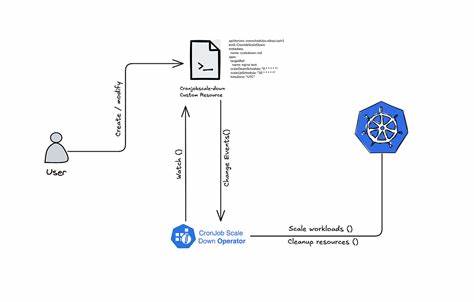
Современные облачные инфраструктуры и контейнеризированные приложения требуют эффективного управления ресурсами для оптимизации затрат и обеспечения высокой производительности. Одной из ключевых задач в Kubernetes является управление масштабированием приложений в зависимости от времени суток, нагрузки или других факторов. Решением для автоматизации этой задачи выступает Cronjob Scale Down Operator — оператор Kubernetes, позволяющий автоматически масштабировать деплойменты и statefulsets по заданному расписанию. Этот инструмент становится незаменимым для компаний и команд, стремящихся снизить расходы на инфраструктуру без ущерба для стабильности и доступности сервисов. Cronjob Scale Down Operator — это Kubernetes-оператор, который использует стандартные cron-выражения с точностью до секунд для задания расписания масштабирования.
Он поддерживает множество временных зон, благодаря чему администраторы могут адаптировать графики масштабирования под региональные особенности. Это особенно актуально для глобальных сервисов, работающих в различных часовых поясах. Функционал оператора включает в себя не только уменьшение или увеличение количества реплик в разное время суток, но и комплексные возможности по очистке временных и тестовых ресурсов в кластере. Например, оператор умеет автоматически удалять устаревшие configmaps, секреты, службы, деплойменты, statefulsets и другие объекты, помеченные специальными аннотациями. Такая автоматизация значительно облегчает жизнь разработчикам и операторам, позволяя поддерживать кластер в чистоте и порядке, предотвращая накопление неиспользуемых ресурсов.
Особенность Cronjob Scale Down Operator — режим чистки без масштабирования, который идеально подходит для CI/CD пайплайнов и тестовых окружений. В этом режиме оператор просто удаляет устаревшие или временные объекты по расписанию, не затрагивая основные рабочие ресурсы. Это решение помогает избежать проблем с избыточным потреблением ресурсов в кластере без вмешательства в рабочие загрузки. Кроме этого, оператор обеспечивает мониторинг и визуализацию состояния всех процессов через встроенный веб-интерфейс. Здесь можно увидеть текущее количество реплик деплойментов и statefulsets, последние выполненные операции масштабирования и очистки, а также состояния задач в реальном времени.
Веб-панель отличается удобным и современным дизайном, поддерживает автоматическое обновление данных каждые 30 секунд и доступна для просмотра с разных устройств. Для более продвинутого мониторинга и интеграции с существующими системами наблюдения оператор предоставляет обширные метрики, совместимые с Prometheus. Среди ключевых метрик выделяются количество выполненных операций масштабирования и очистки, текущее состояние целевых ресурсов, а также статистика по ошибкам и длительности обработки задач. Экспорт данных в Prometheus и использование готовых Grafana-дэшбордов позволяет глубоко анализировать активность оператора и эффективность процессов управления ресурсами в кластере. Установка Cronjob Scale Down Operator возможна тремя основными способами.
Рекомендуемый и удобный вариант — установка через Helm-чарт, который расположен в отдельном репозитории с регулярными обновлениями и поддержкой. Такой подход позволяет легко интегрировать оператора в существующий инфраструктурный стек, настраивать параметры развертывания и управлять версиями. Кроме того, доступен вариант использования предсобранных контейнерных образов из Docker Hub или GitHub Container Registry. Для продвинутых пользователей возможна установка напрямую через kubectl с применением манифестов CRD, RBAC и менеджера. Преимущества Cronjob Scale Down Operator особенно заметны в тех организациях, где важно оптимизировать бюджет на инфраструктуру.
Благодаря точному управлению временем масштабирования можно, например, уменьшать количество реплик во внерабочее время, что снижает потребление вычислительных ресурсов и экономит деньги. При этом в рабочем режиме оператор автоматически возвращает конфигурацию к нужному уровню, обеспечивая необходимую производительность и отказоустойчивость. Гибкость в настройках расписания — одна из сильных сторон оператора. Возможность задавать крон-выражения с шестью полями (включая секунды) расширяет традиционный формат и позволяет создавать очень точные графики. Это полезно для тестирования, быстрого развёртывания изменений или работы с нестандартными сценариями, например, частыми циклами масштабирования для разработки и тестирования.
Поддержка очистки «сиротских» ресурсов — еще одна важная функция. Такие ресурсы — это объекты, которые не имеют аннотаций для удаления, но считаются устаревшими и больше не нужны. Оператор позволяет настроить параметры, которые удаляют эти объекты, исходя из заданного максимального возраста и меток. Это помогает избежать накопления «мусора» в кластере, который может возникать в ходе развития приложений или автоматизированных процессов. Безопасность и стабильность работы — приоритетные аспекты Cronjob Scale Down Operator.
Оператор включает режим dry-run для безопасного тестирования операций очистки без фактического удаления ресурсов. Это дает возможность проверить корректность конфигураций и исключить случайные ошибки. Обработка ошибок в операторе реализована таким образом, чтобы работать без прерываний, даже если целевые ресурсы временно отсутствуют или недоступны. Документация, сопровождающая проект, подробно описывает все возможности, примеры использования и настройки. В каталоге examples представлены готовые конфиги для быстрого старта: от простых тестовых сценариев с минутным интервалом до продвинутых расписаний с учётом часовых поясов и комбинированных задач по масштабированию и очистке.
Такой подход значительно упрощает внедрение оператора в любую инфраструктуру. Для разработчиков и DevOps-специалистов предусмотрен процесс сборки и запуска из исходного кода с использованием Makefile. Это расширяет возможности кастомизации и масштабирования, а также позволяет внести собственные улучшения или адаптировать оператора под специфические требования. В результате, Cronjob Scale Down Operator — это мощное и гибкое решение для автоматизации масштабирования и управления ресурсами в Kubernetes. Использование данного оператора помогает значительно снизить издержки, повысить эффективность эксплуатации кластера и гарантировать своевременную очистку временных и тестовых объектов.
Его возможности идеально подходят для разнообразных сценариев: от крупных продакшн-сред до сред с интенсивной разработкой и тестированием. Для компаний, стремящихся modernize свои Kubernetes-окружения и оптимизировать затраты, внедрение Cronjob Scale Down Operator становится важным шагом на пути к устойчивому и управляемому облачному будущему. Благодаря простоте установки и широкому функционалу этот инструмент способен стать незаменимым помощником в ежедневных операциях с кластером. Проследив за инновациями и тщательно проработанным функционалом, можно с уверенностью рекомендовать Cronjob Scale Down Operator как одну из лучших практик управления масштабированием и очисткой в современных Kubernetes-системах.