Современные системы обработки данных сталкиваются с задачей наблюдаемости на совсем новом уровне — обработка и анализ сотен петабайт информации становятся повседневной реальностью. Это особенно актуально для систем, которые работают с огромными объемами событий и логов в режиме реального времени. Одним из ключевых решений индустрии долгое время оставался OpenTelemetry (OTel) — стандартный, универсальный и широко поддерживаемый инструмент для сбора телеметрических данных. Тем не менее, когда масштабы вашей платформы выходят за привычные рамки, универсальные подходы могут столкнуться с серьезными ограничениями. Так произошло и с нашей платформой наблюдаемости, которая выросла с 19 петабайт (PiB) до впечатляющих 100 петабайт некомпрессированных логов и 500 триллионов строк данных.
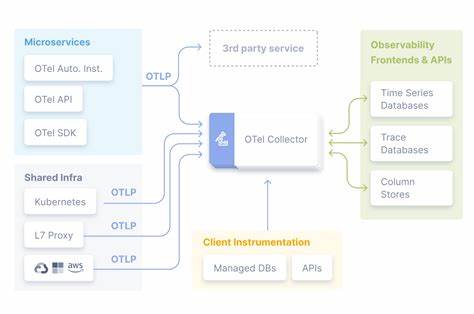
В этой статье мы делимся опытом отказа от традиционной архитектуры на основе OpenTelemetry в пользу собственного специализированного решения, а также рассказываем о технических нюансах, которые помогли нам достичь непревзойденного уровня масштабируемости и эффективности. Изначально OpenTelemetry был незаменимым элементом нашего стека — с его помощью мы быстро организовали сбор логов из всех Kubernetes-подов, обрабатывающих ClickHouse. Ключевым преимуществом OTel было то, что он предоставлял единую платформу для обработки событий, метрик, трассировок и логов, а также независимость от поставщика и открытый, стандартизированный формат данных. Эта универсальность помогала быстро запускать систему и обеспечивала гибкость. Однако со временем, по мере роста нагрузки, мы столкнулись с серьезными узкими местами, связанными с производительностью, потреблением ресурсов и достоверностью данных.
Проблема во многом заключалась в самой архитектуре OTel-агентов и коллекторов. В нашем сценарии данные сначала писались в JSON на стандартный вывод (stdout) ClickHouse, потом kubelet сохранял их в /var/log/. Далее коллекция происходила через OTel collector, который парсил JSON, маршаллил данные в промежуточное внутреннее представление, конвертировал в OTel лог формат, а затем передавал дальше — для последующего преобразования в родной формат ClickHouse при загрузке в нашу платформу LogHouse. Каждый из этих этапов требовал дополнительной обработки, затрат CPU и памяти, влияя на общую производительность. Мы обнаружили, что такая многоступенчатая конвертация негативно сказывалась на уровне потерь данных: при пиковых нагрузках OTel-агенты просто не успевали обрабатывать весь объем событий, из-за чего происходила утечка логов прямо на границе сбора.
Для устранения этого недостатка пришлось бы масштабировать инфраструктуру коллекторов до колоссальных размеров — по оценкам, для оборота 20 миллионов строк в секунду нам потребовалось бы примерно 8000 ядер CPU, что оказалось экономически и технически неприемлемо. Тем временем внутри ClickHouse существуют системные таблицы, которые предоставляют богатый и очень подробный доступ к данным о запросах, состоянии кластера, операциям дисков и прочей служебной информации. Эти таблицы удобны для глубокого анализа и мониторинга, однако их структура намного более комплексна и не сводится к выводу stdout. Обработка таких данных стандартными OTel-агентами была неэффективной и затруднительной. Все это подтолкнуло нас к созданию специализированного инструмента — System Tables Exporter, или SysEx.
