Современные искусственные интеллектуальные системы на базе больших языковых моделей (LLM) кардинально меняют наше восприятие возможностей автоматизации и взаимодействия с машинами. С каждым годом эти агенты приобретают все большую универсальность, способны выполнять широкий спектр задач и интегрируются в различные сферы жизни. Однако расширение их функционала сопровождается ростом угроз безопасности, одной из которых становятся так называемые инъекции запросов, или prompt injection attacks. Эта угроза является особенно серьезной, когда ИИ-агенты имеют доступ к инструментам или обрабатывают конфиденциальные данные. Именно поэтому сегодня важнейшим аспектом разработки таких систем выступает создание надежных паттернов проектирования, позволяющих эффективно защищать ИИ-агентов от подобных атак.
Прежде чем рассмотреть конкретные подходы, необходимо понять суть prompt injection и почему они вызывают опасения. Инъекция запроса – это метод, при котором злоумышленник вводит в текстовый ввод, предназначенный для модели, специально сформированный запрос, способный изменить поведение агента. Например, ИИ может быть заверен выполнять определенную задачу, но если пользователь подаст «вредоносный» запрос, он нарушит сценарий, заставив систему выполнять нежелательные действия или раскрывать конфиденциальную информацию. Одним из ключевых отличий подобных атак является то, что они используют естественный язык как канал влияния, что затрудняет их выявление традиционными способами защиты, основанными на фильтрации или верификации входных данных. Поэтому возникает необходимость в архитектурном подходе, то есть дизайне систем, уже на этапе их проектирования учитывающем подобные угрозы.
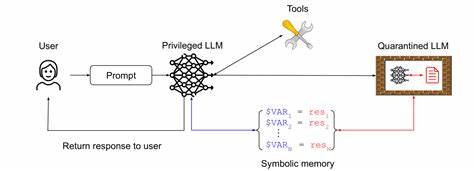
В последние годы исследователи и разработчики предложили ряд паттернов, которые позволяют создавать ИИ-агентов с гарантированной устойчивостью к инъекциям запросов. Эти паттерны включают в себя несколько взаимодополняющих стратегий. Важным элементом выступает изоляция и минимизация доверия к пользовательскому вводу. Это значит, что данные, поступающие от пользователя, не должны напрямую влиять на внутренние инструкции агента или команды, передаваемые инструментам. Вместо этого ввод пользователя тщательно анализируется, фильтруется и при необходимости преобразуется в формат, безопасный для обработки.
Такой подход позволяет снизить риск, когда вредоносный текст может изменять намерения или логику работы бота. Еще один паттерн связан с четким разделением ролей и уровней прав доступа в архитектуре агента. Интерфейсы, через которые ИИ взаимодействует с внешними системами, должны обладать ограниченным набором возможностей и жесткими контрольно-пропускными механизмами. Например, если бот имеет доступ к выполнению команд или работе с файлами, эти действия должны сопровождаться многослойной проверкой того, что именно выполняется и кто за это отвечает. Такой механизм сводит к минимуму вероятность непреднамеренного запуска потенциально опасных операций.
Важным аспектом является также использование шаблонов фиксированных инструкций (prompt templates), где основной контекст, роль и цели агента задаются жестко фиксированными текстовыми блоками, а пользовательский ввод вставляется в строго отведенное место. Благодаря этому снижается возможность того, что ввод нарушит структуру или логику инструкций, что является частой причиной атак. Помимо этого, резервное копирование логики и независимые уровни проверки получают все большее распространение. К примеру, некоторые системы используют несколько итераций обработки пользовательского запроса с промежуточной валидацией результата перед окончательным исполнением. Это позволяет на ранних этапах идентифицировать аномалии или несоответствия, создавая дополнительный барьер безопасности.
Практическое применение указанных паттернов доказывает их эффективность и помогает выработать баланс между удобством взаимодействия и необходимыми мерами защиты. В реальных кейсах видно, что агентам, у которых права доступа распределены и структурированы, а взаимодействие с пользователем тщательно контролируется через шаблоны и промежуточные проверки, удается избежать множества классических ошибок и уязвимостей. Однако безусловно, любые меры безопасности обладают своими компромиссами. Более строгая изоляция и проверка могут снизить скорость обработки запросов или создать неудобства для конечного пользователя. В связи с этим разработчикам важно учитывать, что обеспечение безопасности должно быть взвешенным и адаптированным под конкретные задачи и контекст применения.
Тогда как некоторые приложения требуют максимальной защиты, другие могут допускать определенный уровень риска ради гибкости. Современная практика показывает, что защита от инъекций запросов становится ключевым фактором доверия к ИИ-агентам. По мере роста интеграции LLM в критичные сферы — медицинские системы, финансовые услуги, госсектор — требование надёжной безопасности выходит на первое место. Комплексный подход, базирующийся на паттернах проектирования, позволяет не только минимизировать уязвимости, но и создает стандарты, которые помогут индустрии выстроить осмысленную и долгосрочную защиту систем следующего поколения. В перспективе дальнейшее развитие будет направлено на автоматизацию проверок, обучение моделей с учетом атак и развитие специализированных протоколов взаимодействия.
Все это позволит создавать агенты, которые не только умны и полезны, но и надежны с точки зрения безопасности. В заключение стоит отметить, что успех в борьбе с инъекциями запросов зависит от комплексного понимания природы угроз и системного подхода к проектированию ИИ-агентов. Использование проверенных паттернов поможет создать устойчивые, безопасные и эффективные системы, способные реализовать потенциал больших языковых моделей без риска для пользователей и окружающей инфраструктуры. Безопасность — это не просто дополнительная функция, а неотъемлемая часть инженерии современного искусственного интеллекта.