В эпоху стремительного развития технологий и стремления компаний к максимальной эффективности обработки данных, требования к производительности систем хранения и обработки информации неуклонно растут. Один из ключевых вызовов современных IT-инфраструктур — уменьшение времени доступа к данным при одновременном увеличении пропускной способности и поддержке высокой нагрузки от множества пользователей. Curvine — это новейшее решение для распределенного кэширования, недавно открытое для сообщества разработчиков и специалистов в области больших данных. Эта система предлагает революционный взгляд на работу с данными, обеспечивая впечатляющий прирост производительности и масштабируемость при интеграции с широким спектром современных инструментов и платформ. Curvine — это облачно-нативная, высокопроизводительная распределённая кеширующая система, созданная для современных ресурсоёмких приложений, требующих интенсивной работы с распределёнными хранилищами данных.
Изначально разработанная, чтобы выступать интеллектуальным кэш-слоем между основным файловым хранилищем (UFS) и вычислительными движками, она значительно снижает задержки при чтении и ускоряет передачу данных, что особенно важно для сценариев работы с большими объёмами информации. В сравнении с традиционным доступом к облачному хранилищу Curvine демонстрирует превосходные показатели. Время чтения сокращается с сотен миллисекунд до единичных, достигая скорости ответа в диапазоне 1-10 миллисекунд, что ускоряет работу в 10-50 раз. Пропускная способность увеличивается на порядок, позволяя передавать не сотни мегабайт в секунду, а гигабайты — 1-10 ГБ/с. Количество операций ввода-вывода в секунду поднимается до миллионов, а система уверенно выдерживает десятки тысяч одновременных подключений, что в сотни раз превышает показатели классического облачного доступа.
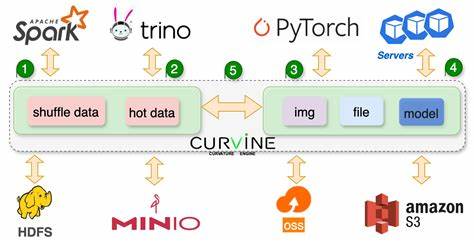
Такое улучшение является критическим для масштабируемых систем, работающих в режиме реального времени. Архитектура Curvine построена на ряде ключевых компонентов, обеспечивающих её стабильность и высокую производительность. Мастер-кластер отвечает за управление метаданными, планирование кэширования и поддержание согласованности данных. Рабочие узлы занимаются непосредственным кэшированием данных, обработкой операций ввода-вывода и выполнением задач. Многоязычный клиентский SDK поддерживает взаимодействие на Rust, Java, Python, а также через интерфейс FUSE, позволяя легко интегрировать Curvine в разнообразные экосистемы и среды разработки.
Для управления задачами предусмотрен распределённый менеджер заданий, обеспечивающий эффективное распределение нагрузки, а система метрик предлагает мониторинг в режиме реального времени, что помогает оптимизировать производительность. Основой работы с Curvine является процесс монтирования, который устанавливает связь между путями в основном хранилище и путями кэширования. Система поддерживает два режима монтирования — Consistent Path Mode (CST) для простого, понятного отображения путей, и Orchestration Mode (Arch) для более гибкого управления путями и возможности сложных трансформаций. Это позволяет подстраивать кэш под различные сценарии — от классических структурированных дата-озёр до многоуровневых многооблачных сред. Запуск кэширования происходит с помощью команды монтирования с указанием параметров, таких как время жизни кэша, политика обработки устаревших данных, количество реплик, размер блока и стратегия согласованности.
Возможность тонкой настройки позволяет оптимизировать использование ресурсов и обеспечить надёжность хранения, учитывая специфику рабочих нагрузок. Одной из важнейших особенностей Curvine являются интеллектуальные стратегии кэширования. Помимо стандартного пассивного кэширования, система поддерживает активную предзагрузку данных, которая особенно полезна для пиковых периодов нагрузки. Такая функциональность позволяет заранее подготовить критически важные данные в кэше, снижая вероятность задержек в рабочих процессах. Система распределённых заданий в Curvine превосходит многие конкурентные решения, предоставляя эффективное планирование и балансировку нагрузки.
