Параллельное программирование сегодня является неотъемлемой частью разработки высокопроизводительных вычислительных систем и глубинного машинного обучения. Современные вычислительные задачи требуют значительных ресурсов, и классический подход к ускорению через увеличение тактовой частоты процессоров давно исчерпал себя из-за физических ограничений. В результате индустрия перешла к масштабированию в горизонтальном направлении и активному использованию параллелизма на разных уровнях архитектуры процессоров и в языках программирования. Исторически увеличение производительности вычислительных систем происходило за счёт повышения тактовой частоты и уменьшения размера транзисторов, что позволяло располагать большее количество элементов на чипе. Закон Мура описывал этот процесс, предсказывая удвоение плотности транзисторов примерно каждые два года.
Однако к середине 2000-х годов физические ограничения — теплоотдача, сложность производства и составляющие себестоимости — остановили рост производительности за счет увеличения частоты. В такой ситуации производители переключились на увеличение количества ядер в процессоре, давая возможность выполнять множество задач параллельно. Появление многоядерных процессоров открыло новые горизонты для параллельных вычислений. Вместо одной сверхбыстрой вычислительной единицы на одном чипе стало появляться множество менее быстрых ядер, способных работать одновременно. Например, в современных процессорах Apple M1 Pro насчитывается 8 ядер, а у высокопроизводительных серверных процессоров, таких как Intel Xeon, их может быть свыше сотни.
Теоретически это даёт масштабируемость на порядок равную количеству ядер, но в реальности эффективность параллелизма ограничена из-за накладных расходов на управление, синхронизацию и коммуникацию между потоками. В области параллелизма в программировании выделяют несколько основных форм. Одним из самых распространённых является параллелизм по данным (data parallelism), при котором одни и те же операции выполняются параллельно над разными элементами данных. Например, добавление двух массивов поэлементно одновременно ускоряется, если части массива обрабатываются несколькими потоками или ядрами. Другой вид — параллелизм по модели (model parallelism), когда одна большая модель разбивается на части и разные части выполняются одновременно на разных устройствах.
Такая техника часто востребована в задачах машинного обучения, когда модель слишком велика для одного устройства. Наконец, pipeline-параллелизм предполагает разбиение вычисления на стадии, которые обрабатываются последовательно, но в конвейерном режиме, так чтобы разные стадии обрабатывали разные партии данных одновременно — это позволяет улучшить пропускную способность системы. Кроме масштабирования за счет количества ядер, важным направлением является внутриядрный параллелизм, реализующийся в виде SIMD-инструкций (Single Instruction, Multiple Data). Современные процессоры имеют специализированные векторные регистры, позволяющие одной инструкцией одновременно обрабатывать сразу несколько элементов данных. Например, 128-битные векторные регистры ARM NEON могут одновременно содержать четыре 32-битных целых числа, и операция сложения выполнит сложение всех четырёх пар чисел за одно обращение.
Это существенно ускоряет обработку больших объёмов данных. Программирование с использованием SIMD традиционно сопровождается применением специальных функций — интринсиков, которые позволяют напрямую управлять такими инструкциями. Есть и автоматическое векторизование компиляторами, когда они самостоятельно распознают подходящие циклы и заменяют скалярные операции на векторные инструкции. Однако автоматизация далеко не всегда гарантирована, и в высокопроизводительном коде часто всё равно требуется явное программирование SIMD-инструкций для достижения максимальной эффективности. Обладая многими ядрами, процессоры используют потоки выполнения (threads).