Основной идеей SysEx стало «байт-в-байт» копирование из оригинальных системных таблиц ClickHouse в нашу платформу LogHouse без промежуточных преобразований и переформатирования. Таким образом мы смогли радикально снизить нагрузку на CPU и устранить узкие места, возникшие в OTel-пайплайне. Архитектура SysEx построена на пуле «скрейперов», которые делают pull-запросы к системным таблицам конкретных кластеров клиентов, параллельно распределяя нагрузку с помощью хэш-кольца. Такой подход позволяет выгружать высоко структурированную и объемную информацию по таймвидео, минимизируя задержки и исключая потерю данных из-за перегрузки. Кроме того, SysEx применяет стратегию отставания запросов на ~5 минут, что позволяет гарантировать обработку полностью «законченных» данных, так как это дает необходимое время для заполнения внутренних буферов ClickHouse.
Благодаря прямому чтению и записи в родном формате (Native), мы отказались от затратных операций сериализации и десериализации, а также от ненужных преобразований типов. Важное преимущество SysEx — динамическое создание и управление схемами данных. Поскольку системные таблицы ClickHouse эволюционируют, мы автоматизировали процесс выявления новых версий схем и объединения их на уровне Merge таблиц. Это позволяет выполнять запросы к историческим данным по всей корзине с использованием консистентного интерфейса без необходимости ручного обновления. Для внутрискластерных таблиц с моментальными снимками, таких как system.
processes, мы реализовали отдельный механизм периодического снятия агрегаций состояния, сохраняемого в LogHouse. Это существенно расширило возможности для досконального анализа по всем аспектам работы кластеров, включая диагностику и идентификацию проблем. Результаты внедрения SysEx впечатляют: используя не более 10 % от ресурсов CPU, ранее занятых OTel-сборщиками, мы смогли увеличить пропускную способность логов в 20 раз — примерно с 2 до 37 миллионов логированных сообщений в секунду без потерь. Такое повышение эффективности не только снижает операционные затраты и улучшает масштабируемость, но и повышает надежность всей системы. Несмотря на отказ от OTel в задачах с очень высокими требованиями к производительности, мы продолжаем использовать OpenTelemetry для получения базовых и аварийных логов в условиях падений сервисов.
Ведь SysEx основан на pull-модели и требует работающего кластера для получения данных из системных таблиц, тогда как OTel способен получать stdout и stderr даже из нестабильных или упавших процессов. Комбинация двух подходов позволяет нам покрыть полный спектр задач: OTel обеспечивает универсальность и устойчивость при авариях, а SysEx — специализированную эффективность и максимальное качество данных для ежедневного мониторинга и анализа. Ещё одним важным элементом является интеграция HyperDX — нативного ClickHouse UI для анализа и корреляции логов, который значительно улучшил пользовательский опыт инженеров. HyperDX поддерживает Lucene-подобный синтаксис запросов, что делает быструю фильтрацию и поиск простыми, но при этом разрешает выполнять сложные SQL-запросы для глубокого анализа. Благодаря этому инструменту мы успешно объединили аналитический потенциал платформы с удобством и масштабируемостью интерфейса.
Современный подход к хранению наблюдательных данных на основе широких событий и высокой кардинальности позволяет нам избежать ограничений традиционной трехпиллерной модели (метрики, логи, трассировки). Вместо агрегации при приеме мы храним все события целиком, что позволяет гибко и глубоко исследовать данные в любой момент времени. Эффективное хранение и быстрый доступ к таким объемам стали возможны благодаря колонночной архитектуре ClickHouse. В заключение, опыт масштабирования платформы наблюдаемости ClickHouse Cloud свыше 100 петабайт показал, что отказ от универсальных, но ресурсоемких решений вроде OpenTelemetry в пользу специализированных потоковых экспортеров собственной разработки может стать переломным моментом в управлении большими данными. Внедрение SysEx обеспечило уникальное сочетание высокой производительности, надежности и качества данных при значительно менее дорогостоящих вычислительных ресурсах.





![Do Not Fold, Spindle or Mutilate": A Cultural History of the Punch Card [pdf]](/images/832FD271-E7C2-4839-AEB3-0CFA6840EB70)