Оптимизация производительности баз данных всегда была одной из главных задач современных инженеров и разработчиков. Особенно в сфере обработки больших объёмов логов, где каждый запрос может обрабатывать миллионы и даже миллиарды строк данных. Одним из популярных решений для аналитической работы с большими данными является ClickHouse — колоночная СУБД, ориентированная на быстрый и эффективный аналитику. Несмотря на мощность ClickHouse, при работе с распределёнными логами из различных источников и сред возникла сложность, которую нам удалось решить с помощью инновационного подхода, ускорив запросы на 99,5% — практически в 200 раз! В данной статье рассказывается о нашем опыте внедрения уникального метода с использованием «ресурсного отпечатка» (resource fingerprint), который помог реорганизовать хранение данных и значительно снивелировать затраты ввода-вывода и задержки при запросах в ClickHouse. Основная проблема, с которой мы столкнулись, заключалась в смешивании логов из различных источников в одном хранилище данных.
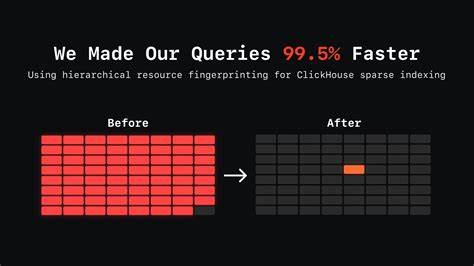
Логи поступали из разных Kubernetes-подов, сервисов и окружений — продакшен, стейджинг, девелопмент и других. В результате каждая единица хранения, называемая в ClickHouse блоком или гранулой (granule), содержала данные из различных пространств имён и ресурсов одновременно. При выполнении запросов, например, с фильтром по конкретному namespace (пространство имён), ClickHouse не мог пропустить блоки без проверки, так как они потенциально содержали релевантную информацию. Это приводило к тому, что при запросе по конкретному пространству имён база читала до 99,5% всех блоков данных, то есть почти весь объём — что катастрофически ударяло по производительности и увеличивало нагрузку на систему. Для понимания нашего решения важно разобраться с архитектурой хранения данных в ClickHouse.
Эта СУБД хранит данные в виде столбцов и группирует строки в блочные структуры, называемые гранулами. По умолчанию каждая гранула содержит около 8 тысяч строк, и при выполнении запросов ClickHouse решает, какие блоки нужно читать, а какие можно пропустить. Для оптимизации используется разрежённый индекс по первичному ключу — это не индекс по каждой строке, а по верхним и нижним границам каждого блока, что позволяет быстро определять, содержит ли блок релевантные данные. Важнейшим элементом является порядок сортировки данных, заданный запросом ORDER BY при создании таблицы. Именно он определяет физический порядок хранения данных и, следовательно, какие блоки впоследствии можно пропускать при фильтрации по ключам.
Также применяются вторичные индексы, например, фильтры Блума (bloom filter), которые создают дополнительные возможности для пропуска блока, если указанные в индексах значения отсутствуют. Однако в нашем случае некоторые дополнительные индексы не справлялись с задачей, поскольку метаданные ресурсов, такие как кластеры, namespaces и имена подов, не использовались для организации физического расположения данных, и информация о логах с разными значениями распределялась по блокам хаотично. Исходя из этой особенности, мы приняли решение изменить физический порядок данных так, чтобы логи, относящиеся к одному и тому же ресурсу (например, одному Kubernetes поду), сохранялись в хранилище рядом друг с другом. Для этого была реализована концепция ресурсного отпечатка. Суть метода заключается в агрегации ключевых ресурсных атрибутов — кластера, пространства имён, имени пода и аналогичных параметров — в единую хеш-сумму или fingerprint, которая служит уникальным идентификатором логов из одного источника.
Создание такого fingerprint позволило нам внедрить его в определение первичного ключа таблиц в ClickHouse. В ORDER BY теперь первым параметром шёл ресурсный отпечаток, что гарантировало, что все логи с одинаковым fingerprint будут физически находиться рядом на диске. Следующий этап — сортировка по временным меткам и другим менее значимым параметрам — сохранялась. Такая переорганизация обеспечила, что при выполнении запросов с фильтрами по namespace или другим ресурсным признакам система сможет быстро определить, какие гранулы содержат нужные данные, и пропустить остальные без чтения. В практическом измерении результаты были впечатляющими.
До внедрения ресурсного отпечатка при запросе с фильтром namespace: production анализировалось более 41 тысячи блоков из примерно 41,6 тысячи — около 99,5%. После изменения порядка сортировки и организации хранения списывалось уже всего около 222 блоков из 26 тысяч — то есть менее 1%. Фактически объём сканируемых данных сократился более чем в 180 раз, что резко ускорило время отклика запросов и снизило нагрузку на систему дискового ввода-вывода. Важным аспектом интеграции fingerprint стало то, что она сохранила совместимость со старой схемой и существующими запросами. При этом алгоритм отпечатка оказался адаптивным и универсальным — он работает не только с Kubernetes, но и с другими средами и платформами, такими как Docker-контейнеры или Amazon CloudWatch.
Для каждой среды определяются свои ключевые атрибуты ресурсов, которые агрегируются в единый fingerprint. В итоге метод масштабируем и подходит для гибридных и гетерогенных инфраструктур. Кроме того, принцип нашего подхода базируется на идее группировки данных с учётом реальных шаблонов доступа к информации. В отличие от энергоёмкой модели, когда сортировка и индексирование использовались по временным меткам или случайным полям, теперь первичное индексирование строится на основании того, по каким параметрам чаще всего ставятся фильтры — а именно по ресурсам логирования. Этот опыт иллюстрирует важность глубокого понимания физической организации хранения данных, которая часто оказывает решающее влияние на производительность.
Сложнейшие алгоритмы и дополнительные индексы могут оказаться малоэффективными, если сами данные организованы неразумно. Оптимизация на уровне архитектуры схемы и порядка хранения способна создать невероятные выигрышные эффекты с минимальными дополнительными затратами. За время эксплуатации оптимизации мы убедились, что подход с ресурсным отпечатком стабильно проявляет себя на практике, снижая задержки и экономя ресурсы кластера. Результаты вдохновили нас и других специалистов использовать подобные методы для повышения производительности систем обработки и аналитики логов с большим объёмом данных. Таким образом, наш кейс с ClickHouse доказывает, что инновации в организации хранения логов и грамотная сортировка данных на уровне самого СУБД способствуют значительному приросту производительности.
Опыт показывает, что стоит внимательно проанализировать шаблоны запросов, чтобы влиять на физический порядок записей и сделать систему максимально эффективной, а не просто полагаться на стандартные индексы. Такой подход открывает новые горизонты для работы с большими данными и утилитами мониторинга, делая их более отзывчивыми и масштабируемыми в современных условиях высоких нагрузок.







