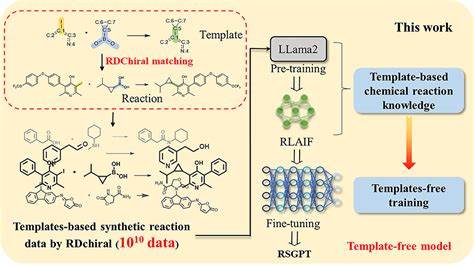
Ретросинтез — это фундаментальный процесс в органической химии, который помогает химикам планировать пути синтеза сложных молекул из доступных исходных соединений. В течение многих десятилетий успешное планирование синтетических маршрутов оставалось высококвалифицированной задачей, требующей глубоких знаний и опыта. Однако с развитием искусственного интеллекта и машинного обучения появились новые возможности для автоматизации и оптимизации этого процесса. Особенно востребованными стали подходы с применением нейросетей, способных анализировать и предсказывать реакции на основе больших массивов данных. Одним из самых перспективных достижений в этой области стала модель RSGPT — генеративный трансформер, активно трансформирующий подходы к ретросинтезу за счёт масштабного предварительного обучения и инновационных методов оптимизации.
Модель RSGPT, разработанная на основе больших языковых моделей наподобие LLaMA2, отличается тем, что была предварительно обучена на колосальном наборе данных — более 10 миллиардов реакций, синтетически сгенерированных при помощи продвинутого алгоритма RDChiral. Этот алгоритм позволяет извлекать шаблоны реакций и применять их к фрагментам молекул из огромных химических баз данных, таких как PubChem, ChEMBL и Enamine. Таким образом, удалось восполнить исторический дефицит качественных данных для обучения моделей в области ретросинтеза, который долгое время лимитировал достижение высоких показателей точности. Главная инновация RSGPT заключается в комбинировании стратегии большого языкового моделирования с особенностями химического пространства. Ранее шаблонные методы в ретросинтезе основывались на фиксированных реакционных шаблонах, что ограничивало их универсальность и масштабируемость, а методы, не зависящие от шаблонов, страдали от недостатка больших объемов данных для обучения.
В RSGPT благодаря масштабному синтетическому датасету удалось обучить модель глубоко понимать взаимосвязи между продуктами, реагентами и шаблонами реакций, не обременяя потом процесс предсказания строгими ограничениями шаблонов. Для усиления обучаемости и качественной генерации реакций применяется метод обучения с подкреплением на основе искусственной обратной связи (RLAIF). Эта техника позволяет модели получать динамическую оценку правильности и химической обоснованности предсказаний с помощью RDChiral, который проверяет, можно ли сгенерированные реагенты и шаблоны применить обратно к продукту. Такой цикл обратной связи стимулирует модель лучше выстраивать внутренние знания о химических преобразованиях и отбрасывать нерелевантные или невозможные варианты. При оценке RSGPT на признанных эталонных наборах данных, включая USPTO-50k, USPTO-MIT и USPTO-FULL, модель демонстрирует выдающиеся показатели: точность предсказания на уровне Top-1 достигает 63.
4% на наиболее популярном наборе USPTO-50k. Такие результаты значительно превосходят предыдущие достижения как в шаблонных, так и в безшаблонных методах. Высокая точность сочетается с отличным качеством генерируемых химических SMILES — более 97% сгенерированных фрагментов валидны, что критично для практического применения модели. Важно подчеркнуть, что объем и разнообразие данных сыграли решающую роль в улучшении результатов. Генерация 10 миллиардов реакций позволила охватить значительно более широкое химическое пространство, чем доступные изначально патентные базы с несколькими миллионами реакций.
Визуализация распределения химического пространства с помощью методов TMAP показывает, что сгенерированные данные покрывают новые либо редкие области, которые ранее были слабо представлены. Это особенно полезно для предсказания реакций с нестандартными фрагментами или более сложной структурой молекул. Внутренние исследования и абляционные эксперименты подтвердили, что как этап предварительного обучения на синтетическом датасете, так и последующая оптимизация с использованием RLAIF значительно повышают производительность. При отсутствии предобучения точность модели резко падает, что доказывает необходимость масштабного обучения на химических данных для освоения «правил» реакций. В то же время метод RLAIF способствует более устойчивому присвоению модели химической логики, улучшая ранжирование наиболее вероятных реакций.
Практическая ценность RSGPT проявляется также в возможности прогнозирования многошагового ретросинтеза. Модель успешно применяется для планирования сложных синтетических маршрутов важных фармацевтических соединений, таких как осимертиниб, фебуксостат и вонопразан. Несмотря на то, что RSGPT разрабатывалась для одноступенчатого ретросинтеза, составление многошаговых схем становится возможным за счет последовательного применения предсказаний для каждого промежуточного соединения. Это открывает новые горизонты для автоматизации и оптимизации синтетического дизайна в промышленной и академической химии. Тем не менее, RSGPT имеет области для развития.
Текущий метод генерации синтетических тренировочных данных ограничен реакциями, включающими не более трёх реагентов, что снижает охват некоторых видов сложных реакций. Кроме того, генерация реагентов без объяснимой химической логики остаётся вызовом, затрудняя интерпретацию результатов и принятие решений человеком-химиком. Помимо этого, модель пока не учитывает условия реакции, такие как растворители, катализаторы и температура, которые играют ключевую роль в реальных синтетических процессах. В будущем разработчики планируют совершенствовать методы создания данных, расширять химическое пространство, включать числовые параметры условий и улучшать объяснимость модели. Эти направления позволят повысить как точность предсказаний, так и применимость RSGPT в реальных лабораторных и производственных задачах.







