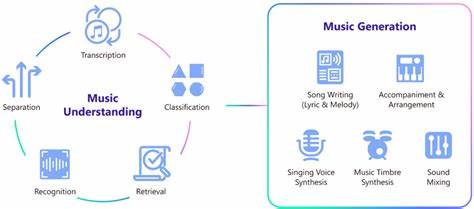
Генерация музыки с помощью искусственного интеллекта становится неотъемлемой частью современного музыкального ландшафта. В последние годы наблюдается активное развитие моделей, способных создавать композиции на основе текстовых запросов и мелодических паттернов. Однако существующие подходы имеют свои ограничения, связанные с компромиссами между скоростью генерации, структурной целостностью и уровнем контроля над итоговым результатом. Модель ACE-Step призвана изменить этот статус-кво, задавая новый стандарт для фундамента музыкального ИИ. Технологии создания музыки на базе ИИ долгое время сталкивались с дилеммами выбора между качеством и производительностью.
Например, модели, построенные на базе больших языковых моделей, такие как Yue или SongGen, демонстрируют превосходное синхронизирование текста с музыкой, но страдают от медленного времени вывода и артефактов в структуре композиции. С другой стороны, диффузионные модели, включая DiffRhythm, позволяют значительно ускорить процесс синтеза музыки, но зачастую уступают в плане долгосрочной музыкальной целостности и сложности гармонических переходов. ACE-Step предлагает инновационное архитектурное решение, объединяющее сильные стороны обеих категорий. В её основе лежит комбинация диффузионного подхода к генерации с использованием специализированного автокодировщика глубокого сжатия Sana's Deep Compression AutoEncoder (DCAE) и легковесного линейного трансформера. Такой симбиоз позволяет синтезировать музыкальные произведения продолжительностью до четырёх минут всего за 20 секунд на GPU типа A100.
Это примерно в 15 раз быстрее многих LLM-ориентированных аналогов, сохраняя при этом высокий уровень однородности звучания и точности лирического сопровождения. Для обеспечения семантической согласованности и более быстрого схода модели в процессе обучения применяются технологии MERT и мультилингвальный m-hubert, отвечающие за выравнивание семантических представлений (REPA). Благодаря этому ACE-Step овладевает тонкими нюансами естественного языка и музыкальной выразительности, что особенно важно при создании вокальных партий и голосовых сэмплов с текстом. Важной особенностью ACE-Step является сохранение детальных акустических характеристик, что открывает доступ к сложным инструментам управления. Среди них – клонирование голоса, редактирование текста песен, ремикширование и создание отдельных треков, таких как lyric2vocal (преобразование текста в вокал) и singing2accompaniment (создание аккомпанемента на основе вокала).
Это не просто генерация музыки, а полноценный креативный инструмент, превращающий процесс создания музыкального произведения в интуитивно понятный и гибкий опыт для художников и продюсеров. Что выделяет ACE-Step среди ряда остальных проектов, так это амбициозная философия создания универсального фундамента для музыкального ИИ, а не ограниченного специализирующегося на одном конкретном конвейере текст-в-музыку. Подобно тому, как Stable Diffusion революционизировал создание изображений, ACE-Step стремится стать стандартом, на котором можно строить разнообразные музыкальные приложения и инструменты, интегрирующиеся в рабочие процессы артистов и творцов. Разнообразие стилей и жанров, поддерживаемых ACE-Step, поражает. Модель способна создавать композиции в жанрах электронной музыки, рока, попа, фанка, соула, рэпа, регги, джаза, классики, а также поддерживает множественные языки, включая английский, китайский, русский, испанский и многие другие.
Эта многоязычность расширяет границы имплементации, позволяя артистам со всего мира использовать инструмент для создания аутентичных произведений с текстами на родном языке. Модель одновременно решает проблемы длины генерируемой музыки, предлагая гибкое управление продолжительностью, что является серьёзным прорывом по сравнению с традиционными диффузионными моделями, которые часто остаются фиксированной длины, либо языковыми моделями, которые испытывают сложности с контролем длительности. Уникальные функции по генерации вариаций и возможности частичного перегенерирования (repaint) позволяют артистам экспериментировать, создавая различные версии с похожим стилем и настроением, либо тонко настраивать отдельные сегменты трека. Это значительно расширяет творческую свободу и сокращает временные затраты на доработку материала. Технология редактирования текста (flow-edit), встроенная в ACE-Step, помогает производить локальные модификации лирики без изменения мелодии, вокальной тембровой окраски или фонового музыкального сопровождения.
Это дает возможность быстро тестировать и корректировать текст, сохраняя музыкальную основу неизменной, что весьма важно для музыкальных продюсеров и авторов песен. Помимо основных возможностей генерации, ACE-Step предлагает специализированные адаптированные модели, такими как Lyric2Vocal, позволяющую напрямую создавать вокальные демо из текста, Text2Samples — для генерации музыкальных семплов и лупов, а также RapMachine, специализированный инструмент для создания рэп-композиций. Эти расширения делают ACE-Step мощным инструментарем для профессиональной работы в музыкальной индустрии. Естественно, несмотря на значительные достижения, модель продолжает развиваться и имеет определенные ограничения. Например, выход зависит от начальных рандомных параметров, что иногда может приводить к результатам с вариативным качеством.
Кроме того, для некоторых жанров, таких как традиционный китайский рэп, наблюдаются определённые слабости в стилистическом соответствии и музыкальном качестве. В аспекте продолжительных трансформаций возможны переходные артефакты, а вокальный синтез ещё не имеет высокой детализации, что становится приоритетом для будущих улучшений. В целом, ACE-Step представляет собой мощный шаг вперёд в создании универсальных и эффективных моделей для генерации музыки. Ее последовательное сочетание производительности, качества и контроля открывает новые горизонты для творческих профессионалов и любителей, предоставляя инструменты, которые способны изменить традиционные методы написания и производства музыки. Развитие подобных проектов будет активно влиять на музыкальную индустрию, снижая барьеры для входа и позволяя создавать уникальные произведения с минимальными временными и финансовыми затратами.
В будущем такие модели, как ACE-Step, могут стать основой для создания интерактивных музыкальных приложений, виртуальных продюсеров и даже интеграции с платформами виртуальной реальности. Для пользователей и разработчиков это значит, что возможности для создания качественной музыки с помощью искусственного интеллекта становятся всё более доступными, а процесс творчества — более захватывающим и разнообразным. ACE-Step — это не просто технологический прорыв, но и приглашение к новой эпохе музыкального искусства, где человек и машина работают в гармонии для создания новых звуков и историй.