В последние годы искусственный интеллект прочно вошел в нашу жизнь, открывая новые горизонты для анализа данных и создания инновационных приложений. Одним из самых захватывающих направлений в этой области является использование генеративного ИИ для создания синтетических данных. Эти инструменты позволяют генерировать данные, которые имитируют реальный мир, решая при этом множество проблем, связанных с конфиденциальностью и стоимостью сбора данных. В этой статье мы рассмотрим 20 инструментариев генеративного ИИ, которые помогают в создании синтетических данных. Первым на нашем списке является инструмент Mostly.
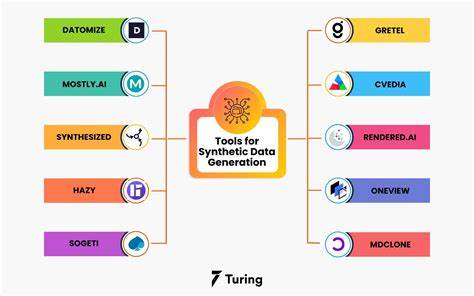
Это платформа для синтетических данных, которая признана одним из лучших решений на рынке. Mostly фокусируется на создании данных, которые соблюдают требования законодательства о защите данных, таких как GDPR и CCPA. Уникальной особенностью данного инструмента является его интуитивно понятный интерфейс, который позволяет пользователям задавать вопросы и получать данные в формате, схожем с общением с чат-ботом. Среди других его преимуществ — наличие механизмов, защищающих от предвзятости при создании синтетических данных. Следующий на очереди — Gretel.
Этот инструмент можно использовать для создания табличных, неструктурированных и временных данных в любом аналитическом или машинном обучении. Gretel предназначен для широкой аудитории, предлагая простой интерфейс, который не требует серьезных навыков программирования. Кроме того, он поддерживает множество интеграций и подключений к облачным сервисам, что делает его совместимым с большинством инфраструктур данных. Для тех, кто работает в области здравоохранения, существует Synthea — бесплатный и открытый инструмент, созданный для генерации синтетических пациентов. Он позволяет создавать полные медицинские записи пациентов, которые не существуют, но могут помочь в решении различных медицинских задач.
Это решение позволяет исследователям работать с данными, не беспокоясь о конфиденциальности и этических вопросах, связанных с использованием реальных данных пациентов. Платформа Tonic представляет собой комплексное решение для создания реалистичных, безопасных и соответствующих требованиям синтетических данных. Она ориентирована на разработку программного обеспечения и ИИ и помимо генерации синтетических данных предлагает анонимизацию реальных данных. Tonic может быть развернут как на локальных серверах, так и в облачных средах, что обеспечивает его гибкость и удобство использования. Для разработчиков, использующих Python или JavaScript, хорошим вариантом является библиотека Faker.
Этот инструмент позволяет создавать фиктивные данные, которые можно использовать для тренировки различных моделей, от рекомендательных систем до алгоритмов выявления мошенничества. Несмотря на необходимость базового знания программирования, Faker остается популярным выбором среди разработчиков. Кроме этих пяти инструментов, существует еще множество решений, которые могут быть полезны в создании синтетических данных. Например, Broadcom CTA Test Manager позволяет создавать очень технические и сложные наборы данных, а BizData X упрощает маскировку данных и анонимизацию с использованием синтетической генерации данных для бизнеса. Cvedia предлагает возможности компьютерного зрения и видеоаналитики с помощью синтетических данных, что делает его идеальным для автоматизированных решений.
Datomize обеспечивает создание наборов данных с динамическими инструментами проверки, которые помогают сделать данные максимально реалистичными. Edgecase предоставляет сервис по созданию маркированных синтетических данных, а GenRocket предлагает динамическую генерацию данных с возможностью масштабирования для корпоративных пользователей. Hazy, в свою очередь, стала первым в мире рынком синтетических данных, что открывает новые возможности для исследователей и разработчиков. K2View фокусируется на генерации данных для обучения моделей машинного обучения, тогда как KopiKat предлагает безкодовое решение для увеличения данных, направленное на повышение конфиденциальности и улучшение производительности нейронных сетей. MDClone ориентирован на синтетические данные для профессионалов в области здравоохранения, а Simerse предлагает генератор синтетических обучающих данных для приложений компьютерного зрения.
Sogeti, называемый "усилителем данных", имитирует реальные наборы данных, подбирая их характеристики и корреляции на основе существующих данных. Synthetic Data Vault — это открытая платформа машинного обучения для генерации объемных синтетических данных, а Syntho предоставляет инструменты самообслуживания для получения инсайтов и принятия решений. Наконец, YData предлагает автоматизированную генерацию синтетических данных, что позволяет повысить продуктивность и улучшить эффективность моделей ИИ. Генеративные инструменты ИИ для создания синтетических данных представляют собой мощный инструмент для современных компаний и исследователей. Они не только упрощают процесс получения данных, но и помогают обойти многие проблемы, связанные с конфиденциальностью и юридическими аспектами сбора данных.
Синтетические данные могут быть использованы в самых различных сферах — от здравоохранения до финансов и телекоммуникаций. Эти технологии открывают двери для инноваций и позволяют предпринимателям и ученым сосредоточиться на анализе и разработке, а не на рутинной работе по сбору данных. Напряженные изменения в области данных и ИТ создают интересные перспективы для будущего. В отличие от традиционного подхода к анализу данных, где основное внимание уделяется сбору и обработке реальных данных, использование генеративного ИИ позволяет менять парадигму на более гибкую и эффективную. Ожидается, что применение синтетических данных в будущем будет только расти, что сделает эти инструменты важной частью профессии исследователя данных и разработчика.
В заключение, инструменты генеративного ИИ для создания синтетических данных не только помогают решить актуальные проблемы с конфиденциальностью, но и открывают новые возможности для анализа и инноваций. Независимо от отрасли, в которой вы работаете, есть подходящие решения, которые позволят вам оптимизировать процессы и повысить эффективность работы с данными. Интерес к этому направлению продолжает расти, и в будущем мы можем ожидать появления еще более продвинутых технологий генерации синтетических данных.