Tensor Processing Units (TPU) представляют собой уникальные аппаратные ускорители, разработанные Google специально для обработки задач глубинного обучения. Они отличаются от традиционных процессоров, таких как центральные процессоры (CPU) и графические процессоры (GPU), своей специализированной архитектурой, ориентированной на эффективное выполнение операций матричного умножения и высокую энергоэффективность. С момента своего появления TPU прошли путь от эксперимента до ключевого компонента, используемого в огромных облачных сервисах Google и сложных моделях искусственного интеллекта. В данной статье мы подробно рассмотрим архитектуру TPU, их организацию на уровне чипа, коммуникационные возможности и масштабируемость, а также объясним, почему TPU продолжают оставаться одним из самых эффективных инструментов для тренировки и вывода нейросетей в настоящее время. Истоки TPU уходят в глубокие исследования Google, начавшиеся еще в 2006 году.
Первоначально компания рассматривала разные варианты аппаратного ускорения — от GPU до FPGA и специализированных ASIC-чипов. Несмотря на быстрое развитие GPU, Google решила создать собственное аппаратное решение, которое будет максимально оптимизировано под вычислительные задачи глубинного обучения. Поворотным моментом стало внедрение голосового поиска, требующего значительных вычислительных ресурсов нейросетей, что и стало стимулом для разработки TPU. Одной из главных особенностей TPU является их дизайн, основанный на концепции системных массивов (systolic arrays). Это матрица взаимосвязанных исполнительных элементов, которые параллельно выполняют операции умножения и накопления.
Такая архитектура идеально подходит для умножения больших матриц и сверток, что составляет основу вычислений нейронных сетей. В частности, TPU v4 содержит 128x128 системный массив в матричном умножительном блоке, что позволяет достигать впечатляющих пиковых производительностей в сотни целых и тысячи десятых терафлопс на один чип. В рамках каждого TPU-чипа располагаются два основных блока вычислений — TensorCores. У каждого из них есть выделенная память низкой задержки и высокоскоростное подключение к внешней памяти типа HBM объемом порядка 32 гигабайт. Помимо матричного умножения, реализуемого в MXU, в TensorCore включены векторные блоки для выполнения элементных операций и буферы памяти, обеспечивающие эффективный обмен данными внутри чипа.
Особенностью TPU является значительный объем локальной памяти, который превосходит традиционные кэши CPU и GPU. Это связано с философией архитектуры — минимизировать обращения к дорогой в энергозатратах внешней памяти, используя заранее подготовленные данные в большой локальной памяти. Именно поэтому TPU работают в тесном тандеме с компилятором XLA, который выполняет Ahead-Of-Time компиляцию: вычислительный граф анализируется заранее, а все операции и обращения к памяти планируются детально с оптимизацией, что снижает накладные расходы во время выполнения. Такая особенность делает TPU менее гибкими по сравнению с GPU, которые рассчитаны на широкий спектр программных сценариев. Однако для строго заданных задач глубинного обучения это приносит существенное преимущество в энергоэффективности и производительности.
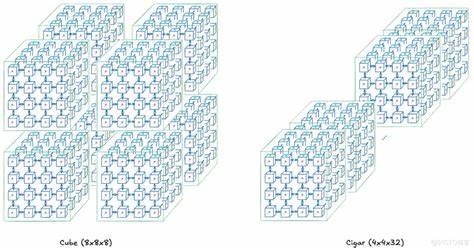
При работе на масштабируемость TPU придают огромное значение — однопроцессорные возможности дополняются сложными коммуникационными структурами. На уровне платы (Tray) четыре TPU-чипа объединены между собой, каждый с собственным CPU-хостом, что облегчает управление и подготовку данных. Взаимодействие между чипами происходит по высокоскоростным интерфейсам Inter-Core Interconnect (ICI), значительно превосходящим по пропускной способности интернет-соединения. Далее несколько плат объединяются в стеки, а затем формируют TPU Rack, представляющий собой 3D тороидальную сеть из 64 чипов. Такая топология обеспечивает высокую плотность связей и минимальное время передачи данных между узлами.
