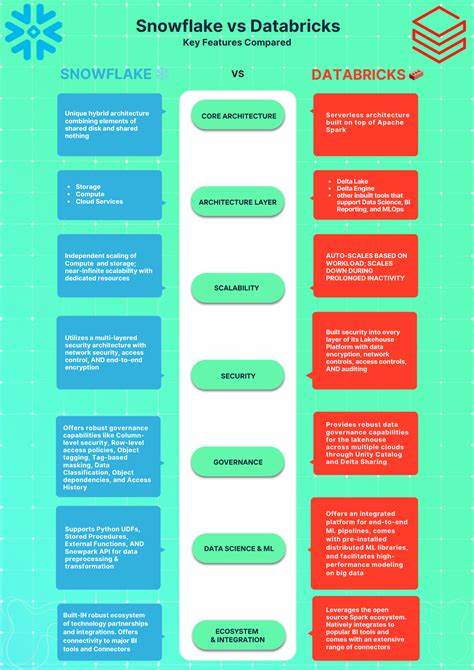
В современном мире обработки данных скорость и стоимость аналитики играют ключевую роль для эффективной работы бизнеса. Среди множества решений на рынке выделяются ClickHouse, Databricks и Snowflake, которые конкурируют за место в архитектуре корпоративной аналитики. В первой части нашего обзора мы рассмотрели первоначальные результаты работы ClickHouse на сравнительных тестах с Databricks и Snowflake, где ClickHouse продемонстрировал впечатляющую производительность и экономичность с минимальной настройкой. Во второй части разберём, как ещё больше повысить эффективность ClickHouse, используя функциональность in-memory словарей — уникальное и мощное средство для оптимизации join-запросов на больших объёмах данных. ClickHouse изначально позиционируется как система для быстрой аналитики с открытым исходным кодом и облачным сервисом ClickHouse Cloud, доступным на ведущих платформах AWS, GCP и Azure.
Одним из ключевых сценариев использования являются запросы с большим количеством соединений (join), характерные для складов данных в моделях «звезда» и «снежинка». Именно здесь на помощь приходят словари, которые позволяют преобразовать традиционные join-операции в сверхбыстрые in-memory lookup, что заметно снижает время выполнения и стоимость вычислений. Ключевая идея использования словарей в ClickHouse заключается в загрузке небольших dimension-таблиц (таких как продукты и локации) в память в виде ключ-значение. Благодаря этому поиск данных при соединении конкретных записей превращается в мгновенный доступ в памяти, избавляя от необходимости сканировать большие fact-таблицы с диска и выполнять ресурсоёмкие join-операции. Такой подход особенно эффективен при работе с факт-таблицами, насчитывающими миллиарды строк, аккуратно распределённых по облачной платформе.
Для наглядности рассмотрим benchmark из практики обработки заказов национальной сети кофеен, включающий основную fact-таблицу Sales (заказы) и dimension-таблицы Products (товары) и Locations (местоположения магазинов). В базовом варианте эти таблицы связаны стандартными join-запросами, которые уже работали быстрее и дешевле, чем в Databricks и Snowflake. Но при переходе к загрузке Products и Locations в словари с помощью ClickHouse нативных возможностей появился дополнительный значительный прирост производительности. Движок ClickHouse позволяет создавать словари из разных источников и форматов: это могут быть файлы в Parquet, JSON, Arrow, таблицы Apache Iceberg, Delta Lake или даже Kafka потоки и распределённые хранилища S3, HDFS. Такая универсальность облегчает интеграцию в существующие архитектуры и ускоряет миграции.
Для таблицы Locations создаётся словарь с хешированным ключом по названию location_id, что обеспечивает мгновенный поиск города, штата и страны по уникальному идентификатору. Для таблицы Products задействуется более сложный словарь с диапазонным поиском (range dictionary), поддерживающий поиск актуальной версии продукта по дате заказа, что крайне важно для обработки товарных версий во времени. Переписывание SQL-запросов для использования словарей минимально — традиционные join заменяются вызовами функций dictGet с передачей ключей. Такой подход упрощает переход и снижает риски ошибок, позволяя значительно ускорить аналитические вычисления без необходимости перестраивать архитектуру данных и процессы загрузки. Результаты нагрузочного тестирования говорят сами за себя.
При обработке 1,4 миллиарда строк время выполнения 17 типичных запросов сократилось почти вдвое на двух узлах кластера, что позволило снизить стоимость вычислений на 47%. При увеличении числа узлов до четырёх и восьми наблюдаются ещё более впечатляющие ускорения — до 3,5 раз быстрее и экономия выше 60%. Особенно заметный выигрыш достигается на сложных запросах с большими join-операциями и временными условиями, где словари помогают выполнять lookups с минимальными затратами по времени и ресурсам. Важно подчеркнуть, что предложенный метод не требует перезаливки данных или серьёзных изменений схем. Все словари обновляются исключительно с помощью чтения из существующих таблиц или внешних источников, что делает настройку практически бесшовной.
Такая «низкотрениевая» интеграция даёт преимущество в гибкости и скорости внедрения в продакшен-среды, что ценится как разработчиками, так и бизнес-аналитиками. Кроме того, ClickHouse поддерживает более сложные типы словарей, позволяющие искать совпадения по регулярным выражениям, классифицировать по CIDR-диапазонам IP, или выполнять геопространственные запросы. Это расширяет возможности применения технологии для задач безопасности, персонализации и мониторинга. Сравнивая ClickHouse с Databricks и Snowflake, можно заметить, что первые два решения чаще ориентированы на кластерные вычисления с использованием Spark и SQL-интерфейсов, которые в ряде кейсов не так эффективно справляются с join-операциями на огромных объёмах, особенно без дополнительной настройки и оптимизаций. Snowflake, будучи облачным сервисом типа Data Warehouse as a Service, предлагает высокую удобность, но стоимость и время выполнения запросов может быть выше при join-heavy нагрузках.
Итоговая картина такова, что ClickHouse предлагает не только быстрый старт и конкурентоспособную базовую производительность, но и возможности для глубокой оптимизации с минимальными усилиями. Использование in-memory словарей — простая, гибкая и мощная техника, позволяющая масштабировать аналитику и обрабатывать большие данные быстрее, дешевле и эффективнее. Ещё одной выгодой является то, что ClickHouse Cloud предоставляет инструменты для быстрого тестирования своих сценариев с бесплатным кредитом в $300, что стимулирует компании и специалистов попробовать решение на своих данных и убедиться в преимуществах без финансовых рисков. Подход с использованием словарей можно рекомендовать как компаниям, только строящим центральные аналитические платформы, так и тем, кто уже использует ClickHouse, но хочет вывести производительность на новый уровень. Особенно выгодно это для тех организаций, где join-запросы с dimension-таблицами занимают большую часть аналитической нагрузки и требуют быстрого времени отклика.
В заключение, ClickHouse продолжает доказывать, что не только является одним из самых производительных систем для аналитики, но и постоянно развивается, внедряя инновационные возможности и нативные оптимизации. Технология in-memory словарей — яркий пример того, как глубокое понимание архитектуры данных и возможностей СУБД позволяет добиваться прорывных результатов в работе с большими данными. Оптимизация запросов, снижение расходов и повышение скорости обработки — именно те преимущества, которые делают ClickHouse лучшим выбором для компаний, стремящихся получить максимальную отдачу от своих данных в конкурентной борьбе. Для аналитиков и инженеров данные результаты резонно заставляют обратить внимание на возможности ClickHouse и рассмотреть его как главный инструмент в портфеле решений для масштабируемой и высокопроизводительной аналитики.







