Мир искусственного интеллекта не стоит на месте, и особое внимание в последние годы привлекают технологии синтеза речи и генерации аудиоконтента. Компания Boson AI представила вторую версию своей модели Higgs Audio Generation, которая обещает кардинально изменить подход к созданию высококачественного аудио. Эта модель не просто последовательное улучшение предыдущей версии, а настоящий технологический прорыв, который доступен теперь в открытом исходном коде и способен внедряться в самые разные области – от озвучки диалогов до создания аудиокниг и интерактивных виртуальных ассистентов. Higgs Audio V2 основана на уникальной структуре, сочетающей большие языковые модели с продвинутыми аудиотокенизаторами, и обучена на колоссальном массиве данных, превышающем 10 миллионов часов. Такой объем информации позволяет модели не только точно восстанавливать интонации человеческой речи, но и самостоятельно адаптировать эмоции и стиль в зависимости от контекста и ситуации.
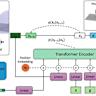
Одной из главных отличительных особенностей данной модели является способность модельного ядра одновременно оперировать с двумя типами токенов – текстовыми и аудиотокенами, что обеспечивает глубину понимания и богатство выразительных средств. Это стало возможным благодаря инновационной архитектуре Dual-FFN, которая оптимизирует обмен информацией между языковыми и звуковыми слоями. Как результат – естественно звучащие диалоги с несколькими участниками, где каждый голос воспринимается живым и эмоционально достоверным. Интересно, что Higgs Audio V2 автоматически адаптирует просодию – мелодию и ритм речи – в процессе повествования, что повышает реализм даже в длительных аудиозаписях. Это особенно ценно для тех, кто планирует использовать модель для создания аудиокниг, подкастов или других форматов контента, где важна не только точность произношения, но и стилистическая выразительность.
Качество звука в новой версии также существенно улучшено: переход с 16 кГц на 24 кГц обеспечивает чистое воспроизведение на высококлассных аудиосистемах и наушниках, усиливая эффект погружения для слушателей. Примечательно, что при всей своей мощности и сложности модель остается доступной для разработчиков с разным уровнем ресурсов. Самые легкие вариации Higgs Audio V2 смогут работать даже на энергоэффективных устройствах вроде Jetson Orin Nano, что открывает двери для интеграции в мобильные и встроенные решения. Для более продвинутых версий, требующих максимальной производительности, рекомендуется использование видеокарт уровня RTX 4090, позволяющих обрабатывать аудио практически в реальном времени с минимальными задержками. В ряде независимых тестирований и бенчмарков Higgs Audio V2 заняла лидирующие позиции.
В тестах EmergentTTS-Eval, ориентированных на эмоции и вопросы, модель показывает выигрыш более 75% по сравнению с другими современными системами, включая известный gpt-4o-mini-tts. Способность точно передавать эмоциональные оттенки и интонации делает ее идеальным инструментом для создания живых диалогов и интерактивных голосовых помощников. Отдельное внимание заслуживает мультиспикерный режим. Генерация разговора с участием нескольких персонажей всегда была сложной задачей: модели нужно не только менять голоса, но и поддерживать согласованность эмоций и динамики между ними. Higgs Audio V2 превосходит ожидания, предлагая естественное взаимодействие, в котором каждый голос имеет собственную индивидуальность и эмоциональный фон, при этом слушателю создается впечатление живого общения.
Помимо сильных технических характеристик, разработчики Boson AI выделяют социальный аспект проекта, выпустив модель в открытый доступ. Такой шаг способствует развитию сообщества, позволяя большему числу специалистов и энтузиастов в области ИИ исследовать и использовать возможности передовой голосовой генерации. Уже сейчас доступны онлайн-демо и репозитории на GitHub и HuggingFace, где можно протестировать модель, а также интегрировать ее в собственные приложения и проекты. Для тех, кто заинтересован в более индивидуальных решениях, команда компании предоставляет услуги по кастомизации и созданию специализированных моделей под конкретные задачи. Все это делает Higgs Audio V2 универсальной платформой, подходящей для самых различных сфер – от развлечений и образования до бизнеса и научных исследований.
Среди самых ярких сценариев использования модели можно выделить интерактивные голосовые помощники с реалистичными эмоциями, озвучку персонажей в видеоиграх, трансляцию диалогов с возможностью смены языка, а также автоматическую генерацию подкастов и аудиокниг с множеством говорящих. Кроме того, модель умеет одновременно синтезировать не только речь, но и музыкальное сопровождение, что открывает широкие возможности для создания атмосферных и качественных аудио произведений. Благодаря мощной автоматизированной системе аннотации данных, включающей многократное распознавание речи и классификацию звуковых событий, Higgs Audio V2 обучена на максимально разнообразных и корректно размеченных аудиоматериалах, что положительно сказывается на универсальности и адаптивности модели. Высокий уровень соответствия звучания оригиналу и минимальный уровень ошибок в восприятии текста подтверждаются результатами измерений показателей WER (Word Error Rate) и SIM (similarity), которые демонстрируют ведущие позиции по сравнению с аналогами. Сам механизм токенизации заслуживает особого внимания.
Он успешно объединяет семантические и акустические признаки, что снижает нагрузку на модель и одновременно улучшает качество воспроизведения. Благодаря этому достигается оптимальный баланс между скоростью работы и глубиной понимания контента. Использование нового уровня частоты дискретизации и продвинутого алгоритма токенизации тесно связаны с архитектурными особенностями модели, призванными сохранить как лингвистическую, так и эмоциональную информацию на максимальном уровне. Таким образом, Higgs Audio Generation версии 2 не просто инструмент для вывода речи, а полноценная языково-аудиальная система, способная не только озвучивать текст, но и формировать выразительные и эмоционально насыщенные аудиосюжеты. В заключение стоит отметить, что запуск Higgs Audio V2 в формате open source – это важный шаг к демократизации технологий синтеза речи.
Такая доступность позволит расширить инновационные горизонты, привлекая к разработкам больше талантливых специалистов и стимулируя интеграцию голосовых интерфейсов в самые разные индустрии. Учитывая достигнутые высокие показатели точности, эмоциональной выразительности и реалистичности звучания, модель заслуженно считается одной из наиболее перспективных на рынке аудиогенерации. Для пользователей это означает новые возможности создания контента, повышенную гибкость и качество, а для разработчиков – мощный инструмент для разработки продвинутых голосовых приложений. Boson AI продолжает укреплять позиции лидера в области искусственного интеллекта и звуковых технологий, демонстрируя, что будущее коммуникаций с машинами станет естественным, эмоциональным и вдохновляющим. Higgs Audio Generation версии 2 задает новый стандарт для всего рынка и открывает путь к реалистичному и живому аудио взаимодействию, близкому к человеческому.
В условиях стремительного развития мультимодальных интерфейсов и увеличения запросов на качественный голосовой контент этот проект становится ключевым игроков в индустрии, способным удовлетворить самые высокие требования пользователей и создателей.







