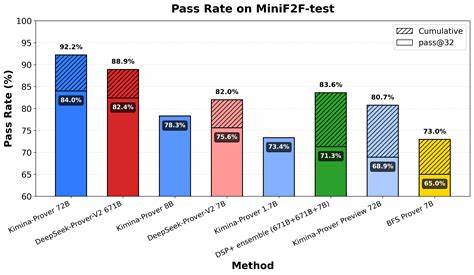
Современные технологии искусственного интеллекта стремительно меняют ландшафт научных исследований и решения сложных логических задач. Одной из самых захватывающих и перспективных областей стало автоматическое доказательство теорем, где машины учатся формально и точно воспроизводить математические рассуждения. В этом направлении особое внимание привлекает Kimina-Prover — новаторская система, демонстрирующая выдающиеся результаты благодаря использованию тестового обучения с подкреплением (Test-Time Reinforcement Learning, TTRL). Эта технология позволила достигнуть наивысшего показателя пропущенных задач в 92.2% на одном из самых популярных и сложных бенчмарков miniF2F, созданном для оценки систем формального доказательства теорем.
Kimina-Prover представляет собой модель с огромным числом параметров (72 миллиарда в версии Kimina-Prover-72B), обученную на основе мощного RL-пайплайна Kimi k1.5, построенного на базе академического языкового модели Qwen2.5-72B. Кроме того, разработчики представили две менее ресурсозатратные дистиллированные версии модели с 8 и 1.7 миллиардами параметров, что делает решение доступным для широкой аудитории исследователей и энтузиастов.
Главные достижения Kimina-Prover связаны с внедрением комплекса инновационных методик. Основным новаторством выступает система тестового обучения с подкреплением, которая задает модели агентскую рамку, позволяющую рекурсивно исследовать и комбинировать промежуточные леммы при построении сложных доказательств. Такая способность к многоступенчатому условному рассуждению и переиспользованию уже выведенных утверждений значительно расширяет возможности модели и позволяет успешно решать даже самые трудные теоремы. Отдельно стоит отметить механизм исправления ошибок, встроенный в Kimina-Prover. Он позволяет системе воспринимать сообщения об ошибках формальной среды Lean и интеллектуально подбирать исправления, а не просто генерировать доказательства заново.
Благодаря этому повышается эффективность обучения, снижается количество избыточных попыток и увеличивается надежность конечных результатов. Сравнительный анализ производительности Kimina-Prover на датасете miniF2F показывает впечатляющие успехи. Помимо лидерства по количеству успешных доказательств, модель демонстрирует последовательное превосходство в различных режимах выборок — от pass@1 до pass@1024, что подтверждает стабильность и универсальность подхода. Еще более впечатляет то, что с применением полного фреймворка тестового обучения с подкреплением удалось повысить итоговый уровень прохождения задач до 92.2%, что является рекордом среди известных моделей на сегодняшний день.
Эта система не только автоматизирует поиск доказательств, но и способна разделять сложную проблему на подзадачи через рекурсивное введение дополнительных лемм и их проверку. В процессе поиска модель создаёт до сотен вариантов комбинаций лемм, которые затем стратегически оцениваются и отбираются, что похоже на процесс, которым бы пользовался опытный математик для поиска кратчайшего пути к решению. Также применяется фильтрация специальных несовместимых или нелогичных лемм с помощью доказательства их отрицаний, что обеспечивает непротиворечивость и корректность итогового доказательства. Технология обучения включает в себя этапы генерирования формальных лемм с использованием специализированного автокодировщика для перевода естественного языка в формальные утверждения, которые предварительно встраиваются в контекст задачи. Благодаря такому подходу модель учится применять полезные промежуточные результаты и избегать ненужных, что повышает эффективность поиска и снижает затраты вычислительных ресурсов.
Одним из значимых вызовов в реализации Kimina-Prover было обучение на ошибках. Модель получила уникальную способность воспринимать синтаксические и логические ошибки, анализировать сообщения от среды Lean и вырабатывать исправления, благодаря чему она стала самосовершенствующейся. Для этого была подготовлена обширная разметка данных с примерами ошибок и соответствующих исправлений, подкрепленная среднесрочными рассуждениями. Обучение проводится с использованием метода пакетного воспроизведения неудачных попыток, что обеспечивает стабильное обучение при достаточно большой доле негативных примеров. Также в Kimina-Prover реализованы дополнительные методики, повышающие гибкость и качество модели.
Это включает селекцию и динамическую фильтрацию учебных задач, обновление состава проблем для поддержания адекватного баланса между сложностью и достижимостью решения, а также техники дополнительного обучения с разреженными промежуточными шагами — важный элемент для восполнения пропусков в человеческих доказательствах. Применение Kimina-Prover выходит далеко за рамки академического интереса. Высокоточные и эффективные решения в области автоматизированного доказательства имеют большое значение для всех, кто занимается формальными верификациями программного обеспечения, математическим моделированием и исследовательской деятельностью в инженерных и научных областях, требующих гарантированной корректности и доказуемости результатов. Кроме того, Kimina-Prover демонстрирует, как синергия современных языковых моделей, усиленного обучения и продвинутых стратегий поиска может создавать инструменты, которые не просто ускоряют людям работу с формальными системами, но и расширяют границы того, что можно автоматизировать в математике. Сегодня Kimina-Prover — это символ нового этапа эволюции нейросетевых моделей для сложных когнитивных задач.