![Making sense of SRE and observability, one week at a time. [audio]](/images/BD5220F3-DAA4-4310-B2FE-1D9663E2122C)
Современные IT-системы становятся все более сложными, масштабируемыми и критичными для бизнеса, что поднимает на порядок важность их надежности и эффективности. В этом контексте концепции Site Reliability Engineering (SRE) и наблюдаемости приобретают фундаментальное значение для обеспечения стабильной работы приложений и сервисов. Однако, несмотря на широкое распространение этих терминов, многие организации испытывают трудности с их правильным пониманием и внедрением. Рассмотрим основные аспекты этих концепций и почему осознание их роли необходимо для современных компаний. Site Reliability Engineering (SRE) - это методология, объединяющая разработку программного обеспечения и эксплуатацию систем, цель которой заключается в создании надежных, масштабируемых и удобных для пользователей сервисов.
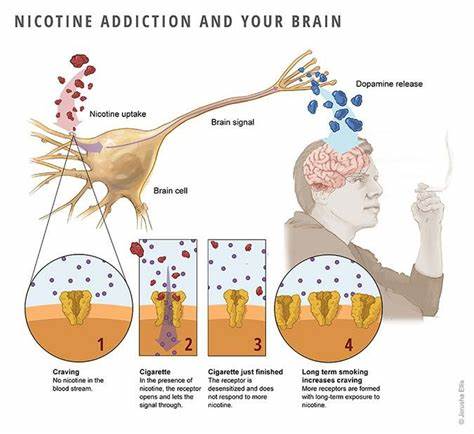
SRE выходит за рамки традиционного управления ИТ-инфраструктурой, фокусируясь на измеримых показателях надежности, автоматизации рутинных задач и проактивном предотвращении инцидентов. Такой подход позволяет не только сократить время простоя приложений, но и оптимизировать ресурсы, направляя усилия команды на наиболее ценные и действенные процессы. Ключевым элементом SRE являются сервисные уровни (service level objectives, SLO), которые определяют желаемые параметры работы системы, такие как доступность и производительность. Команда SRE внимательно отслеживает достижение этих показателей, используя соответствующие метрики (SLA и SLI) и при необходимости вмешивается для исправления возможных отклонений и проблем. Такой подход позволяет структурировать рабочий процесс и избегать хаотичных реакций на неожиданные ситуации.
Наблюдаемость (observability) - это способность систем предоставлять глубокое, понятное и актуальное представление о своем состоянии и поведении. В отличие от традиционного мониторинга, который чаще ограничивается сбором отдельных метрик и оповещений, наблюдаемость стремится к комплексному пониманию причинно-следственных связей и позволяет быстро выявлять корневые причины проблем. Это достигается путем сбора, обработки и анализа разнородных данных, таких как логи, метрики и распределённые трассы. В условиях современной разработки и эксплуатации приложений наблюдаемость становится связующим звеном между командами разработки, эксплуатации, безопасности и бизнес-аналитики. Она позволяет создавать прозрачные и поддающиеся анализу системы, что в конечном счете ведет к более быстрому обнаружению и устранению проблем, снижению риска бизнес-потерь и улучшению пользовательского опыта.
Объединение принципов SRE и наблюдаемости дает компании конкурентное преимущество за счет повышения устойчивости и предсказуемости работы сервисов. Вне зависимости от масштаба организации, понимание и внедрение этих подходов способствует улучшению коммуникации между отделами, упрощает управление инцидентами и ускоряет инновации. Интересно отметить, что современная эра искусственного интеллекта и автоматизации вносит новые возможности и вызовы в сферу SRE и наблюдаемости. Искусственный интеллект способен помочь в аналитике огромных объемов данных, выявлять аномалии и предлагать решения, позволяя инженерам сосредоточиться на более сложных и творческих задачах. Однако важно не переоценивать возможности AI и сохранять необходимый контроль, чтобы не создавать лишнее давление на технические команды и не допускать ошибок в интерпретации данных.
Обучение и постоянное развитие сотрудников в области SRE и наблюдаемости - еще один критически важный аспект успешной практики. Поскольку технологии и методы работы постоянно меняются, важно создавать культуру обмена знаниями и открытости, где вопросы и обсуждения приветствуются, а сложные концепции доходчиво объясняются. Такой подход позволяет не только повысить уровень компетенций команды, но и формирует доверие как внутри коллектива, так и среди клиентов. Рассматривая практические примеры из подкастов и интервью с ведущими экспертами, можно отметить разнообразие тем и сфер применения SRE. От управления инцидентами и создания платформенных команд до внедрения OpenTelemetry и анализа причинно-следственных связей - спектр вопросов обширен, и каждая организация может найти для себя полезные инсайты.
Кроме того, многие обсуждения подчеркивают важность сбалансированного подхода, предостерегая от чрезмерного увлечения технологическими модами и забывания о главной цели - обеспечении стабильного и качественного сервиса для пользователей. Важным трендом также является развитие наблюдаемости на всех этапах жизненного цикла приложения, включая разработку, тестирование и эксплуатацию. Такой полный охват помогает выявлять проблемы на раннем этапе, снизить время реакции и ускорить выпуск новых функций без ущерба надежности. В заключение, интеграция практик SRE и эффективной наблюдаемости становится краеугольным камнем успешного цифрового бизнеса. Компании, понимающие и применяющие эти концепции, получают возможность оперативно адаптироваться к изменениям, минимизировать риски и создавать сервисы, которые регулярно удовлетворяют или даже превосходят ожидания пользователей.
В эпоху постоянных технологических трансформаций и растущей конкуренции вопрос обеспечения надежности и прозрачности систем остается первоочередным, делая SRE и наблюдаемость необходимыми инструментами для каждого IT-проекта. .