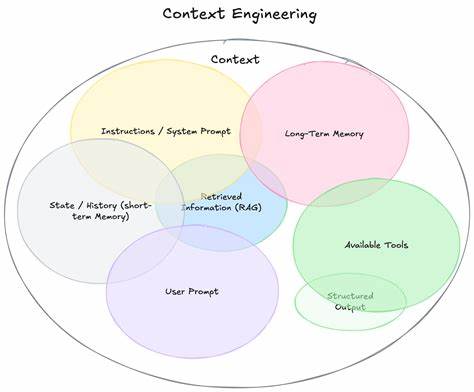
В современном мире искусственного интеллекта и больших языковых моделей (LLM) возникает необходимость не просто создавать мощные алгоритмы, а грамотно организовывать работу с большим объёмом информации. Одним из ключевых вызовов становится управление контекстом — объемом данных, который доступен модели в любой момент взаимодействия. Понятие «инженерия контекста» быстро выходит на передний план, превращаясь в искусство и науку наполнения окна контекста именно теми данными, которые нужны для успешного решения конкретной задачи. В традиционных вычислительных системах мы привыкли к понятию оперативной памяти, или RAM, — ограниченного ресурса, который ускоряет работу центрального процессора, предоставляя быстрый доступ к актуальным данным. В случае с LLM, окно контекста выполняет аналогичную роль.
Модель может учитывать только ограничённое число токенов одновременно, и качество работы во многом зависит от того, насколько эффективно эта область заполнена релевантной информацией. При этом неправильное использование окна контекста чревато снижением качества выводов, ростом затрат на вычисления и увеличением времени отклика. Контекст бывает разным, и инженеры сталкиваются с необходимостью работать с множеством его видов. Например, инструкционные данные включают подсказки, примеры, описания инструментов, которые помогают направлять поведение агента. Есть знания — факты или прошлые данные, которые могут использоваться для обогащения ответа.
Кроме того, важную роль играют инструменты, то есть внешние ресурсы или функции, с помощью которых агент может получать дополнительную информацию или выполнять конкретные действия. Эффективное управление этими типами контекста требует гибких и продуманных стратегий. В последние годы наблюдается активный рост интереса к интеллектуальным агентам — системам, которые не просто прямолинейно отвечают на запросы, а сами принимают решения, вызывают внешние инструменты и управляют диалогом с пользователем на протяжении длительного времени. Особенностью таких агентов становится необходимость сохранять и использовать в работе всё большее количество информации, накопленной по ходу взаимодействия. Это приводит к быстрому заполнению окна контекста, что, в свою очередь, мотивирует разработчиков искать способы оптимизации.
Сложности при работе с длинным контекстом не ограничиваются аппаратными ограничениями. Появляются специфические феномены, которые снижают качество работы моделей. Например, когда ошибочная или неточная информация попадает в контекст, это приводит к «отравлению» данных, а лишние, не относящиеся к задаче детали «отвлекают» модель и вызывают путаницу. Иногда части контекста конфликтуют между собой, что усугубляет ситуацию и мешает получить корректный ответ. Подобные проблемы особенно актуальны в сценариях, где агент постоянно получает обратную связь от инструментов и должен ее аккуратно интегрировать в последующие шаги.
Для борьбы с этими вызовами инженеры используют четыре основных стратегии, объединённые в понятие инженерии контекста: запись, выбор, сжатие и изоляция контекста. Каждая из них служит своей цели и помогает в оптимизации использования окна контекста. Запись контекста предполагает сохранение информации вне окна контекста, чтобы освободить пространство и при этом не потерять важные данные. Одной из популярных техник является использование виртуальных «записных блокнотов» или scratchpad — инструментов, которые позволяют агенту делать заметки, записывать промежуточные итоги рассуждений и планы действий. Это похоже на то, как человек во время решения сложных задач делает записи, чтобы не забыть важные детали.
Хранение данных вне окна контекста используется не только в рамках одной сессии, но и между разными сессиями. Понятие долговременной памяти агента становится всё более актуальным. Системы могут автоматически создавать и обновлять такие воспоминания на основе накопленного опыта за множество взаимодействий. Это повышает качество моделей и позволяет их использовать в более широком спектре приложений — от помощников до сложных систем поддержки принятия решений. Выбор контекста — следующий важный этап.
Когда агенту необходимо приступить к работе, он выбирает из накопленной памяти, записей и знаний именно те данные, которые максимально релевантны текущей задаче. Многие современные решения применяют технологии семантического поиска и построения векторных индексов, чтобы обеспечить максимально релевантный подбор контекста. Это помогает избежать попадания лишней или неактуальной информации в окно контекста. Интересен пример инструментов, которые могут усложнять работу агента, если их слишком много или если они имеют пересекающееся описание. В таком случае эффективным решением становится отбор наиболее подходящих инструментов с помощью методов RAG (Retrieval Augmented Generation), позволяющих не только хранить описания, но и динамически выбирать лучшие из них в зависимости от задачи.
Сжатие контекста — важная техника, позволяющая уменьшить количество токенов, которые необходимо учитывать агенту. Сюда входит автоматическое суммирование длительных цепочек взаимодействий, сокращение избыточных или устаревших данных, а также выборочная фильтрация информации. Например, когда беседа достигает сотен ходов, использование иерархических или рекурсивных методов суммирования позволяет сохранить суть и при этом сэкономить место в окне контекста. Техника тримминга или обрезки данных помогает избавиться от старых, менее важных сообщений, предотвращая перегрузку модели. Некоторые исследователи разрабатывают даже специальные модели, обученные именно для подбора релевантных частей информации и удаления ненужных, тем самым оптимизируя производительность системы.
Изоляция контекста — это стратегия разделения информации и задач между несколькими агентами или сервисами, что позволяет каждому из них работать с более узким и специализированным объемом данных. Такая архитектура поддерживает параллельную обработку и снижает требования к объему контекста для каждого отдельного элемента системы. С помощью мультиагентных систем можно обеспечить более глубокую проработку подзадач, распределить нагрузку и уменьшить время реакции. Примером изоляции может быть использование песочниц (sandbox), в которых определённые шаги обработки или обращения к внешним инструментам отделены от ЛЛМ, что обеспечивает сохранность и упорядоченность данных. Кроме того, структурированный объект состояния — runtime state — может выступать в роли изолированной среды, где разные категории информации хранятся отдельно, а доступ к ним предоставляется выборочно и только тогда, когда это необходимо.
Появление специализированных платформ и инструментов, таких как LangGraph и LangSmith, упрощает внедрение и использование описанных подходов в инженерии контекста. Они предлагают системы для отслеживания использования токенов, мониторинга и оценки эффективности агентов, а также наборы функций для записи, выбора, сжатия и изоляции данных. Благодаря гибкому управлению состоянием и поддержке различных видов памяти, разработчики могут создавать более качественные и устойчивые решения. В конечном итоге, практика инженерии контекста становится ключевым навыком для всех, кто строит современные AI-агенты. Понимание того, какие данные и каким образом использовать, как виртуально хранить, фильтровать и делить информацию между компонентами системы, напрямую влияет на качество и эффективность работы модели.