Параллелизм на уровне памяти — одна из ключевых архитектурных характеристик современных процессоров, определяющая их способность эффективно работать с памятью и обеспечивать высокую производительность приложений. В контексте ARM-процессоров Apple M2 и Apple M4, которые стали флагманами мобильных и настольных устройств компании, вопрос оптимизации работы с памятью и реализации параллелизма является особенно важным. Эти процессоры используют передовые технологии организации памяти, среди которых выделяется унифицированная архитектура памяти, что дает новые возможности для совместной работы CPU и GPU с общей областью быстрой RAM. Apple M2, вышедший в 2022 году, стал логичным развитием успешной серии чипов Apple Silicon, нацеленных на баланс между энергопотреблением и производительностью. Одной из его сильных сторон считается использование памяти LPDDR5, которая поддерживает высокую пропускную способность и низкую задержку.
Несмотря на это, в 2024 году Apple представила M4, обновленную версию своего ARM SoC, перешедшую на использование LPDDR5X — технологии с еще более высокой скоростью передачи данных и повышенной энергоэффективностью. Это нововведение обещало увеличить общую пропускную способность и улучшить работу с данными. Для оценки производительности памяти в реальных сценариях аналитики и специалисты используют специализированные тесты. Одним из наиболее показательных в данной области является benchmark, основанный на методе «pointer chasing» — прохождении циклического массива по случайно сформированным индексам. Такой подход имитирует работу при множественных обращениях к данным с низкой локальностью, часто встречающейся при работе с динамическими структурами данных, где каждый элемент указывает на следующий.
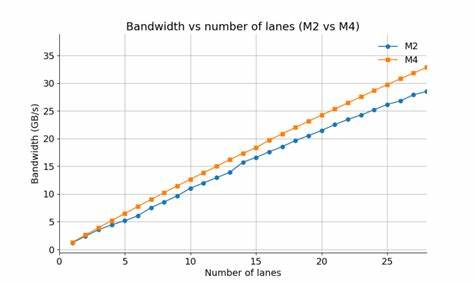
Главная сложность такого типа нагрузок — высокая задержка чтения данных из памяти, которая может составлять десятки тактов процессора. Чтобы компенсировать эту задержку, современные процессоры пытаются обрабатывать множество запросов к памяти одновременно — способность, известная как параллелизм на уровне памяти (Memory-Level Parallelism, MLP). Чем выше MLP, тем больше одновременных операций по чтению данных может выполняться, позволяя процессору эффективнее использовать доступную пропускную способность и снижая «простоя» ядра в ожидании данных. В исследовании, проведенном Дэниелом Лемиром, был разработан специальный тест, позволяющий измерить эффективность MLP у Apple M2 и Apple M4. Методика заключалась в разделении цикла случайных обращений на несколько независимых путей, или «дорожек» (lanes), которые выполнялись параллельно.
Количество таких дорожек задавалось от одной до 28, что позволяло оценить, насколько процессоры способны поддерживать большое количество одновременных запросов к памяти. Результаты теста показали интересные факты. Несмотря на технический прогресс и внедрение LPDDR5X, Apple M4 продемонстрировал лишь около 15% увеличения производительности по сравнению с M2 в контексте данного benchmark. Оба процессора смогли устойчиво обрабатывать до 28 «дорожек» параллельных запросов, что указывает на высокую степень параллелизма памяти в их архитектурах. Такая близость в показателях заставляет задуматься о том, что прирост в пропускной способности памяти не единственный и не главный фактор влияния на реальную производительность в задачах, связанных с случайным доступом к данным.
Стоит отметить, что сам подход использования «pointer chasing» предполагает далекий от идеала сценарий работы с памятью. Он создает нагрузку с низкой кэшируемостью из-за отсутствия последовательности обращений, тем самым максимально выявляя накладные расходы на ожидание данных из основной памяти. В результате реальные приложения, как правило, демонстрируют более высокие показатели, так как используют локальность доступа и оптимизации на уровне аппаратного и программного обеспечения. Кроме того, архитектура процессоров Apple обладает рядом особенностей, влияющих на эффективность работы с памятью. Обе модели используют унифицированную память, доступную как CPU, так и GPU, что снижает потребность в копировании данных и ускоряет взаимодействие между подсистемами.
При этом Apple традиционно применяет крупные страницы памяти, что уменьшает нагрузку на таблицу страниц (TLB) и снижает задержки при управлении адресным пространством. Интересно, что в обсуждениях вокруг данных тестов иногда поднимается вопрос о верхних пределах поддерживаемого параллелизма — можно ли добиться и более сотен параллельных обращений к памяти, чтобы резко повысить производительность. Ответ на это вопрос остается открытым. По мнению Дэниела Лемира, для глубокого понимания этой возможности требуется более тонкое аппаратное тестирование, возможно на уровне ассемблера с использованием специализированных счетчиков производительности процессоров. Тем не менее практика показывает, что сильно превышать уровень параллелизма, подобный 28 дорожкам, сложно из-за ограничений внутренних ресурсов процессора и контроллера памяти.
Еще одна важная особенность теста — наличие некоторого уровня шума в результатах при увеличении количества параллельных потоков. Причины таких колебаний связаны с конкуренцией за ресурсы на шинах данных, контроллерах памяти и кэш-подсистемах, а также хаотичностью распределения запросов в контроллере, что приводит к сложной статистике задержек и пропускной способности. Кроме технических реализаций параллелизма на уровне памяти, немаловажным остается архитектурный контекст Apple Silicon. Поскольку официальная документация по M4 практически недоступна, многие характеристики и тонкости реализации памяти изучаются путем реверс-инженерии и анализа производительности с помощью сторонних инструментов. Тем не менее уже известно, что в основе процессора заложена мощная архитектура с несколькими уровнями кэширования, эффективным контроллером памяти и программируемыми системами управления доступом, с учетом требований мобильных и настольных устройств.
Сравнение Apple M2 и Apple M4 с точки зрения памяти показывает, что инновации в области оперативной памяти и увеличение пропускной способности хоть и влияют на производительность, но не являются единственной движущей силой улучшения. Важны также архитектурные оптимизации на уровне контроллера памяти, кэширования и возможностей поддержки параллельных операций. Кроме того, на практике оценка производительности должна учитывать специфику приложений. В задачах с высокой локальностью данных и последовательным доступом преимущество увеличенной пропускной способности может быть более заметным. В сценариях с активно случайными обращениями, как показал тест pointer chasing, преимущества становятся менее выраженными и выравниваются особенностями реализации параллелизма.
В заключение можно отметить, что подход, предложенный для оценки MLP, является эффективным инструментом для понимания работы памяти и прогнозирования производительности в реальных условиях нагрузки, связанных с большими объемами данных и динамическими структурами. Apple M2 и Apple M4 демонстрируют передовой уровень обработки параллельных запросов к памяти, а сравнительно небольшой прирост в M4 указывает на то, что дальнейшее повышение производительности памяти будет требовать комплексных решений и оптимизаций на всех уровнях архитектуры процессора и памяти. Понимание и измерение параллелизма на уровне памяти крайне важно для разработчиков программного обеспечения, системных инженеров и архитекторов процессоров, поскольку именно от этих показателей во многом зависит скорость работы современного оборудования и эффективность обработки данных. Тенденции развития, продемонстрированные Apple, указывают на постепенное сдвижение в сторону более интеллектуальной организации памяти и надежной поддержки множества параллельных операций, что должно стать ключевым фактором в следующем поколении мобильных и персональных вычислительных систем.







