Обучение крупных языковых моделей традиционно связано с серьезными затратами как на вычислительные ресурсы, так и на финансовое обеспечение. Большинство современных решений требуют дорогостоящих GPU-кластеров с объемной видеопамятью, что делает процесс недоступным для небольших и средних исследовательских групп и компаний. Однако инновационный метод блочного покоординатного спуска (BCD) открывает новые возможности для дешевого и эффективного обучения моделей даже на относительно скромных кластерах, оснащенных видеокартами, такими как RTX 4090, A100 или A800. В этой публикации рассмотрим, как использовать BCD для снижения затрат при сохранении высокой производительности и точности моделей, а также обсудим ключевые оптимизации, позволяющие добиться выдающихся результатов на бюджетном оборудовании. Объем вычислительных ресурсов и памяти традиционно ограничивает возможность обучения больших моделей на дешевых GPU.
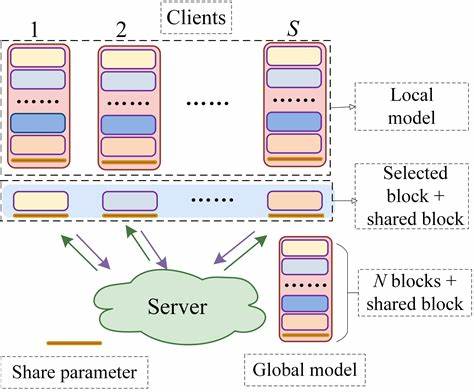
Методы, которые позволяют распределять нагрузку, снижать потребление памяти и оптимизировать использование оборудования, становятся ключевыми для доступности современных ИИ технологий. Блочный покоординатный спуск представляет собой разновидность итеративного алгоритма оптимизации, в котором параметры модели обновляются блоками последовательно или параллельно, что значительно уменьшает требования к памяти и вычислительным ресурсам на каждом шаге. Такой подход идеально подходит для разделения обучения на несколько фаз, позволяя эффективно использовать каждый GPU в кластере. При использовании BCD весь набор параметров модели разбивается на блоки, каждый из которых обрабатывается отдельно. Это уменьшает одновременную нагрузку на память и снижает необходимость в больших объемах видеопамяти.
Таким образом, можно обучать модели с параметрами, которые в обычных условиях не помещались бы в память бюджетных видеокарт. Кроме того, метод позволяет динамически перераспределять ресурсы между блоками, что улучшает аппаратную эффективность и снижает простоев оборудования. В реальных экспериментах была достигнута значительная экономия затрат: обучение модели с 7 миллиардами параметров занимало всего треть стоимости на кластерах A100/A800 и лишь около 2,6% от стоимости традиционного обучения на RTX 4090. Такой результат стал возможен благодаря сочетанию BCD с инженерными оптимизациями, включая продвинутые схемы распределения памяти и вычислений, эффективное использование быстрых шин данных и оптимизацию коммуникации между GPU. Важным преимуществом метода является то, что несмотря на фундаментальное изменение стратегии обучения, точность полученных моделей остается на уровне или превосходит показатели стандартного полного обучения и методов дообучения (fine-tuning).
Это говорит о том, что экономия ресурсов не сказывается на качестве моделей, что особенно ценно для промышленного применения и научных исследований. Для команд и исследователей, работающих с ограниченным бюджетом, возможность использовать доступные по стоимости видеокарты RTX 4090 для обучения моделей, которые ранее были доступны только на более дорогих A100 кластерах, открывает новые горизонты. Это позволяет более гибко планировать инфраструктуру и масштабировать проекты, не жертвуя при этом качеством результата. Помимо экономии средств, технология улучшает аппаратное использование: уменьшается время простоя GPU, уменьшается необходимость в резервных ресурсах и повышается общая производительность кластера. Это делает блоковый покоординатный спуск особенно привлекательным для компаний, стремящихся максимально эффективно использовать свои вычислительные мощности.
Внедрение BCD требует определенных изменений в стратегии разработки и инфраструктуре. Нужно адаптировать модели и алгоритмы так, чтобы разбивать их параметры на оптимальные блоки, учитывать специфику аппаратного обеспечения и выстраивать коммуникацию внутри кластера. Но эти усилия окупаются значительным сокращением затрат и расширением возможностей обучения. Обзор последних исследований показывает, что блочный покоординатный спуск продолжает развиваться и совершенствоваться, появляясь в новых методах оптимизации и комбинируясь с другими технологиями, такими как квантование и смешанная точность. Это создает перспективы для дальнейшего удешевления и ускорения обучения больших моделей.
Итогом становится сценарий, в котором малые и средние команды, а также компании с ограниченным бюджетом, получают реальные инструменты доступа к передовым возможностям больших языковых моделей, что способствует развитию инноваций и демократизации искусственного интеллекта. В заключение, блочный покоординатный спуск открывает новые пути для эффективного и доступного обучения крупных моделей на недорогих кластерах с RTX 4090, A100 и A800 GPU. С его помощью можно существенно сократить затраты на вычисления, повысить аппаратную эффективность и при этом сохранить высокий уровень точности и качества моделей. Это делает данный подход одним из наиболее перспективных и практичных решений для современных задач построения и обучения ИИ, особенно в условиях нехватки ресурсов.