Kubernetes, ставший де-факто стандартом для оркестрации контейнеризованных приложений, изначально создавался для управления stateless сервисами, таких как веб-приложения и микроcервисы. Однако современный мир облачных вычислений и непрерывного развития требует управлять не только безсостояночными задачами — критически важно обеспечить надёжную работу stateful компонентов, в первую очередь таких, как базы данных. В течение многих лет управление базами данных в Kubernetes оставалось насущной и нерешённой проблемой. Тем не менее, недавние технологические прорывы демонстрируют, что Kubernetes наконец смог преодолеть этот вызов, сделав управление базами данных в контейнерах доступным, автоматизированным и масштабируемым. Суть проблемы кроется в концептуальных отличиях stateless и stateful систем.
Традиционная модель Kubernetes строится вокруг декларативного описания желаемого состояния и контроллеров, которые непрерывно проверяют фактическое состояние и приводят его в соответствие с желаемым. Это подходит идеально для замещаемых и повторяемых компонентов — например, подов, которые легко перезапустить, удалить или обновить без потери данных или состояния. Но базы данных напрямую работают с критически важными, изменяемыми данными, обладающими жизненно важной историей, которую нельзя просто «перезаписать» или потерять при обновлении. Любое некорректное действие может привести к потере данных, длительным простоям и сложным проблемам с целостностью. Повышение сложности при работе с базами данных на Kubernetes заключается в том, что базы требуют аккуратного управления жизненным циклом.
Применение устаревших подходов, таких как классические обновления контейнеров с простоем или ручное вмешательство, быстро становится неэффективным и рискованным. Ключевым примером служит апгрейд PostgreSQL — надёжный, безостановочный процесс, включающий этапы параллельного запуска новой версии, синхронизации данных с помощью логической репликации и плавного переключения нагрузки. Попытка применить к этому традиционный stateless-подход с роллаутом, где старый под остановлен и удалён, а новый под загружается на его место — отвергается экспертами как крайне опасная практика, ведущая к рискам потери информации и длительным простоям. Помимо апгрейдов, ещё более сложным становится управление изменениями схем баз данных. По мере развития приложений схемы баз часто эволюционируют, появляются новые таблицы, колонки или индексы.
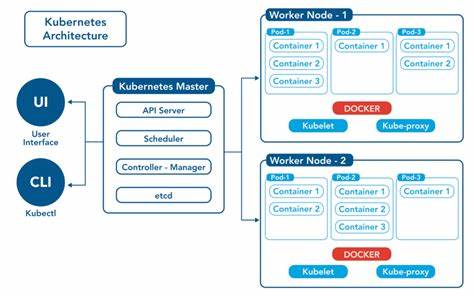
Некорректное или несогласованное внедрение миграций приводит к ошибкам в работе приложений, сбоям и даже потере данных. Традиционные методы запуска миграций через init-контейнеры, скрипты или ручные задания не интегрируются с декларативной природой Kubernetes и часто создают гонки состояний и трудности с откатом изменений. Преодолеть эти вызовы помогает паттерн Kubernetes Operator — расширение архитектуры Kubernetes, позволяющее создавать специализированные контроллеры, которые знают о внутренних особенностях управляемых систем. В случае баз данных, оператор — это программный компонент, который полностью автоматизирует процессы создания, конфигурации, масштабирования, обновления и восстановления БД, сохраняя её корректное состояние без человеческого вмешательства. Он реализует полноценные циклы реконсиляции для stateful ресурсов, как это делается для stateless приложений.
В основе оператора лежат два ключевых механизма: Custom Resource Definitions (CRD), которые добавляют в Kubernetes новые типы ресурсов, например, PostgresCluster или DatabaseSchema, и контроллеры, которые следят за состоянием этих ресурсов и выполняют необходимые операции для поддержания желаемого состояния. Такое сочетание позволяет декларативно описывать не только окружение, но и поведение самой базы данных и схем её данных, строя автоматизированные, надёжные и масштабируемые процессы управления базами в облаке. На практике решение этой задачи готово сегодня благодаря таким инструментам, как CloudNativePG и Atlas Operator. CloudNativePG представляет собой оператор промышленного класса, который заботится о поднимаемых кластерах PostgreSQL, включая настройку репликации, отказоустойчивость, создание бэкапов и восстановление. Atlas Operator дополняет эту функциональность, управляя миграциями схем баз данных через декларативный ресурс AtlasSchema.
Это позволяет вести управление схемами как кодом, полностью интегрированным в GitOps-процессы. Работа с этими инструментами начинается с установки операторов и создания кластера PostgreSQL под управлением CloudNativePG. Далее с помощью Atlas Operator можно задать SQL-схему в специальном Kubernetes-ресурсе, где оператор отслеживает изменения и автоматически применяет миграции, учитывая текущий статус базы и соблюдая политики безопасности. Такой подход устраняет ручной труд, исключает ошибки и риски, связанные с миграциями, и делает процесс полностью наблюдаемым и повторяемым. Преимущества от внедрения операторов и декларативного управления базами данных в Kubernetes очевидны.
Во-первых, это автоматизация рутинных и сложных операций, что снижает необходимость человеческого вмешательства и уменьшает вероятность ошибок. Во-вторых, устранение простоев и повышение надежности, так как операторы умеют аккуратно переключать нагрузку и управлять обновлениями без потери данных. В-третьих, интеграция управления базами в общую экосистему Kubernetes, что даёт единый источник правды, упрощает аудит и стандартизацию процессов. Кроме того, использование операторов позволяет масштабировать управление базами данных в больших и динамичных облачных средах, где количество инстансов и приложений может исчисляться сотнями и тысячами. Ручное управление при таких масштабах невозможно и неэффективно.
Операторы же, опираясь на принципы реконсиляции и автономности, поддерживают стабильность и целостность базы данных вне зависимости от изменений нагрузки, сбоев компонентов и обновления кластеров. Важно отметить, что переход к операторской модели меняет восприятие баз данных как «сложных и хрупких» компонентов, преобразуя их в обычные ресурсы инфраструктуры. Это фундаментально стирает границы между приложениями и базами данных, позволяя использовать единые подходы и инструменты для управления полным стеком облачных сервисов. В конечном итоге Kubernetes, решая проблему управления базами данных с помощью операторского паттерна, отпирает двери к созданию полностью автоматизированных, надёжных и масштабируемых облачных систем следующего поколения. Это открывает новые возможности для разработчиков, DevOps-инженеров и архитекторов систем, которые могут теперь лучше контролировать жизненный цикл баз данных, упрощать процессы разработки и эксплуатации, а также минимизировать риски и издержки.
Можно с уверенностью сказать, что операторская модель меняет правила игры, делая базы данных равноправной частью облачной экосистемы, подарив Kubernetes не просто управление приложениями, а полноценное управление состоянием всей инфраструктуры, включая критичные stateful сервисы. Таким образом, эволюция Kubernetes в сторону поддержки управления базами данных является ключевым событием для индустрии, которое позволит построить более устойчивые, гибкие и масштабируемые решения, отвечающие нуждам современного бизнеса и технологий. Будущее управления stateful сервисами теперь за автоматизацией и декларативным подходом — и Kubernetes обеспечивает этот путь.