В последние годы большие языковые модели (Large Language Models, LLM) стали неотъемлемой частью многочисленных приложений в области искусственного интеллекта, включая обработку естественного языка, генерацию текста и анализ данных. Однако повышения точности и масштабности таких моделей обычно сопровождаются значительным увеличением требований к вычислительным ресурсам и памяти, что затрудняет их внедрение на устройствах с ограниченными ресурсами и ускоряет работу в реальном времени. В связи с этим актуальными стали методы сжатия и оптимизации, среди которых квантование является одним из самых популярных и эффективных способов уменьшения объема модели и ускорения вывода без существенной потери качества. Квантование в свою очередь сталкивается с рядом вызовов, особенно при переходе на низкобитовые форматы, например 4-битное квантование, которое позволяет значительно сократить объем необходимой памяти, но часто приводит к снижению точности модели из-за некорректного представления широчайшего диапазона значений активаций и весов. Одной из ключевых проблем здесь являются экстремальные проявления активаций, так называемые «всплески» или аутлайеры, которые из-за своей высокой величины ставят под угрозу эффективность квантования.
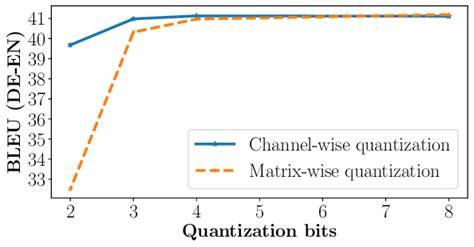
В стандартном подходе к квантованию масштабирование применяется равномерно на все каналы, что не всегда позволяет адекватно справиться с различиями в распределении данных между ними. Новым значительным шагом в решении этой задачи стала разработка SmoothRot — подхода, предлагающего сочетать масштабирование по каналам с операциями вращения с использованием матриц Адамара (Hadamard transformations). Это позволяет преобразовывать экстремальные значения активаций, делая их более пригодными для низкобитового квантования и таким образом значительно улучшая точность квантованной модели без увеличения задержек в процессе вывода. Традиционные методы масштабирования по каналам обычно нацелены на равномерное уменьшение диапазона значений, что во многих случаях не устраняет проблему аутлайеров. Аутлайеры, которые не только искажают распределение значений, но и существенно ухудшают качество квантования, становятся причиной потери точности при переходе от высокоточных форматов типа FP16 к более компактным.
Операции вращения, особенно с использованием матриц Адамара, обеспечивают эффективный способ перераспределения информации между каналами, что снижает напряжённость отдельных экстремальных значений и уравновешивает статистику активаций. SmoothRot совмещает эти два элемента — масштабирование по каналам и трансформации вращения — предлагая структуру, в которой выходы слоёв модели проходят сначала через адаптивное масштабирование, чтобы нормализовать значения внутри каналов, а затем подвергаются Hadamard-преобразованиям. Это перераспределяет характеристики активаций таким образом, что аутлайеры становятся менее выраженными, что существенно облегчает квантование. При этом сохраняется важная структурная информация, что позволяет не терять точность при переводе модели в 4-битный формат. Результаты экспериментов с использованием SmoothRot на таких популярных архитектурах, как LLaMA2 7B, LLaMA3.
1 8B и Mistral 7B, продемонстрировали устойчивое повышение производительности. В сравнении с традиционными методами 4-битного квантования новый подход показал сокращение разрыва между квантованными и полноточными FP16-моделями примерно на 10-30% по задачам генерации языка и нулевого обучения (zero-shot reasoning). При этом SmoothRot не вызывает дополнительных задержек при выводе, что говорит о его практической ценности для реальных приложений. Применение SmoothRot становится особенно актуальным на этапе пост-тренировочного квантования, когда необходимо быстро и безопасно адаптировать уже обученную модель под более компактный формат, не требуя при этом дорогих процедур переобучения или тонкой настройки с нуля. Новый метод предоставляет простой и эффективный способ борьбы с аутлайерами и оптимизации распределения данных внутри каналов, помогая улучшить качество квантования без сложных инструментов и повышенных вычислительных затрат.
Важной особенностью SmoothRot является его универсальность — метод успешно применяется к различным архитектурам LLM, что позволяет считать его перспективным для масштабного внедрения в индустрии. А благодаря открытости кода и доступности реализации, SmoothRot может быстро стать стандартом в области оптимизации и сжатия больших языковых моделей. В свете растущей популярности LLM, их все более широкого распространения и необходимости поддержки высокопроизводительных моделей на устройствах с ограниченными ресурсами, SmoothRot демонстрирует инновационный и практичный подход. Благодаря сочетанию масштабирования по каналам и вращения он открывает новые возможности для повышения точности и эффективности квантования, что в конечном итоге способствует развитию искусственного интеллекта и улучшению пользовательских сервисов. Подводя итог, можно отметить, что SmoothRot представляет собой значительный шаг вперед в области квантования больших языковых моделей.
Он сочетает техническую изысканность с практической применимостью, помогая справляться с одной из главных проблем — экстремальными значениями активаций — и максимизировать преимущества 4-битного квантования. Этот подход создает условия для более широкого распространения LLM и повышения их производительности в разнообразных средах, что положительно сказывается на всей экосистеме ИИ. Будущее развитие данной методики, возможно, будет связано с интеграцией с другими техниками оптимизации, такими как сжатие и прунинг, а также с развитием адаптивных стратегий квантования, что позволит еще больше повысить гибкость и эффективность моделей. Несмотря на текущие успешные результаты, SmoothRot открывает путь для дальнейших исследований и усовершенствований методов сжатия и ускорения больших языковых моделей, отвечая насущным потребностям современного ИИ-сообщества.