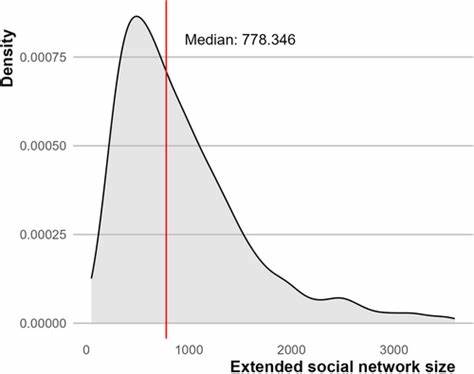
Современный мир машинного обучения стремительно развивается благодаря успехам глубинного обучения. Несмотря на революционные достижения, многие аспекты функционирования нейросетей остаются сложными для понимания. В научном сообществе активно ведутся дискуссии о природе и внутреннем устройстве моделей глубокого обучения, что особенно актуально для исследований по объяснению работы алгоритмов и достижению их interpretability. Интересный и глубокий взгляд на этот вопрос предлагает исследование, проведённое Педро Домингосом, в котором доказывается, что любая модель, обученная с помощью стандартного градиентного спуска, по сути, является приближённой ядровой машиной. Это утверждение существенно меняет представления о фундаментальных основах глубокого обучения и открывает новые перспективы для развития методов искусственного интеллекта.
Ядровые методы машинного обучения известны уже несколько десятков лет и основываются на использовании функции ядра — меры сходства между объектами данных. Ядровая машина не пытается извлекать признаки напрямую, а работает через сопоставление с тренировочными примерами в высокоразмерном пространстве, что упрощает задачу классификации или регрессии. В отличие от глубоких нейросетей с их сложной архитектурой, ядровые машины традиционно воспринимаются как подход, требующий ручной настройки признаков и моделей, ориентированных на воспоминание и обобщение данных. Однако открытие Домингоса показывает, что между глубокими нейросетями и ядровыми методами нет столь резкой границы. Модели, обучения которых происходят с применением градиентного спуска, в действительности работают примерно как ядровые машины.
Это означает, что веса нейросети образуют суперпозицию тренировочных примеров, используя архитектуру сети для формирования специфической функции ядра, которая кодирует знания о целевой функции. Таким образом, глубокая сеть одновременно повторяет и трансформирует тренировочные данные, действуя как сложный и адаптивный измеритель сходства. Такое понимание раскрывает несколько важных аспектов. Во-первых, это объясняет, почему глубокие модели способны так эффективно обучаться без необходимости руками задавать признаки: архитектура сети и процесс обучения через градиентный спуск автоматически создают ядро, которое подходит именно для поставленной задачи. Во-вторых, это приближает нейросетевые модели к более классическим и теоретически изученным методам ядрового машинного обучения, что позволяет применять к ним богатый инструментарий анализа и теории.
Существуют важные последствия для практики. Во-первых, осознание роли ядровой природы моделей может способствовать разработке новых техник обучения и регуляризации. В частности, можно будет целенаправленно оптимизировать функции ядра, внедрять новые архитектурные решения или методы инициализации весов, основываясь на ядровой интерпретации. Это открывает возможности создавать более эффективные и интерпретируемые модели, а также облегчит понимание того, как и почему модели работают. Во-вторых, это способствует углублению интерпретации моделей.
Градиентный спуск традиционно воспринимался как сложный и нелинейный процесс, затрудняющий анализ и объяснение внутренней работы модели. Подход же, связывающий обучение с ядровыми машинами, позволяет представить веса как «образцы» или комбинации входных данных, что делает результаты обучения более наглядными и понятными для исследователей и практиков. Теоретически, такое объединение знаний из разных направлений машинного обучения позволит создать более универсальные методы, сочетающие в себе сильные стороны и глубоких нейронных сетей, и методов ядрового обучения. Также это уменьшит разрыв между классическими и современными подходами, предоставляя единый язык для описания и анализа. Важно отметить, что доказательства и выводы Домингоса основаны на значимом математическом аппарате, включающем анализ функции потерь, динамику градиентного спуска и свойства высокоразмерных пространств признаков.