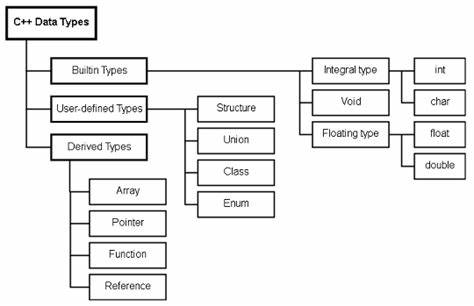
Язык программирования C++ славится своей мощностью и гибкостью, предоставляя программистам широкий спектр возможностей для работы с различными типами данных. Одним из ключевых аспектов понимания этого языка является знание таксономии типов — системы классификации, которая позволяет разобраться в природе и назначении различных типов данных, используемых в C++. В этой статье подробно рассматривается иерархия типов, начиная с фундаментальных и распространяясь до составных, с дополнительными комментариями о промежуточных категориях, таких как скалярные и арифметические типы. Понимание типов данных в C++ начинается с освоения фундаментальных типов. Эти типы представляют собой основу программирования с минимальной абстракцией.
К фундаментальным типам принято относить не только целочисленные и числа с плавающей точкой, но и специальные типы вроде void и nullptr_t. Они называются так потому, что непосредственно соответствуют простейшим единицам информации, хранящимся в памяти, и не подлежат дальнейшему разбиению на части. Целочисленные типы в C++ имеют довольно богатую структуру. Стандартная библиотека языка определяет пять основных знаковых целочисленных типов: signed char, short int, int, long int и long long int. Вместе с ними существуют и соответствующие беззнаковые варианты – unsigned char, unsigned short int, unsigned int, unsigned long int и unsigned long long int.
Благодаря такому набору программисты могут выбрать наиболее подходящий размер и диапазон значений, исходя из задач и архитектуры. Кроме этого, современные компиляторы часто предлагают собственные расширенные типы, например, __int128 и его беззнаковый аналог unsigned __int128, позволяя работать с большими числовыми значениями. Помимо числовых целочисленных типов, в категорию интегральных типов включены тип bool и различные символьные типы, такие как char, wchar_t, char8_t, char16_t, char32_t. Они реализуют хранение символов и могут иметь свои особенности, связанные с кодировками и размером памяти, занимаемой каждым символом. Несмотря на то, что эти типы также считаются целочисленными, они предназначены для специальных задач, связанных с текстовой информацией и логическими значениями.
Говоря о числах с плавающей точкой, здесь для программиста доступны стандартные типы float, double и long double. Они реализуют различные уровни точности и диапазоны значений, что позволяет использовать их в наукоемких расчетах и прикладных задачах, например, в графике или физическом моделировании. Как и для целочисленных типов, языковой стандарт допускает создание расширенных типов с повышенной точностью или размером, которые поддерживаются конкретными реализациями компиляторов. Вместе интегральные и числа с плавающей точкой образуют подмножество, называемое арифметическими типами. Эти типы служат для математических операций и вычислений, их поведение хорошо определено стандартом, что способствует предсказуемости и надежности программ.
Добавляя void — тип без значения — и специальный тип std::nullptr_t, который представляет указатель на нулевой адрес, мы получаем полный набор фундаментальных типов, с которыми работает язык на самом низком уровне. Очень важно отметить, что в литературе и среди программистов часто встречаются термины «базовые» и «встроенные» типы в контексте C++. Однако официального определения для этих понятий в стандарте нет, и они часто используются нечетко. На практике термин «базовый тип» иногда синонимичен фундаментальному, поскольку последний действительно является базовой единицей в сети типов C++. Следует избегать использования этих терминов для предотвращения путаницы и сосредоточиться на четкой иерархии, принятой в самой спецификации языка.
Но язык C++ не ограничивается лишь фундаментальными типами. Сложные структуры и механизмы требуют более разнообразных, составных типов. К ним относятся классы, объединения (unions), массивы, а также перечисления (enum), указатели и ссылки. Хотя с первого взгляда перечисления, указатели или ссылки не выглядят как типы, состоящие из нескольких элементов, они официально классифицируются как составные типы по определению языка. Термин «составной» отражает то, что такие типы либо содержат связанные данные, либо предоставляют ссылки или доступ к другим объектам, образуя таким образом более сложную структуру по сравнению с фундаментальными типами.
Особое место в классификации занимает группа скалярных типов. Это объединение, которое включает все арифметические типы, указатели, перечисления и тип std::nullptr_t. Понятие скалярного типа особенно важно для понимания модели памяти в C++. Стандарт определяет, что отдельное расположение в памяти (memory location) соответствует либо скалярному типу, либо битовому полю. Такое разделение имеет ключевое значение для понимания, как компилятор размещает, изменяет и оптимизирует данные, особенно в многопоточных приложениях и при работе с низкоуровневым кодом.
Расширение знаний о преобразованиях и правилах повышения типов, таких как integer promotions или usual arithmetic conversions, может значительно повысить качество программ и убедиться в отсутствии неожиданных ошибок. Впрочем, эти темы выходят за рамки общего обзора классификации типов и требуют отдельного обсуждения. Но уже понимание структуры таксономии типов поможет программисту грамотно подходить к выбору нужного типа, управлять памятью и успешно использовать механизмы языка. Таким образом, изучение таксономии типов в C++ раскрывает логику, заложенную в язык его разработчиками. Фундаментальные типы обеспечивают простоту и эффективность, составные — гибкость и расширяемость, а такие категории как скалярные и арифметические типы помогают четко классифицировать данные и операции.
Это знание становится основой уверенного использования C++ в разработке высокопроизводительных и сложных систем, позволяя максимально раскрыть потенциал языка и создавать качественные программные продукты.