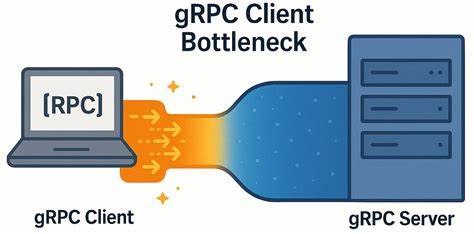
Технология gRPC широко используется для организации высокопроизводительной и надежной коммуникации между сервисами в распределённых системах. Благодаря использованию протокола HTTP/2 для мультиплексирования потоков и поддержке различных языков программирования, gRPC стала стандартом в ряде критически важных инфраструктурных решений. Однако в условиях низкой сетевой задержки, например, при работе на быстрых физических соединениях, разработчики часто сталкиваются с неожиданным падением производительности, обусловленным именно особенностями клиента gRPC. Разбор данной проблемы и поиск путей её решения являются ключевыми для построения эффективных систем с минимальными задержками и высокой пропускной способностью. В своей работе специалисты YDB.
tech обнаружили, что при уменьшении числа узлов в кластере нагрузочные тесты демонстрируют рост времени отклика и увеличение простоя ресурсов, что на первый взгляд кажется парадоксальным. Внимательный анализ выявил, что основным «бутылочным горлышком» служит именно клиентская часть gRPC — а не сетевая инфраструктура или серверные процессы. Суть проблемы заключается в том, что вне зависимости от числа параллельных рабочих процессов и объёма запросов, gRPC по умолчанию оптимизирует своё поведение так, что все каналы клиента часто используют один и тот же TCP-соединение. В HTTP/2 потоками мультиплексируются RPC-запросы, что теоретически повышает эффективность соединения, но на практике проявляется определённое ограничение по количеству одновременных потоков. Лимит в 100 параллельных потоков на соединение используется по умолчанию, и при достижении этого порога все дополнительные запросы начинают выстраиваться в очередь, что существенно увеличивает задержки на клиенте.
В ходе экспериментов с микро-бенчмарком, реализованным на C++, была обнаружена закономерность: с увеличением числа параллельных запросов рост пропускной способности далеко не линейный, а задержка при этом возрастает практически пропорционально количеству одновременных RPC. Анализ сетевого трафика и tcpdump подтверждал отсутствие проблем с сетью, что исключало традиционные причины ухудшения производительности. Основное время простоя наблюдалось именно между пакетами с ответами и следующими запросами, что указывало на проблемы внутри клиентского слоя обработки gRPC. Попытки использовать пул каналов с одинаковыми аргументами не приводили к улучшению ситуации, так как они всё равно делили одно TCP-соединение. Лишь создание отдельных каналов с уникальными параметрами или включение специального аргумента GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL позволило устранить основное узкое место, повысив пропускную способность почти в шесть раз и снизив задержки в несколько раз.
Такие меры оказались критичными для использования gRPC при низкой сетевой задержке, когда минимальные задержки самой сети могут оказаться значительно ниже внутренних задержек в клиентском стеке. Также интересно отметить, что в условиях более высокой сетевой задержки (примерно 5 мс), описанная проблема практически исчезала, а разница в производительности между разными схемами работы клиента была минимальна. Это говорит о том, что оптимизации особенно важны именно для сверхбыстрых сетей, где даже микросекундные задержки становятся критическими. Практическое значение таких находок огромно для компаний и проектов, использующих распределённые базы данных, микросервисные архитектуры с множеством взаимодействий и высокоскоростные вычислительные кластеры. Возможность добиться реального увеличения производительности без масштабирования аппаратных ресурсов с помощью тонкой настройки клиента может существенно снизить затраты и увеличить эффективность.
Рекомендации YDB.tech по работе с клиентскими каналами gRPC легко интегрируются в практику и поддерживаются официальной документацией, что облегчает их внедрение. Помимо изменения конфигураций каналов, важно тщательно следить за распределением потоков и привязкой их к CPU, особенно в NUMA-системах, чтобы избежать дополнительных латентностей из-за переключений контекста. Несмотря на описанные успехи, разработчики сами признают, что найденные решения адресуют только часть сложностей производительности gRPC, и в будущем могут потребоваться дополнительные оптимизации. Поэтому сообщество пользователей и разработчиков гRPC остаётся открытым к обмену опытом и совместному поиску новых путей повышения эффективности.
В заключение можно подчеркнуть, что внимание к деталям реализации клиента gRPC имеет решающее значение для достижения оптимальных результатов в системах с низкой сетевой задержкой. Неожиданное узкое место, связанное с поведением каналов и мультиплексированием потоков, легко переходит незамеченным, но может существенно ограничивать масштабируемость и отзывчивость приложений. Использование подхода с множеством уникальных каналов и активация локальных пулов каналов представляют собой простой и эффективный способ обхода этой проблемы. В результате внедрения этих практик достигается значительный рост пропускной способности и снижение клиентских задержек, что позволяет раскрыть полный потенциал современных высокоскоростных сетевых инфраструктур. Для разработчиков и инженеров, работающих с распределёнными базами данных, межсервисным взаимодействием и высоконагруженными системами, понимание подобных особенностей gRPC становится залогом успешного проектирования и эксплуатации.
Исследования и рекомендации, проведённые в рамках YDB.tech, служат ценным руководством по оптимизации и вдохновляют на дальнейшие эксперименты в области улучшения сетевого взаимодействия в рамках современного бэкенда. Приглашается профессиональное сообщество обмениваться знаниями и активно участвовать в развитии открытых проектов, чтобы сделать gRPC ещё более производительным и надёжным инструментом для построения масштабируемых систем в эпоху низких задержек и больших данных.