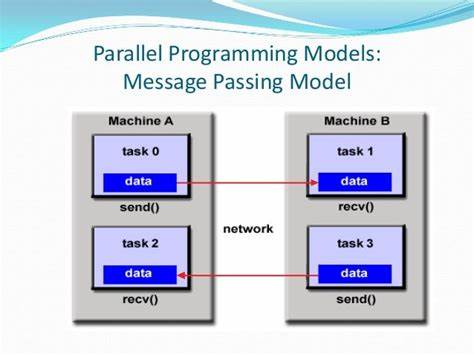
Потоки позволяют распараллеливать задачи в пределах одного процесса, деля ресурсы памяти, но одновременно выполняясь на разных ядрах. Однако создание потоков — затратная операция, особенно если их слишком много. Неправильный подход, когда для каждой мелкой задачи создаётся отдельный поток, приводит к катастрофическим потерям на управление и переключение контекста. Правильной стратегией является создание количества потоков, сопоставимого с количеством физических ядер, и разбиение задачи на достаточно крупные части, которые каждый поток обрабатывает последовательно и с применением векторизации. При разработке параллельных программ крайне важно избегать так называемого ложного шаринга (false sharing) — ситуации, когда разные потоки одновременно изменяют разные данные, размещённые на одной и той же строке кэша.
Из-за особенностей работы кэш-памяти это вызывает постоянное «пинг-понг» кэш-линий между ядрами, существенно замедляя выполнение программы. Для предотвращения ложного шаринга практикуют выравнивание и разнесение данных, чтобы отдельные переменные, активно изменяемые разными потоками, попадали в разные кэш-линии. Наряду с CPU в области параллельных вычислений огромную роль играют графические процессоры (GPU). Архитектура GPU заточена под исполнение огромного количества нитей (во многом упрощённых ядер) параллельно, что подходит для обработки высоко параллельных задач, например, в глубоком обучении. В GPU применяется модель SIMT (Single Instruction, Multiple Threads), где группы нитей («warps» на NVIDIA) выполняют одну и ту же инструкцию одновременно.
При этом любое отклонение в ходе работы нитей одной группы, например, условное ветвление, приводит к последовательному исполнению diverged путей, что снижает производительность, поэтому важна минимизация ветвлений в коде GPU. Для разработки эффективных GPU-приложений традиционно используется CUDA от NVIDIA или более универсальный OpenCL. Однако написание эффективных CUDA-программ сопряжено с высокой сложностью и необходимостью детально управлять аппаратными особенностями. Современный подход — использование доменно-специфичных языков программирования и фреймворков, например Triton. Triton — язык, встроенный в Python, который позволяет писать GPU-ядра декларативно и упрощает параллельное программирование на GPU, при этом генерируя оптимизированный низкоуровневый код.
Он поддерживает автоматическое разбиение задач на блоки, векториальное выполнение и маскирование для обработки граничных данных. Возврат к языковым решениям в области параллелизма показывает, что текущий статус — это бессистемное добавление параллельных конструкций к изначально последовательным языкам. Из-за этого программисты должны переключать ментальные модели между обычным и параллельным кодом, что усложняет разработку и поддержку. Направлением будущего можно считать создание языков, в которых параллелизм является природной частью модели программирования. Одним из таких проектов является Mojo — язык, создаваемый с учётом параллельности и производительности.
Он использует инфраструктуру MLIR, обеспечивая переносимость и генерацию оптимизированного кода для разных платформ. В Mojo встроена поддержка SIMD, отличное разграничение типов памяти между CPU и GPU, а также синтаксис, который интегрирует параллельные и асинхронные конструкции в язык на фундаментальном уровне. Это позволяет писать высокопроизводительные параллельные программы, практически не заботясь о низкоуровневых деталях параллелизма. Эволюция параллельного программирования демонстрирует движение от множества разрозненных инструментов и библиотек к объединённым языковым и компиляторным решениям, способным обеспечить масштабируемость и портируемость. Это особенно важно в эпоху быстрого развития приложений глубокого обучения и искусственного интеллекта, где эффективное решение задач требует максимально полного использования вычислительных ресурсов современных систем, будь то CPU с их потоками и SIMD, или GPU с десятками тысяч одновременно работающих ядер.
Таким образом, освоение и применение различных моделей параллельного программирования — ключевой навык для специалистов в области высокопроизводительных вычислений и машинного обучения. Будущее за теми технологиями, которые сделают параллелизм прозрачным, удобным и эффективным, позволяя сконцентрироваться на решении задач, а не на технических сложностях реализации.