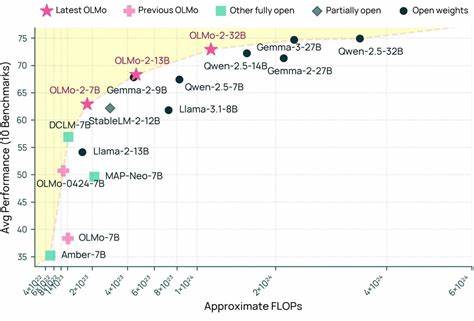
Технологии искусственного интеллекта стремительно развиваются, и одним из ключевых направлений является создание мощных языковых моделей, способных понимать, генерировать и анализировать человеческий язык с высокой точностью. В этом контексте проект OLMo 2, разработанный Институтом искусственного интеллекта Аллена (Ai2), представляет собой значительный шаг вперед. Воплощая идеалы открытости и прозрачности, OLMo 2 стала первой по-настоящему открытой моделью крупного масштаба, которая превосходит по производительности известные коммерческие решения, включая GPT-4o mini и GPT-3.5 Turbo. OLMo 2 — это не просто еще одна языковая модель.
Это комплексная семейство моделей с различными параметрами, среди которых 1B, 7B, 13B и флагманская версия 32B параметров. Каждый из этих вариантов имеет свои преимущества и нацелен на разные задачи: от локальной разработки и исследований до применения в сложных академических и прикладных сценариях. В первую очередь стоит обратить внимание на OLMo 2 32B — самую крупную и производительную модель серии, которая обучалась на массиве из шести триллионов токенов текста и прошла этап пост-тренировки на базе набора данных Tulu 3.1. Именно благодаря этому OLMo 2 32B впервые продемонстрировала способность превзойти GPT-4o mini по многим мультидисциплинарным академическим тестам.
Одним из ключевых достоинств проекта является его абсолютная открытость. В эпоху, когда многие ведущие модели остаются «закрытыми» в плане исходных весов, данных или алгоритмических нюансов обучения, OLMo 2 предлагает полную прозрачность. Исходный код для обучения, списки используемых датасетов, промежуточные чекпоинты, а также подробные технические отчеты и методологии оценки результатов доступны каждому желающему. Такая открытость поддерживает академическую среду, способствует развитию коллективных исследований и позволяет независимым специалистам воспроизводить и улучшать модельные решения. Еще один важный аспект — это сбалансированный подход к масштабированию и эффективности.
Модель 1B параметров, являющаяся младшим представителем семейства, уже превосходит своих конкурентов в этом классе, таких как Gemma 3 1B и Llama 3.2 1B, обеспечивая быструю итерацию для исследователей и делая возможным локальное тестирование и модификацию без необходимости больших вычислительных ресурсов. Модели 7B и 13B параметров, обученные на пяти триллионах токенов, конкурируют и даже превосходят сравнимые по размеру открытые модели от Meta и Mistral, что показывает высокий уровень оптимизации и качества обучения OLMo 2. В основе тренировки OLMo 2 лежат тщательно разработанные рецепты, которые учитывают всю цепочку обработки данных от предварительной тренировки до пост-тренировки с использованием специализированных датасетов. Такой подход позволяет закрепить базовые языковые навыки и одновременно адаптироваться к конкретным задачам.
Публикация этих рецептов и кода предоставляют исследователям возможность погрузиться в тонкости процесса, экспериментировать с параметрами и обеспечивать дальнейший рост моделей с открытым исходным кодом. Помимо академических успехов, OLMo 2 открывает двери для прикладных применений. Возможность интегрировать и дообучать модели с полным доступом к обучающим ресурсам и архитектуре особенно ценна для бизнеса, научных лабораторий и образовательных учреждений. Такие модели способны решать сложные задачи: от генерации текста и перевода до анализа больших объемов информации и поддержки принятия решений. Их открытый характер способствует развитию экосистемы инструментов и сервисов на основе ИИ, обеспечивая прозрачность, контролируемость и безопасность использования.
Ai2 также уделяет внимание сообществу и сотрудничеству. Для заинтересованных специалистов реализована возможность использовать и расширять высокопроизводительный тренировочный код OLMo 2, а также участвовать в обсуждениях, связанных с оценкой моделей, улучшением архитектур и практическим внедрением. Обсуждения проходят на популярных платформах, от Discord до GitHub и Hugging Face, где размещены модели и обучающие датасеты. Подводя итог, можно сказать, что OLMo 2 — это знаковый проект, который демонстрирует, что открытые модели способны соответствовать и даже превосходить современные коммерческие аналоги. Она задает новые стандарты открытости и качества, формируя фундамент для будущих исследований и разработок в области искусственного интеллекта.
Для тех, кто стремится к глубокому пониманию и практическому применению продвинутых языковых моделей, OLMo 2 предоставляет уникальные возможности и инструменты. Институт искусственного интеллекта Аллена продолжает развитие проекта, регулярно публикуя обновления и расширяя функциональность модели, что делает OLMo 2 неотъемлемой частью современного ландшафта AI-технологий.

![Cooling the London Underground: The Never-Ending Quest [video]](/images/A0DF664F-CBE3-4F3C-8B69-BEC8F3BA13AD)
![The Dinah Project [pdf]](/images/022AE19C-3043-4790-8443-3D13E79173F6)