Интеллектуальный механизм устранения дублирующейся загрузки значительно сокращает излишний трафик и экономит пространства кэша, что положительно влияет на стоимость и эффективность инфраструктуры. Обеспечение согласованности данных — одна из главных задач в любой системе кэширования. Curvine предлагает три подхода к гарантии согласованности: режим «нет согласованности» для максимально высокой производительности при работе с неизменяемыми или архивными данными, «всегда» для строгого контроля и актуальности в реальном времени и «периодический» режим, сочетающий баланс между производительностью и актуальностью. Такая гибкость даёт возможность адаптировать Curvine к самым разным бизнес-сценариям. Особое внимание Curvine уделяет интеграции с AI/ML задачами, где требования к скорости доступа к данным и их актуальности чрезвычайно высоки.
В частности, система поддерживает кэширование данных для обучения глубоких нейронных сетей, ускоряя загрузку больших датасетов на GPU-кластеры. Также обеспечивается низкая задержка при работе с моделями в продакшене, где критично быстро получать доступ к весам и входным данным для инференса. Преимуществом Curvine является поддержка POSIX-семантики через интерфейс FUSE. Это позволяет монтировать кластер как локальную файловую систему, предоставляя полностью прозрачный и привычный доступ к данным для любых приложений без необходимости модификации способов работы с файлами. Такая совместимость расширяет возможности использования Curvine, облегчая интеграцию с широким спектром современных инструментов и библиотек для машинного обучения и аналитики.
Кроме того, Curvine тесно интегрируется с огромным набором платформ и систем в сфере больших данных. Для экосистемы Hadoop предоставляется специальный файловый драйвер, позволяющий ускорять задачи MapReduce, Spark, Hive и других, при этом не нарушая привычных рабочих процессов. Конфигурация Curvine в таких системах элементарна, а преимущества становятся заметны сразу с момента запуска. Технология прозрачного прокси UFS от Curvine позволяет организовать ускоренное кэширование даже без изменения кода существующих Java-приложений. Она автоматически распознаёт запросы, направленные к смонтированным путям, и перенаправляет их на кэш, при этом обращения к не монтированным путям идут напрямую к исходному хранилищу.
Такое решение удобно для организаций, имеющих большие и сложные системы с минимальной возможностью вмешательства в исходный код. Оптимизация работы Curvine для различных типов данных ведётся с учётом их специфики. Например, для большого числа мелких файлов оптимально задать меньший размер блоков и стратегию без строгой согласованности, что минимизирует накладные расходы. Для крупных моделей или видео — увеличить размер блока и активировать строгую синхронизацию, чтобы обеспечить целостность данных и высокую производительность. Внедрение Curvine в инфраструктуру приносит важные преимущества.
Оно существенно повышает скорость доступа к данным, что напрямую влияет на эффективность вычислений и качество конечных бизнес-процессов. Помимо этого, уменьшается нагрузка на исходное хранилище и сетевые ресурсы, что позволяет снизить затраты на облачные сервисы и увеличить срок службы оборудования. Гибкая настройка обеспечивает безопасность и согласованность данных, что важно в корпоративных и критичных сценариях. Curvine — это результат современных подходов в области распределённых систем и кэширования, объединяющий лучшие практики с техническими инновациями. Завдяки открытому исходному коду проекты и компании могут не только использовать передовые алгоритмы и архитектуру, но и участвовать в развитии системы, подкрепляя её новыми идеями и улучшениями.
Для желающих быстро начать работу с Curvine доступен подробный гайд по сборке и запуску локального кластера. Система написана на современном стеке технологий и поддерживает простое построение и масштабирование как на локальных серверах, так и в облаке. Инструменты для тестирования производительности, включая измерения с помощью FIO, помогают оценить реальные преимущества Curvine в конкретных условиях. Высокая адаптивность, полная поддержка микросервисной и облачной архитектуры, широкая совместимость с инструментами для обработки больших данных и AI/ML, а также потрясающая производительность делают Curvine одним из самых перспективных решений на рынке распределённого кэширования. Для компаний, стремящихся к максимальной эффективности и экономии ресурсов, Curvine предлагает мощный инструмент для модернизации и улучшения работы с данными.
Комплексное решение Curvine открывает новую эру в организации данных, давая возможность строить системы с миллионами одновременных пользователей и обработки данных с минимальной задержкой. Все эти качества делают Curvine не просто программным продуктом, но ключевым элементом современной цифровой инфраструктуры, ориентированной на высокую производительность и гибкость.