LLM автоматизировать и упростить процесс генерации кода для визуализации, а также возможность отвечать на вопросы, связанные с интерпретацией графиков и диаграмм.
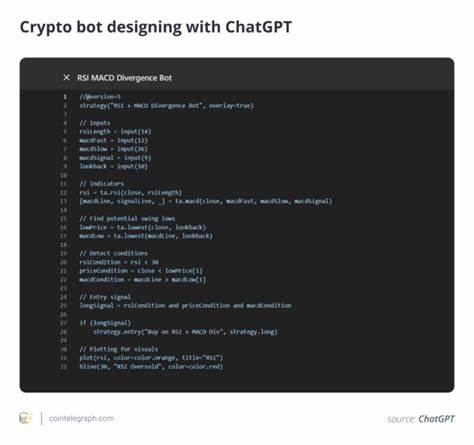
Большие языковые модели обладают способностью понимать и интерпретировать текстовые запросы, преобразуя их в программный код на популярных языках и библиотеках визуализации, таких как Python с Matplotlib, Seaborn или JavaScript с D3.js. Это открывает новые горизонты для специалистов и пользователей, которые не обладают глубокими техническими знаниями. Вместо сложного кодирования можно использовать простые текстовые подсказки, что сокращает время и усилия на создание информативных графиков и диаграмм. В ряде исследований, таких как работа Саадика Рауфа Хана и коллег, подтверждается, что современные LLM способны успешно генерировать корректный и полезный код визуализации на основе текстовых инструкций.
Однако, несмотря на впечатляющие результаты, они также демонстрируют определенные ограничения.Основное преимущество использования больших языковых моделей для визуализации – это возможность автоматизации и упрощения процесса создания графиков. Особенно полезны они для быстрого прототипирования, когда необходимо визуализировать данные для первого анализа или презентации. LLM способны не только формировать изображения, но и корректировать код в зависимости от уточнений пользователя, что значительно облегчает итеративный процесс создания визуализаций. Более того, модели могут анализировать существующие визуализации, отвечая на вопросы о значениях, трендах или аномалиях, что повышает интерактивность и глубину анализа данных с помощью естественного языка.
Тем не менее, при использовании LLM для решения задач визуализации выявляются и некоторые ограничения. Во-первых, качество генерируемого кода зависит от сложности исходного запроса и конкретных данных. Для сложных задач или нестандартных визуализаций модели могут создавать менее оптимальный или ошибочный код, требующий ручной доработки. Также LLM иногда испытывают трудности с пониманием контекста и специфики данных, что может приводить к неточным или вводящим в заблуждение графикам. Еще одной проблемой является ограниченность возможностей моделей в обработке визуальных элементов напрямую, так как они в основном рассчитаны на работу с текстом, а не с изображениями.
Это сказывается на точности интерпретации сложных визуализаций и требует интеграции с другими специализированными системами.Важной областью развития является улучшение взаимодействия между большими языковыми моделями и системами информационной визуализации. Оптимизация методов генерации кода, создание более интеллектуальных подсказок и обучение моделей на специализированных наборах данных может повысить точность и качество создаваемых визуализаций. Благодаря тесному взаимодействию LLM с визуализационными инструментами можно достичь более высокой адаптивности и гибкости в работе с различными типами данных и запросами, что особенно актуально для бизнес-аналитики, научных исследований и образования.Перспективы включают интеграцию больших языковых моделей в пользовательские интерфейсы визуализации, где пользователи смогут общаться с системами при помощи естественного языка для создания и настройки графиков в реальном времени.
Такой подход способствует демократизации доступа к аналитическим инструментам и расширяет возможности непрофессионалов работать с большими данными. Помимо этого, LLM могут служить вспомогательным инструментом при обучении информационной визуализации, помогая пользователям лучше понимать принципы построения графиков, грамотно формулировать запросы и анализировать результаты.В целом, оценка возможностей больших языковых моделей в задачах визуализации демонстрирует значительный потенциал и успешность в решении многих прикладных задач. Современные LLM упрощают процесс создания визуализаций, делают его доступнее широкому кругу пользователей и повышают уровень взаимодействия с данными посредством естественного языка. Одновременно с тем, выявленные ограничения и проблемы указывают на направления дальнейших исследований и усовершенствований, которые необходимы для повышения точности, надежности и эффективности таких систем.
Постоянный прогресс в области искусственного интеллекта и интеграция с новыми технологиями обеспечат будущее развитие и расширение применения больших языковых моделей в информационной визуализации и анализе данных.