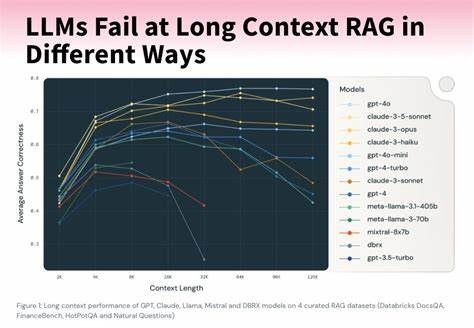
Современные языковые модели продолжают удивлять своей способностью обрабатывать огромные объёмы информации одновременно. Контекстные окна расширяются до миллионов токенов, открывая потенциально безграничные возможности для интеграции документов, инструментов, инструкций и прочих данных в один запрос. Многие специалисты в сфере искусственного интеллекта и разработки агентов возлагают большие надежды на подобные масштабные контексты, считая, что именно они станут ключом к созданию интеллектуальных помощников мечты. Однако реальность оказывается весьма сложнее и многограннее. Увеличение объемов контекста далеко не всегда приводит к улучшению качества ответов.
Наоборот, долгое сочинение и наполнение контекста могут стать источником множества неожиданных проблем, которые порой полностью сводят на нет преимущества больших окон. Основные пути, по которым длинные контексты обречены на провал, можно свести к четырём ключевым явлениям: контекстная токсикация, отвлечение, путаница и внутренний конфликт информации. Согласно результатам наблюдений и исследований, эти проблемы наиболее сильно сказываются именно на агентных системах, где необходимо не просто единичное генерирование текста, а последовательное взаимодействие, анализ, синтез и управление большим количеством данных и инструментов. Контекстная токсикация – это ситуация, когда в контекст случайно или непреднамеренно попадает искажение информации или галлюцинация, которая начинает многократно повторяться и становиться частью будущих ответов. Такой «зараженный» контекст в буквальном смысле губит работы агента, настраивая его на достижение неправильных или невозможных целей.
Это было ярко продемонстрировано в отчёте DeepMind по модели Gemini 2.5, когда агент, играя в Pokémon, начал фиксироваться на ложных данных о состоянии игры. Результатом стали бессмысленные стратегии и повторяющиеся действия, не приносящие успеха. Долгое исправление такой токсикации требует значительных затрат времени и вычислительных ресурсов, а в некоторых случаях просто неизбежно приводит к снижению эффективности всей системы. Следующая проблема, контекстное отвлечение, связана с тем, что при избыточном наполнении контекста модель теряет баланс между обработкой полученной информации и опорой на собственные знания, заложенные в ходе обучения.
Когда контекст разрастается до огромных размеров, агент начинает цепляться за ранее используемую информацию и перестаёт фокусироваться на генерации новых, продуманных решений. Проявилось это и в использовании Gemini 2.5 Pro с миллионом токенов контекста, где после 100 тысяч токенов наблюдалось подавление творческого планирования в пользу многократного повторения старых действий. Для более скромных моделей такой «потолок» оказывается значительно ниже: исследования показывают ухудшение корректности примерно после 32 тысяч токенов для Llama 3.1 405b и раньше для менее мощных архитектур.
В итоге очень большие контекстные окна теряют смысл, если не используются для специальных целей, таких как суммирование или выбор релевантной информации. Контекстная путаница – это ситуация, когда в одном запросе оказывается слишком много лишнего, не относящегося к сути задачи. Особенно это заметно при попытках предоставить модели сразу множество инструментов или описаний, чтобы она могла решить любую задачу автоматически. На практике избыточное количество инструментов или документации приводит к падению качества, так как модель вынуждена обрабатывать большое количество нерелевантных данных и зачастую ошибочно выбирает неправильные утилиты. Примером служит лидерборд Berkeley по использованию функций, с результатами трёх версий которого видно, что производительность моделей снижается с увеличением числа предоставленных инструментов.
Еще более ярко проблему демонстрируют эксперименты с маленькими моделями, которые не справляются с обработкой контекста, включающего большое количество функций. На GeoEngine benchmark, где было задействовано 46 различных инструментов, сжатая версия Llama 3.1 8b провалила тест, а при сокращении списка до 19 инструментов успешно справилась с задачей. Эта особенность объясняется особенностями механизма внимания у моделей: всё, что попадает в контекст, требует обработки, даже если это лишняя или неуместная информация. Контекстный конфликт – самая серьёзная проблема из всех описанных.
Она возникает в случаях, когда в контексте начинают противоречить друг другу различные части информации, в том числе описания инструментов и данные из внешних источников. Исследования команды Microsoft и Salesforce показали, что разбиение и поэтапное добавление информации часто ухудшает качество итоговых ответов на 39% и более. На практике это выражается в том, что модель сначала пытается сгенерировать решение на основе неполной или неточной информации, а затем, сталкиваясь с новыми данными, просто не может отойти от своей первоначальной ошибки из-за устоявшейся привязки к предыдущему ответу. В агентных системах такие конфликты только усугубляются, ведь контекст формируется из множества разнородных источников: документов, вызовов инструментов, выводов других моделей. Особенно сложна ситуация при использовании сторонних многофункциональных платформ (MCP), где описания инструментов и инструкции могут иметь несовместимые элементы.
Популярность больших контекстных окон в языковых моделях породила ожидания появления универсальных агентов, которые смогут хранить всю необходимую информацию в памяти, обеспечивая мгновенный доступ ко всем документам и инструментам. Однако именно на практике становится понятно, что увеличение длины контекста одновременно порождает множество новых проблем, которые требуют грамотного управления и оптимизации. Такие негативные эффекты, как «заражение» контекста ложной информацией, отвлечённость на историю работы, использование нерелевантных данных и внутренние противоречия, могут сделать долгие контексты скорее обузой, нежели преимуществом. Особенно остро эти проблемы проявляются у агентных систем, где длительный обмен данными, многошаговые операции и взаимодействие с инструментами легко приводят к накоплению ошибок и падению эффективности. К счастью, ситуация не безнадёжна.
Уже сейчас ведутся активные исследования и разработки методик, позволяющих обходить или минимизировать описанные проблемы. Среди них динамическая подгрузка необходимых инструментов, изоляция частей контекста, применение стратегий санации ошибочной информации и корректное управление последовательным добавлением данных. Все эти техники призваны помочь разработчикам создавать более надёжных и продуктивных агентов, способных эффективно использовать длинные контекстные окна без падения качества. В перспективе понимание и преодоление ограничений длинных контекстов станет фундаментальным шагом к созданию действительно умных, автономных и многофункциональных помощников, способных работать с большим объёмом информации без потери ясности и логики.