Благодаря использованию оптических коммутаторов (OCS) в сети TPU Rack достигается функциональность точечной коммутации и возможность менять топологию сетей передачи данных, что значительно увеличивает гибкость системы и способствует эффективному распределению ресурсов среди нескольких задач одновременно. TPU Pod — следующий уровень масштабируемости — объединяет до нескольких десятков таких стоек и достигает пиковых вычислительных мощностей в экзафлопсы (миллиарды миллиардов операций с плавающей точкой в секунду). Очень важной особенностью TPU является возможность разбивки на «срезы», позволяющие выделять ресурсы под конкретные задачи без выпадения из общей коммутационной сети. Такая архитектура делает TPU идеальным решением для крупных распределённых вычислений, где требуется баланс между производительностью и гибкостью. Еще одним увлекательным элементом TPU является использование моделирования топологий, например, «скрученного тороида» (twisted torus), когда провода соединяют узлы по альтернативной схеме, что позволяет уменьшить количество прыжков данных и увеличить пропускную способность.
Это очень ценно при реализации сложных параллельных операций типа tensor parallelism и pipeline parallelism, характерных для тренировки больших моделей трансформеров. При этом TPU поддерживают различные виды параллелизма — от распределения данных до шардирования параметров и пайплайнов, что позволяет эффективно масштабировать обучение моделей от небольших до огромных размеров. Важным фактором, обуславливающим распространение TPU в индустрии, является их высокая энергоэффективность. Анализ энергопотребления TPU показывает, что большая часть затрат связана с операциями чтения и записи из внешней памяти, а сами арифметические операции обходятся значительно дешевле. Архитектура пытается максимально снизить обращения к памяти, перенося данные в локальные высокоскоростные буферы и используя оптимизированные программные методы, управляемые компилятором XLA.
В итоге TPU достигают впечатляющих показателей энергии на операцию, что критично для современных масштабных вычислений и тренировки сложнейших моделей с миллиардными параметрами. Основой для разработчиков является интеграция TPU с высокоуровневыми фреймворками машинного обучения. JAX, TensorFlow и PyTorch предоставляют поддержку TPU через XLA, что позволяет практически без изменений в коде переносить вычисления с CPU или GPU на TPU. Однако, ввиду особенностей AoT-компиляции, некоторые динамические операции требуют дополнительной адаптации или статичности параметров, чтобы избежать затрат на частую перекомпиляцию. Если говорить о будущем TPU, то ожидается развитие следующих поколений с ростом числа матричных блоков, увеличением числа чипов в Pods и развитием сетевых топологий.
TPUv7 «Ironwood», например, обещает повысить общую производительность Pod до десятков экзафлопсов, открывая новые горизонты для тренировки сверхсложных моделей искусственного интеллекта. Google активно продолжает совершенствовать не только аппаратную составляющую, но и программные инструменты для управления распределенными вычислениями, обеспечивая высочайшую эффективность и удобство использования. В заключение можно отметить, что TPU — это результат глубокого аппаратно-программного синтеза, реализующего уникальный подход к ускорению машинного обучения. Их архитектура ориентирована на конкретные вычислительные паттерны, что с одной стороны снижает универсальность, но с другой — дарит огромные преимущества по производительности и энергоэффективности. Именно поэтому TPU играют ключевую роль в масштабных ML-проектах Google и задают стандарты для будущих специализированных вычислительных ускорителей.
Постоянное совершенствование TPU обеспечивает лидерство в области искусственного интеллекта и открывает новые возможности для исследователей и разработчиков во всем мире.


![Rediscovered forgotten Viking spear bows [video]](/images/459255FA-72AC-46D0-A0D9-848D331B973D)