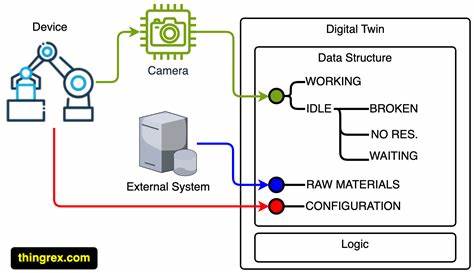
В современном цифровом мире объем информации, с которым ежедневно сталкивается пользователь, постоянно растет. Каждый веб-сайт, который мы посещаем, каждая статья и видео оставляют свой след, формируя цифровой след, который становится все более ценным для персонализации и автоматизации повседневных задач. В этих условиях появляются новые технологические решения, позволяющие эффективно работать с этими данными и выстраивать интеллектуальные системы, адаптирующиеся под наши нужды. Одним из таких новаторов является проект Digital Twin Proxy, который предлагает уникальный подход к использованию истории веб-браузинга в качестве персональной памяти для искусственных интеллектов (ИИ). Digital Twin Proxy представляет собой прокси-сервер, который перехватывает и записывает весь веб-трафик пользователя, а затем с помощью мощных языковых моделей искусственного интеллекта анализирует полученные данные, создавая глубокую и содержательную картину пользовательских интересов и привычек.
Идея состоит в том, чтобы превратить обычный просмотр страниц в ценный источник контекста, который может использоваться ИИ-агентами для формирования более персонализированного и эффективного взаимодействия с пользователем. Основу работы Digital Twin Proxy составляет локальный Squid-прокси, через который проходит весь HTTP и HTTPS трафик браузера. Каждый запрос фиксируется и передается в приложение Digital Twin Proxy, где происходит взаимодействие с языковой моделью, совместимой с OpenAI API. Именно этот интеллектуальный агент не только анализирует данные о посещенных страницах, но и самостоятельно решает, какие из них требуют более глубокого изучения и дополнительного сбора информации. Такой «агентный» подход позволяет не просто пассивно фиксировать историю, а активно извлекать из нее смысл, выделять ключевые темы, тенденции и интересы пользователя.
Особое внимание уделено вопросам конфиденциальности. Digital Twin Proxy поддерживает использование локальных моделей искусственного интеллекта, таких как Ollama, LM Studio, vLLM и TGI, что исключает необходимость отправлять чувствительные данные в облачные сервисы и тем самым снижает риски утечки информации. Это особенно важно для тех, кто ценит безопасность и приватность своих данных. Помимо обеспечения приватности, проект разработан с гибкостью и удобством настройки. Пользователи могут выбирать модели ИИ, устанавливать интервал аналитики, ограничивать количество анализируемых URL-адресов и адаптировать работу прокси под собственные потребности.
Работа может вестись как в режиме постоянного фонового анализа, так и в одноразовом режиме, что делает Digital Twin Proxy универсальным инструментом для различных сценариев использования. Ценность такого решения особенно очевидна в контексте развития агентных ИИ-приложений. Полученный цифровой двойник, содержащий структурированные логи посещений и анализ контента, становится мощным источником информации для других интеллектуальных агентов. На основе этого контекста ИИ может точнее прогнозировать интересы пользователя, предлагать релевантные инструменты и контент, а также оптимизировать пользовательский опыт в реальном времени. Ключевым планируемым нововведением является интеграция с MCP сервером, который позволит другим агентам получать доступ к цифровому двойнику в режиме реального времени.
Это откроет путь к созданию целой экосистемы персонализированных ИИ-служб, которые смогут взаимодействовать друг с другом и с пользователем на новом уровне. Также в планах команда Digital Twin Proxy работает над функцией инъекции контекста прямо в браузер. Такая возможность позволит агентам таких сервисов, как ChatGPT или Perplexity, использовать данные цифрового двойника для создания интерактивного и максимально релевантного пользовательского опыта при веб-сёрфинге. Для начала работы с Digital Twin Proxy пользователю потребуется установить Rust toolchain, настроить Squid-прокси и выбрать подходящую модель ИИ с OpenAI-совместимым API. После клонирования репозитория и сборки проекта настройка браузера на работу через локальный прокси позволит начать запись трафика.
Далее можно выбрать режим работы: чистый логинг, одноразовый анализ или работа в фоновом режиме с периодическими запусками анализа. Такой гибкий подход позволяет адаптировать систему к различным задачам, будь то исследование онлайн-поведения, персонализация рабочих процессов или интеграция с другими ИИ-инструментами. Для пользователей Windows, использующих WSL, предусмотрены специальные рекомендации по проксированию и настройкам сетевого взаимодействия, что обеспечивает корректную работу решения на кросс-платформенной основе. В разработке проекта активно применяются современные средства контроля качества кода, такие как rustfmt и clippy, что гарантирует высокое качество и стабильность продукта. При этом проект открыт для сообщества разработчиков и энтузиастов, готовых внести свой вклад в его развитие.