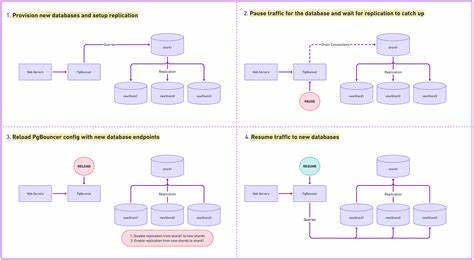
В современном мире цифровых продуктов и сервисов высокая доступность и масштабируемость баз данных остаются краеугольными камнями успешных платформ. Особенно в условиях стремительного роста трафика и объёмов данных, когда речь идёт о критических бизнес-системах, вопрос о том, как эффективно распределить нагрузку без даунтайма, становится крайне актуальным. Одним из самых востребованных решений является горизонтальное масштабирование - разделение данных между несколькими экземплярами базы данных, известное как шардинг. Однако осуществить такой переход без остановки сервиса - задача, которая требует инновационных технических решений. В этой статье мы подробно рассмотрим опыт использования примитива режима обслуживания (maintenance mode) для реализации шардинга Postgres с нулевым временем простоя на примере реального проекта.
В течение долгого времени многие платформы опирались на один экземпляр PostgreSQL, который хранил всё: от данных пользователей и конфигураций до приложений и критичных бизнес-данных. Такой подход обеспечивает простоту администрирования и достаточную производительность для начальных этапов развития. Однако при резких скачках нагрузки, таких как период акций в электронной коммерции или массовый рост пользовательской активности, вертикальное масштабирование уже не справляется - мощности сервера достигают пределов, а обновление версии СУБД становится неизбежным. Горизонтальное масштабирование с помощью шардинга решает эту проблему, позволяя распределить нагрузку по нескольким отдельным инстансам Postgres. Но традиционные методы предполагают большой и рискованный переход, когда все данные мигрируются одномоментно, что неизбежно приводит к простой, ошибкам и сбоям в работе систем.
Основной вызов - обеспечить целостность данных, избегать потери запросов и при этом не допустить ухудшения пользовательского опыта. Для преодоления этих сложностей команда разработчиков разработала и внедрила отдельный режим обслуживания - специальный механизм, позволяющий временно приостанавливать запросы к конкретным фрагментам данных без прерывания общего функционирования системы. Такой подход позволяет постепенно, плавно выполнять перенос данных и смену основных источников правды (source of truth) для отдельных пользователей или окружений. Основной концепт заключается в том, что для каждого клиента или окружения можно объявлять небольшое окно обслуживания, которое длится считанные секунды. Во время этого периода все запросы к базе для данного клиента не отвергаются и не прерываются ошибками, они просто приостанавливаются в ожидании освобождения эксклюзивного блокировочного состояния.
Это состояние приобретает процесс миграции, когда он требует полного исключительного доступа к данным для безопасного переключения источника. Важно отметить, что в обычное время политика основана на так называемых разделяемых блокировках, позволяющих множеству параллельных операций выполняться одновременно, поддерживая высокую пропускную способность и минимальную задержку. Только при переходе в режим обслуживания происходит захват блокировки эксклюзивного типа, что гарантирует атомарность и целостность критичных изменений. Техническая реализация опирается на мощный инструмент PostgreSQL - advisory locks. Это особый тип блокировок, независимых от транзакционной систем PostgreSQL, что позволяет гибко управлять состоянием доступа к данным без риска возникновения взаимных блокировок или конфликтов.
При этом наличие внутреннего механизма, концентрирующего все database connection через единый объект (например, AppWorkUnit) обеспечивает невозможность обхода этого контролируемого доступа, исключая непредсказуемое поведение приложений и поддерживая строгий контроль над доступом к данным. Шардинг реализуется поэтапно. Вначале разворачиваются новые базы данных, полностью настроенные с необходимыми схемами и мониторингом. Для переноса данных используется логическая репликация, которая отлично справляется с копированием данных на лету между разными версиями Postgres, что упрощает задачу обновления баз. Такая репликация непрерывно синхронизирует записи, позволяя держать копию базы в актуальном состоянии на новом сервере.
Переход фактически осуществляется с помощью запуска режима обслуживания для конкретного клиента. После ожидания, когда все активные транзакции завершаются, и актуализации репликации, происходит мгновенный перенос источника запросов на новую базу. Запросы, которые приходят во время этого маленького окна, просто блокируются и затем продолжают работу без потерь. Особенность этого подхода в том, что даже большой объём данных переносится не за один раз, а постепенно по отдельным приложениям и клиентам, что снижает риск возникновения сбоев, упрощает отладку и позволяет масштабировать работу пропорционально нагрузке и ресурсам. Также важным этапом были тестирования и "сухие прогоны" - имитация процесса миграции без фактического переноса данных, которая помогла выявить и устранить локальные баги и сценарии неучтённого поведения.
Наличие тысяч "тестовых" приложений, которые можно безопасно передавать между базами, обеспечило дополнительный уровень уверенности и балансировало риски реального перехода. Этот инновационный метод позволил выполнять масштабирование от одного "монолитного" экземпляра Postgres к распределённой системе без остановок и ошибок, выдерживая 400%-ный рост трафика в пиковый период. Финальные показатели показали, что максимальное окно заморозки запросов составило всего четыре секунды, а 95-й перцентиль - всего 250 миллисекунд, что является впечатляющим достижением. В итоге применение режима обслуживания как инженерного примитива стало ключевым звеном в успешном развертывании горизонтально масштабируемой платформы. Помимо обеспечения безопасности и целостности, оно позволило снизить психологический и операционный стресс от больших дигитальных трансформаций - уже никто не боится "кнопки большого взрыва", которая в одно мгновение меняет инфраструктуру.
В перспективе этот подход открывает возможности для непрерывного улучшения архитектуры, миграции на новые версии СУБД и интеграции с современными облачными сервисами с минимальным риском для бизнеса. Режим обслуживания можно переосмыслить и адаптировать для более широкого спектра задач, где нужно балансировать между непрерывностью обслуживания и необходимостью контроля критичных изменений. Для компаний, которые сталкиваются с необходимостью масштабирования Postgres, это пример того, как можно выстроить процесс смены базы данных с максимальной осторожностью, прозрачностью и минимальными потерями. Это стратегия маленьких шагов с гарантией стабильности и контролем, в разы превосходящая рискованные "молниеносные" обновления. Общий урок заключается в том, что технологические инновации в области управления БД сопровождаются вниманием к деталям обеспечения отказоустойчивости, применением проверенных средств и методологий, а также построением надежных внутренний сервисов, которые скрывают сложность от пользователя и обеспечивают безупречный опыт.
Такой подход становится шаблоном для других компаний, стремящихся к высокодоступным и масштабируемым системам в эпоху цифровой трансформации и взрывного роста данных. Инвестиции в разработку примитивов типа maintenance mode окупаются с лихвой, минимизируя риски и повышая лояльность пользователей. Следующим шагом развития этой практики можно считать автоматизацию распределения трафика и ещё более интеллектуальное управление шардами, что позволит полностью сосредоточиться на развитии продукта, а не на технических ограничениях инфраструктуры. Мир движется в сторону больших данных и непрерывных сервисов, и описанный опыт - прекрасный пример, как совмещать масштаб и качество без компромиссов. .



![Supplementary Information for the DeepSeek R1 paper [pdf]](/images/06FFC630-AA23-415C-BA38-61623D71FB01)

